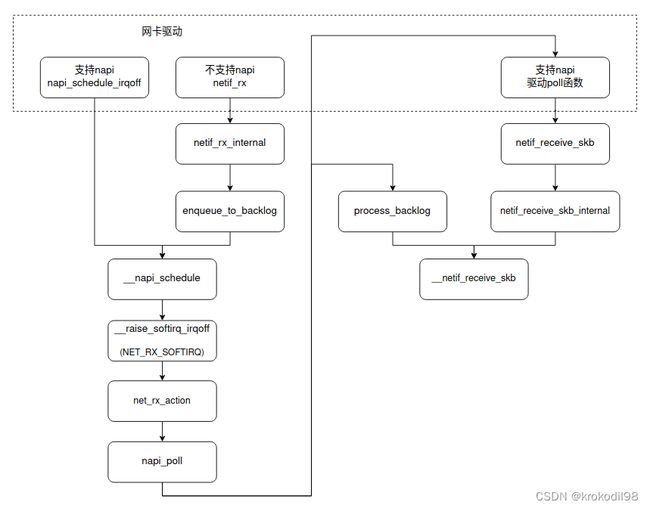
linux内核协议栈接收数据流程(一)
linux网络接收数据第一站——网卡驱动
linux网络接收数据流程的第一站为网卡驱动,网卡接收包流程大致为:
网卡硬件接收到包,会将数据包通过DMA映射到预先分配好的ringbuffer内存环形缓存中,紧接着使用硬中断告知cpu新数据包的到来(初始化时用request_irq注册中断服务函数)。cpu触发软中断,唤醒ksoftirqd进程来处理新数据包,调用驱动注册的中断处理函数,进入中断处理下半部分,中断处理函数最终会将skb递交到协议栈内。
为优化网卡接收数据效率,内核提供了NAPI接口。NAPI是软中断轮询方式+硬中断方式的结合体技术。
正常收包是硬中断方式,即收到数据包后,网卡会触发中断,在中断处理函数里会关闭中断来处理数据。若此时有新数据包到达,网卡将不再触发中断,因支持NAPI的网卡中断处理函数会轮询缓存队列,直到没有未处理数据包时才打开中断,如此设计能避免网卡在大吞吐的情况下频繁中断从而节省cpu资源。中断处理分上下部,上半部在关闭中断的情况下进行,而下半部在打开中断的情况下进行,故NAPI的处理逻辑在关闭中断情况下进行,位于中断上半部。
因此,网卡驱动接收数据包流程分为支持/不支持NAPI两种。
支持NAPI模式的网卡驱动
支持NAPI模式的网卡驱动程序将包传递给协议栈的函数接口为napi_schedule_irqoff(&驱动定义的napi_struct),函数定义如下:
static inline void napi_schedule_irqoff(struct napi_struct *n)
{
if (napi_schedule_prep(n))//判断当前napi_struct是否已调度,如果未调度,进入下方流程触发它调度
__napi_schedule_irqoff(n);
}
__napi_schedule_irqoff函数定义如下:
void __napi_schedule_irqoff(struct napi_struct *n)
{
____napi_schedule(this_cpu_ptr(&softnet_data), n);//函数____napi_schedule唤醒目标CPU来处理 backlog流程
}
EXPORT_SYMBOL(__napi_schedule_irqoff);
____napi_schedule函数为是否支持NAPI模式的函数流程的交接起始点,支持NAPI模式网卡驱动的调用路径在____napi_schedule这步之后与不支持NAPI模式网卡驱动的调用路径基本一致,只有到了调用poll函数之后才不一致,详见后文。____napi_schedule后续的操作流程见下方讲解,此处略过。
不支持NAPI模式的网卡驱动
不支持NAPI的网卡驱动程序将包传递给协议栈的函数接口为netif_rx。
int netif_rx(struct sk_buff *skb)
{
int ret;
trace_netif_rx_entry(skb);//调试ftrace功能相关
ret = netif_rx_internal(skb);
trace_netif_rx_exit(ret);//调试ftrace功能相关
return ret;
}
EXPORT_SYMBOL(netif_rx);
netif_rx->netif_rx_internal:
static int netif_rx_internal(struct sk_buff *skb)
{
int ret;
net_timestamp_check(netdev_tstamp_prequeue, skb);
trace_netif_rx(skb);
if (static_branch_unlikely(&generic_xdp_needed_key)) { //内核对XDP功能的支持,值默认为FALSE
//generic_xdp_needed_key定义为:static DEFINE_STATIC_KEY_FALSE(generic_xdp_needed_key);
... ...
}
#ifdef CONFIG_RPS // RPS: Receive Packet Steering功能,详见下
if (static_key_false(&rps_needed)) {
... ...
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);//入队backlog
rcu_read_unlock();
preempt_enable();
} else
#endif
{
unsigned int qtail;
ret = enqueue_to_backlog(skb, get_cpu(), &qtail);//入队backlog
put_cpu();
}
return ret;
}
如上方代码所述,skb入队到了backlog队列。这里的backlog不是tcp的backlog,而是cpu的backlog。
网卡驱动递交给协议栈前,会先选择一个cpu(默认是当前进程所在cpu),然后存放到该cpu的backlog队列。
backlog队列位于每个cpu的softnet_data结构体里,backlog在net_dev_init时被创建初始化:
static int __init net_dev_init(void)
{
... ...
for_each_possible_cpu(i) {//遍历每个cpu
struct work_struct *flush = per_cpu_ptr(&flush_works, i);
struct softnet_data *sd = &per_cpu(softnet_data, i);//每个cpu都有softnet_data结构体
INIT_WORK(flush, flush_backlog);
skb_queue_head_init(&sd->input_pkt_queue);//用于存放从网卡驱动接收的数据包,enqueue_to_backlog函数内skb入队的位置,若input_pkt_queue满了skb会被丢弃,通过net.core.netdev_max_backlog修改大小
skb_queue_head_init(&sd->process_queue);//后面会遇到,后文介绍
#ifdef CONFIG_XFRM_OFFLOAD//XFRM功能相关
skb_queue_head_init(&sd->xfrm_backlog);
#endif
INIT_LIST_HEAD(&sd->poll_list);//挂的是napi_struct对象
sd->output_queue_tailp = &sd->output_queue;
#ifdef CONFIG_RPS//RPS功能相关
sd->csd.func = rps_trigger_softirq;
sd->csd.info = sd;
sd->cpu = i;
#endif
init_gro_hash(&sd->backlog);//初始化napi_struct的gro_hash成员
sd->backlog.poll = process_backlog;//设置napi_struct的poll函数是process_backlog,如果网卡驱动不支持NAPI,则poll数据包时会调用此函数
sd->backlog.weight = weight_p;//当前napi_struct的权重,通过proc/sys/net/core/dev_weight可修改值
}
... ...
}
softnet_data结构体定义
/*
* Incoming packets are placed on per-CPU queues
*/
struct softnet_data {
struct list_head poll_list;
struct sk_buff_head process_queue;
/* stats */
unsigned int processed;//记录已处理的网络数据包数量的变量,通过cat /proc/net/softnet_stat可查看,通过__this_cpu_inc统计已处理的包数
unsigned int time_squeeze;//记录退出net_rx_action循环次数的变量,通过cat /proc/net/softnet_stat可查看
unsigned int received_rps;//记录CPU被唤醒收包次数的变量,通过cat /proc/net/softnet_stat可查看
#ifdef CONFIG_RPS
... ...
#endif
#ifdef CONFIG_NET_FLOW_LIMIT
... ...
#endif
struct Qdisc *output_queue;
struct Qdisc **output_queue_tailp;
struct sk_buff *completion_queue;
#ifdef CONFIG_XFRM_OFFLOAD
... ...
#endif
#ifdef CONFIG_RPS
... ...
#endif
unsigned int dropped;//记录状态的变量,通过cat /proc/net/softnet_stat可查看
struct sk_buff_head input_pkt_queue;
struct napi_struct backlog;
};
softnet_data的状态值可通过cat /proc/softnet_data查看。
cat /proc/softnet_data结果的显示是由函数softnet_seq_show实现的,函数内容如下:
static int softnet_seq_show(struct seq_file *seq, void *v)
{
struct softnet_data *sd = v;
unsigned int flow_limit_count = 0;
#ifdef CONFIG_NET_FLOW_LIMIT
struct sd_flow_limit *fl;
rcu_read_lock();
fl = rcu_dereference(sd->flow_limit);
if (fl)
flow_limit_count = fl->count;
rcu_read_unlock();
#endif
seq_printf(seq,
"%08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x\n",
sd->processed, sd->dropped, sd->time_squeeze, 0,//这里每个cpu输出的11个值
0, 0, 0, 0, /* was fastroute */
0, /* was cpu_collision */
sd->received_rps, flow_limit_count);
return 0;
}
cat /proc/softnet_data指令输出显示:
root@test-FTF:~# cat /proc/net/softnet_stat
00020771 00000000 000003f7 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 //0号cpu数据
000011b4 00000000 00000010 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 //1号cpu数据
00000e6c 00000000 00000016 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 //2号cpu数据
00000f3f 00000000 00000010 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 //3号cpu数据
root@test-FTF:~#
在继续跟踪代码之前,先补充下两个网络技术:RSS与RPS
RSS: Receive Side Scaling
RSS是网卡的硬件特性,实现了现代网卡的多队列模式,能够用多个队列发送和接收报文(ethtool -L 网口名 combined n设置多队列数为n,ethtool -l 网口名查看当前多队列配置,也可通过ls /sys/class/net/网口名/queues/查看具体有多少rx、tx队列)。
多队列网卡在接收时,会将不同数据包传递到不同的backlog队列从而实现多个CPU并行处理数据包的目的。RSS能将不同队列的硬中断平衡到多个cpu上,实现负载均衡,避免出现某个核占用拉满而其他核空闲的状态。
默认情况下,每个cpu核对应一个RSS队列(以太网队列)。由网卡硬件计算出数据包所处网络流的四元组(SIP,SPORT,DIP,SPORT)hash值(硬件实现),根据hash值网卡会将某条网络流(四元组)上的数据包固定分配给某个cpu处理。每条网络流中的数据包都被导向不同backlog接收队列,然后由不同CPU处理。
RPS:Receive Packet Steering
RPS是RSS的一个软件逻辑实现,实现了软中断分发功能。如果网卡是单队列网卡,RPS会将软中断负载均衡到每个cpu。网卡驱动会对每个网络流四元组(SIP,SPORT,DIP,SPORT)计算hash值(软件实现),中断处理时根据hash值将数据包分配到不同cpu上的backlog里。RPS是软件模拟网卡多队列功能,如果网卡本身支持多队列功能,那么RPS不会做多余操作。
继续分析代码
netif_rx->netif_rx_internal->enqueue_to_backlog
static int enqueue_to_backlog(struct sk_buff *skb, int cpu,
unsigned int *qtail)
{
struct softnet_data *sd;//上文已分析
unsigned long flags;
unsigned int qlen;
sd = &per_cpu(softnet_data, cpu); //拿到当前所在cpu对应的softnet_data对象
local_irq_save(flags);
rps_lock(sd);
if (!netif_running(skb->dev))
goto drop;
/*
static inline bool netif_running(const struct net_device *dev){//确认下是否当前网络dev状态正常
return test_bit(__LINK_STATE_START, &dev->state);
}
*/
qlen = skb_queue_len(&sd->input_pkt_queue);
if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) {
if (qlen) {//如果队列不为空,则说明sd->backlog已经挂到了sd->poll_list上,直接将skb入队即可。
enqueue:
__skb_queue_tail(&sd->input_pkt_queue, skb);
input_queue_tail_incr_save(sd, qtail);
rps_unlock(sd);
local_irq_restore(flags);
return NET_RX_SUCCESS;
}
/* Schedule NAPI for backlog device
* We can use non atomic operation since we own the queue lock
*/
if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) {//NAPI_STATE_SCHED表示该napi_struct有报文需要接收。此处只有backlog尚未被调度才可进下方流程,并会将其设置为NAPI_STATE_SCHED。若状态已被设置说明此napi已处于调度中,等待poll处理即可
//注:把napi_struct挂到softnet_data时要设置该状态,处理完从softnet_data上摘除该napi_struct时要清除该状态。
//函数__test_and_set_bit,将*addr 的第nr位设置成1,并返回原来这一位的值
if (!rps_ipi_queued(sd))//函数见下方,如果不打开RPS功能就直接返回0。如果未开启rps功能或开启rps功能且目的cpu等于当前cpu时,才进到下方逻辑,才会通过____napi_schedule触发软中断
____napi_schedule(sd, &sd->backlog);//添加到sd->poll_list中以便进行轮询,通过__napi_schedule唤醒目标CPU来处理 backlog 逻辑。
}
goto enqueue;
}
drop:
sd->dropped++;//backlog队列已满,需丢弃skb
rps_unlock(sd);
local_irq_restore(flags);
atomic_long_inc(&skb->dev->rx_dropped);
kfree_skb(skb);
return NET_RX_DROP;
}
rps_ipi_queued函数内容,与RPS功能相关
/*
* Check if this softnet_data structure is another cpu one
* If yes, queue it to our IPI list and return 1
* If no, return 0
*/
static int rps_ipi_queued(struct softnet_data *sd)
{
#ifdef CONFIG_RPS
struct softnet_data *mysd = this_cpu_ptr(&softnet_data);
if (sd != mysd) {//sd对应的目标cpu并非当前所在cpu
sd->rps_ipi_next = mysd->rps_ipi_list;//将sd挂到当前cpu的rps_ipi_list上,后续到软中断处理流程里的net_rx_action时,会通知其他cpu来处理此类数据包。
mysd->rps_ipi_list = sd;//置此,mysd->rps_ipi_list会指向sd,sd->rps_ipi_next会指向一开始mysd->rps_ipi_list指向的softnet_data对象。相当于将sd头插进mysd->rps_ipi_list链表
__raise_softirq_irqoff(NET_RX_SOFTIRQ);//激活当前cpu的软中断
return 1;
}
#endif /* CONFIG_RPS */
return 0;
}
____napi_schedule函数定义:
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);//唤醒NET_RX_SOFTIRQ中断
}
注册软中断时,会注册对应类型的处理函数到全局数组softirq_vec中:
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
NET_RX_SOFTIRQ对应的软中断处理函数为net_rx_action:
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
unsigned long time_limit = jiffies + usecs_to_jiffies(netdev_budget_usecs);
int budget = netdev_budget;
LIST_HEAD(list);
LIST_HEAD(repoll);
local_irq_disable();
list_splice_init(&sd->poll_list, &list);//list_splice_init(a,b)会将链表a追加到链表b后面,并把链表a初始化成空链表头
local_irq_enable();
for (;;) {
struct napi_struct *n;
if (list_empty(&list)) {//如果当前cpu的poll_list是空的
if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))//如果没有其他cpu待处理的数据包,就跳出for循环
goto out;
/*
static bool sd_has_rps_ipi_waiting(struct softnet_data *sd){
#ifdef CONFIG_RPS
return sd->rps_ipi_list != NULL;
#else
return false;
#endif
}
*/
break;
}// end of if (list_empty(&list))
n = list_first_entry(&list, struct napi_struct, poll_list);//取出一个napi_struct对象
budget -= napi_poll(n, &repoll);//napi_poll内部调用当前napi_struct注册的poll函数,支持napi的驱动调用napi相关接口时会将它自己定义的napi_struct传进来。
//如果是非napi驱动则默认是cpu的softnet_data->backlog,poll函数是process_backlog
/* If softirq window is exhausted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ. */
if (unlikely(budget <= 0 || time_after_eq(jiffies, time_limit))) {//这端功能见上方英文注释,解释的很清楚。详细的软中断收包预算控制算法有兴趣可以看下
sd->time_squeeze++;
break;
}
}
local_irq_disable();
list_splice_tail_init(&sd->poll_list, &list);
list_splice_tail(&repoll, &list);
list_splice(&list, &sd->poll_list);
if (!list_empty(&sd->poll_list))
__raise_softirq_irqoff(NET_RX_SOFTIRQ);//如果未处理完本地cpu的数据包,再次触发软中断(可能是当前这次软中断的处理时间耗尽,等待下次软中断时继续处理)
net_rps_action_and_irq_enable(sd);//处理本应入队其他cpu的数据包
out:
__kfree_skb_flush();
}
net_rps_action_and_irq_enable函数定义如下:
static void net_rps_action_and_irq_enable(struct softnet_data *sd)
{
#ifdef CONFIG_RPS
struct softnet_data *remsd = sd->rps_ipi_list;
if (remsd) {
sd->rps_ipi_list = NULL;
local_irq_enable();
/* Send pending IPI's to kick RPS processing on remote cpus. */
net_rps_send_ipi(remsd);//net_rps_send_ipi内需要把本应由其他cpu处理的数据同步到指定cpu上,触发IPI(inter-processor interrupt)来通知指定cpu
} else
#endif
local_irq_enable();//退出时将当前cpu的硬中断打开,之前的操作均是在硬中断关闭情况下处理的。到达此步,硬中断上半部流程已结束,已经将数据从硬件中获取到内核中,接下来中断下半部会处理这部分数据
}
上文在net_rx_action取出poll_list的第一个对象,net_rx_action->napi_poll->(设备驱动注册的napi_struct* n->poll ) ,调用设备注册的NAPI poll函数,不支持NAPI的设备poll函数为process_backlog。
process_backlog函数定义如下:
static int process_backlog(struct napi_struct *napi, int quota)
{
struct softnet_data *sd = container_of(napi, struct softnet_data, backlog);
bool again = true;
int work = 0;
if (sd_has_rps_ipi_waiting(sd)) {
local_irq_disable();
net_rps_action_and_irq_enable(sd);//处理本应入队其他cpu的数据包
}
napi->weight = dev_rx_weight;
while (again) {
struct sk_buff *skb;
while ((skb = __skb_dequeue(&sd->process_queue))) {//取出一个skb。第一次走到此循环时,process_queue为空,不会进循环内部,会直接向下执行
rcu_read_lock();
__netif_receive_skb(skb);//将backlog中的skb取下来,向内核上层接口递交,真正进入内核协议栈
rcu_read_unlock();
input_queue_head_incr(sd);//weight相关
if (++work >= quota)
return work;
}
local_irq_disable();
rps_lock(sd);
if (skb_queue_empty(&sd->input_pkt_queue)) {//直至process_queue与input_pkt_queue均处理空了,才可结束,退出函数
napi->state = 0;
again = false;
} else {
skb_queue_splice_tail_init(&sd->input_pkt_queue, &sd->process_queue);//将input_pkt_queue的内容加到process_queue上,然后将input_pkt_queue初始化为空链表头。input_pkt_queue用于从网卡接收数据入队,process_queue用于取出数据递给协议栈出队
}
rps_unlock(sd);
local_irq_enable();
}
return work;
}
从__netif_receive_skb开始正式进入内核协议栈。
在文章开头,有提到支持NAPI驱动的调用流程在____napi_schedule、poll函数之前的步骤相同,poll之后的步骤与不支持NAPI驱动的有所差别。
回到支持NAPI的驱动流程,在napi_poll调用之后,会进入驱动程序注册的poll函数,poll函数里最终会通过netif_receive_skb来把skb上交给协议层。
netif_receive_skb->netif_receive_skb_internal->__netif_receive_skb
这样一来,是否支持NAPI驱动的后续流程从__netif_receive_skb又开始变得一致了。
总结一下,linux内核从驱动程序到内核协议栈接收数据包的函数流程如下图: