小模型大能量!10款高性能小模型,媲美大型模型!
在深度学习和人工智能领域,模型的体积和性能常常被视为正比关系:更大的模型通常意味着更好的性能。然而,随着研究的不断深入和技术的发展,高性能的小模型逐渐崭露头角,它们以小巧的体积实现了令人瞩目的性能,甚至在某些任务上超越了大型模型。
今天给大家整理了10款高性能的小模型,它们虽小,却蕴含着巨大的能量,能够媲美甚至超越大型模型。这些小模型的出现,不仅为研究和应用带来了更多的可能性,也让我们重新审视模型大小与性能之间的关系。
1、TinyLlama-1.1B
论文:TinyLlama: An Open-Source Small Language Model
Tinyllama:一个开放源代码的小型语言模型
简述:本文提出了TinyLlama,它是一个1.1B语言模型,在约1万亿标记上进行了约3个周期的预训练。它在Llama 2的基础上,利用开源社区的先进技术,提高了计算效率。尽管规模较小,TinyLlama在下游任务中表现出色,优于其他相似规模的开源模型。

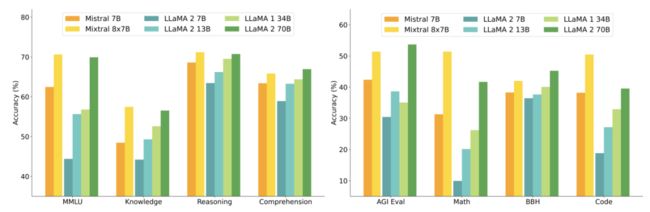
2、Mixtral 8x7B
论文:Mixtral of Experts
专家组合
简述:本文提出了Mixtral 8x7B,这是一种稀疏专家混合 (SMoE) 语言模型,在数学、代码生成和多语言基准测试方面远远优于 Llama 2 70B,并提供了一个经过微调以遵循指令的模型 Mixtral 8x7B - Instruct,它在人类基准测试中超过了 GPT-3.5 Turbo、Claude-2.1、Gemini Pro 和 Llama 2 70B - 聊天模型。
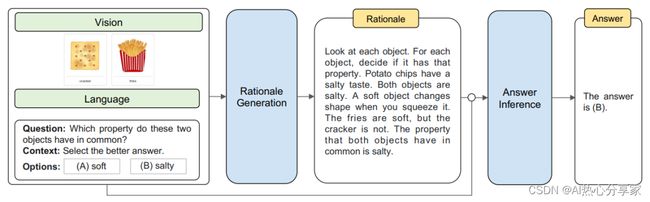
3、Multimodal-CoT
论文:Multimodal Chain-of-Thought Reasoning in Language Models
语言模型中的多模态思维链推理
简述:本文提出了一种新的多模态CoT框架,它结合了文本和图像信息,并将理由生成与答案推理分为两个步骤。这使得答案推理能够利用更丰富的多模态背景数据。使用这个框架,此模型在ScienceQA基准测试中比GPT-3.5提高了16个百分点,达到91.68%的准确率,超过了人类表现。
4、phi-1.5
论文:Textbooks are all you need ii: phi-1.5 technical report
教科书就是你所需要的 II:phi-1.5 技术报告
简述:本文提出了一个名为 phi-1.5 的 13 亿参数新模型,在自然语言任务上的性能与模型大 5 倍相当,并且在更复杂的推理任务(如小学数学和基础编码)上超过了大多数非前沿 LLM。

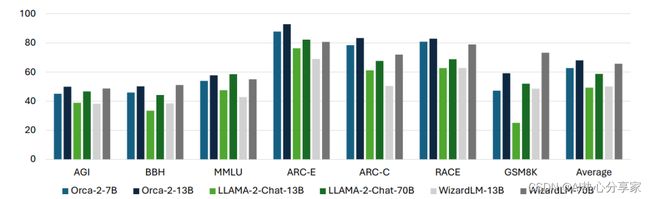
5、Orca 2
论文:Orca 2: Teaching Small Language Models How to Reason
Orca 2: 教会小型语言模型如何进行推理
简述:本文提出了一个增强较小语言模型推理能力的Orca 2模型,通过使用一套包括逐步处理、回忆-生成、回忆-推理-生成、提取-生成和直接回答等推理技术来教授这些较小模型,并帮助模型为每个任务找到最佳策略。研究人员使用15个基准评估Orca 2,其性能超越同类并达到大5-10倍模型的性能,在高级推理任务的零样本设置中评估。
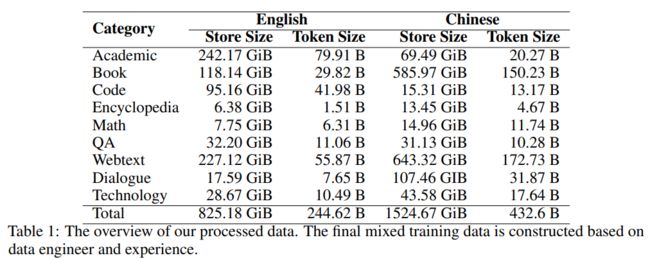
6、MindLLM
论文:MindLLM: Pre-training Lightweight Large Language Model from Scratch, Evaluations and Domain Applications
MindLLM:从头开始预训练轻量级大型语言模型、评估和领域应用程序
简述:本文提出了MindLLM,一个新颖的双语轻量级大型语言模型系列,通过提供13亿和30亿参数模型减轻负担,涵盖数据构建、模型架构、评估和应用,分享大模型开发经验。MindLLM在公共基准测试中性能卓越,并引入创新指令调优框架增强功能。
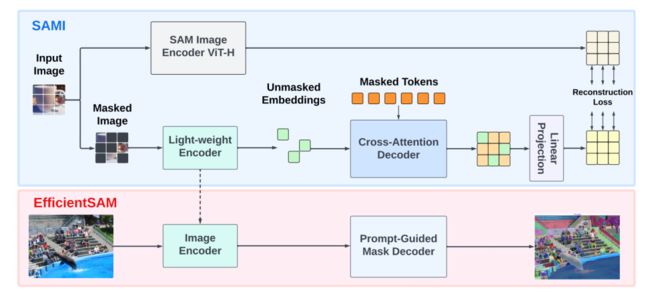
7、EfficientSAM
论文:EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
EfficientSAM:利用屏蔽图像预训练对任何内容进行高效分割
简述:本文提出了EfficientSAM,一种高性能、低复杂度的SAM模型。它使用SAMI(掩码图像预训练)学习高效的视觉表示,通过重建特征训练图像编码器。研究人员用预训练的编码器和解码器构建EfficientSAM,并针对分割任务进行调整。测试表明,SAMI预训练法优于其他方法,EfficientSAM在零样本实例分割等任务上表现出优势,在COCO/LVIS上提升约4 AP。
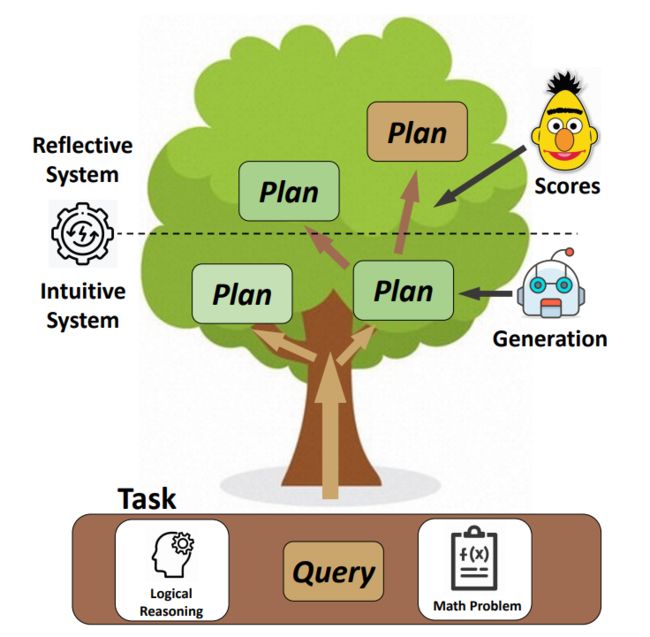
8、CogTree
论文:From Complex to Simple: Unraveling the Cognitive Tree for Reasoning with Small Language Models
从复杂到简单:使用小型语言模型解开推理的认知树
简述:本文中采用迭代法构建CogTree,根节点表示初始查询,叶节点为简单答案。此框架包含两部分:一是直观系统,迅速根据上下文生成响应;二是反思系统,通过比较学习来评估这些响应并指导直观系统的后续生成。实验显示,在两个复杂的推理任务上,这个框架虽然使用的是远小于GPT-3.5的语言模型(参数不超过7B),但性能可以媲美参数高达175B的GPT-3.5。
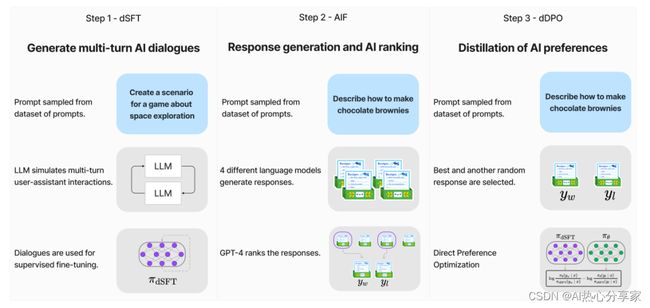
9、Zephyr
论文:ZEPHYR: DIRECT DISTILLATION OF LM ALIGNMENT
Zephyr:LM取向的直接蒸馏
简述:本文中利用AI反馈的偏好数据,采用蒸馏直接偏好优化法来训练意图一致性更高的聊天模型。此方法仅需几小时培训,且无需额外采样。最终,Zephyr-7B(7B参数模型)达到了最先进的聊天基准,无需人工注释。在MT-Bench上,Zephyr-7B超越了最佳开放访问模型Llama2-Chat-70B。
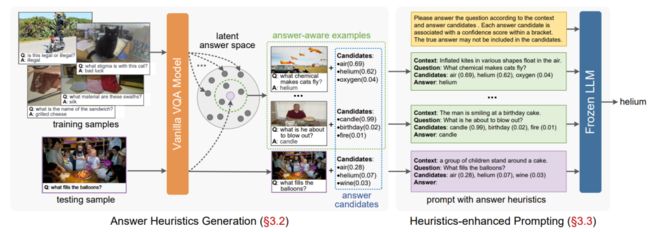
10、Prophet
论文:Prophet: Prompting Large Language Models with Complementary Answer Heuristics for Knowledge-based Visual Question Answering
Prophet:使用基于知识的视觉问答的补充答案启发式提示大型语言模型
简述:本文提出了Prophet框架,能增强大型语言模型(LLM)在知识型视觉问题回答(VQA)中性能。通过先训练一个标准的VQA模型来提取候选答案和示例,然后将这些信息转化为格式化提示,以提高LLM的回答准确度。在测试中,使用GPT-3的Prophet在几个知识型VQA数据集上的表现超过了现有的先进方法。还展示了Prophet的可适用性,可以与不同的VQA模型和LLM相结合以验证其效果。
论文和代码整理好了
关注下方《享享学AI》
回复关键词【小模型】即可获取