大数据开发之Kafka(broker、消费者、eagle监控、kraft模式)
第 4 章:Kafka Broker
4.1 Kafka Broker工作流程
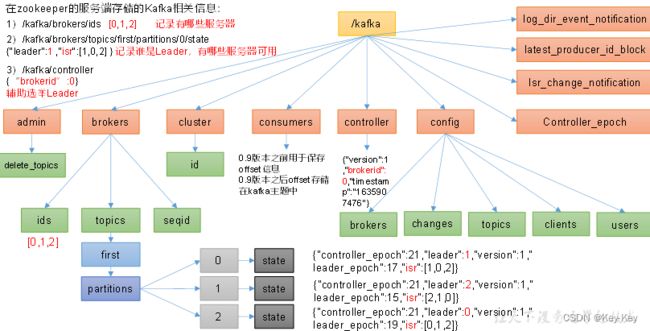
4.1.1 Zookeeper存储的Kafka的信息
1、查看zookeeper中的kafka节点所存储的信息
启动Zookeeper客户端
[atguigu@hadoop104 zookeeper-3.5.7]$ bin/zkCli.sh
通过ls命令列出kafka节点内容
[zk: localhost:2181(CONNECTED) 2] ls /kafka
2、zookeeper中存储的kafka信息
在zookeeper的服务端存储的Kafka相关信息:
1)/kafka/brokers/ids [0,1,2] 记录有哪些服务器
2)/kafka/brokers/topics/first/partitions/0/state {“leader”.1,“isr”:[1,0,2]} 记录谁是leader,有哪些服务器可用
3)/kafka/controller {“brokerid”:0} 辅助选举Leader
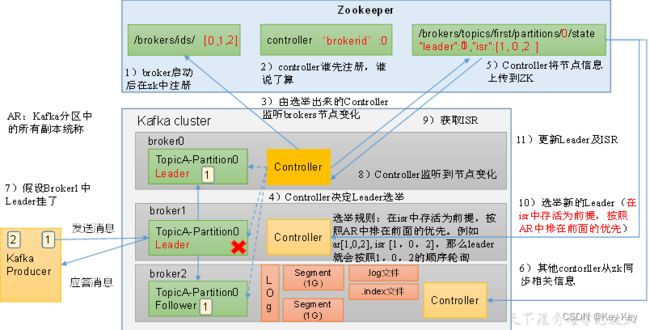
4.1.2 Kafka Broker总体工作流程
1、Kafka Broker工作流程图示
2、案例
1)案例内容:模拟kafka上下线,查看zookeeper中数据变化
2)查看kafka节点相关信息:
(1)查看zookeeper上的kafka集群节点信息
[zk: localhost:2181(CONNECTED) 2] ls /kafka/brokers/ids
[102, 103, 104]
(2)查看当前kafka集群节点中的controller信息
[zk: localhost:2181(CONNECTED) 2] get /kafka/controller
{"version":1,"brokerid":103,"timestamp":"1637292471777"}
(3)查看kafka中的first主题的0号分区的状态
[zk: localhost:2181(CONNECTED) 2] get /kafka/brokers/topics/first/partitions/0/state
{"controller_epoch":24,"leader":102,"version":1,"leader_epoch":18,"isr":[102,103,104]}
3)模拟kafka下线:停止hadoop103上的kafka
[atguigu@hadoop103 kafka]$ bin/kafka-server-stop.sh
4)查看kafka相关节点信息
(1)查看zookeeper上的kafka集群节点信息
[zk: localhost:2181(CONNECTED) 2] ls /kafka/brokers/ids
[102, 104]
(2)查看当前kafka集群节点中的controller信息
[zk: localhost:2181(CONNECTED) 2] ls /kafka/controller
{"version":1,"brokerid":102,"timestamp":"1637292471777"}
(3)查看kafka中的first主题的0号分区的状态
[zk: localhost:2181(CONNECTED) 2] get /kafka/brokers/topics/partitions/0/state
{"controller_epoch":24,"leader":102,"version":1,"leader_epoch":18,"isr":[102,104]}
5)重新启动hadoop103上的kafka服务
[atguigu@hadoop103 kafka]$ bin/kafka-server-stop.sh
6)再次查看上述节点,观察区别变化
4.1.3 Broker重要参数
| 参数名称 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR中的Follower超过该事件阈值(默认30s)未向leader发送同步数据,则该Follower将被提出ISR |
| auto.leader.rebalance.enable | 默认是true。自动Leader Partition平衡 |
| leader.imbalance.per.broker.percentage | 默认是10%。每个broker允许的不平衡的leader的比率。如果每个broker超过了这个值,控制器会触发leader的平衡 |
| leader.imbalance.check.interval.seconds | 默认值300秒。检查leader负载是否平衡的间隔时间 |
| log.index.interval.bytes | 默认4kb,kafka里面每当写入了4kv大小的日志(.log),然后就往index文件里面记录一个索引 |
| log.retention.hours | Kafka中数据保存的时间,默认7天 |
| log.retention.minutes | Kafka中数据保存的时间,分钟级别,默认关闭 |
| log.retention.ms | Kafka中数据保存的时间,毫秒级别,默认关闭(优先级最高) |
| log.retention.check.interval.ms | 检查数据是否保存超时的间隔,默认是5分钟 |
| log.retention.bytes | 默认等于-1,表示无穷大。超过设置的所有日志总大小,删除最早的segment |
| log.cleanup.policy | 默认是delete,表示所有数据启用删除策略;如果设置值未compact,表示所有数据启用压缩策略 |
| num.io.threads | 默认是8。负责写磁盘的线程数。整个参数值要占总核数的50% |
| num.replica.fetchers | 副本拉取线程数,这个参数占总核数的50%的1/3 |
| num.network.threads | 默认是3。数据传输线程数,这个参数占总核数的50%的1/3 |
| log.flush.interval.messages | 强制页缓存刷写到磁盘的条数,默认是Max(long)(9223372036854775807)。一般交给系统管理 |
| log.flush.interval.ms | 每隔多久,刷数据到磁盘,默认是null。一般不建议修改,交给系统自己管理 |
4.2 Kafka 副本
4.2.1 kafka副本的基本信息
| kafka副本作用 | 提供数据可靠性 |
|---|---|
| kafka副本个数 | 默认1个,生产环境中一般配置为2个,保证数据可靠性;但是过多的副本会增加磁盘存储空间、增加网络数据传输、降低kafka效率 |
| kafka副本角色 | 副本角色分为leader和follower。kafka生产者只会把数据发送给leader,follower会主动从leader上同步数据 |
| kafka中的ar | 是所有副本的统称(Assigned repllicas),ar=isr+osr。isr:表示和leader保持同步(默认30s)的follower集合。osr:表示follower与leader副本同步时,延迟过多的副本 |
4.2.2 leader选举过程
1、Kafka controller:
kafka集群中有一个broker的Controller会被选举为Controller Leader,负责管理集群broker的上下线、所有topic的分区副本分配和Leader选举等工作。Controller的信息同步工作是依赖于Zookeeper的。
2、kafka分区副本的选举流程

1)各个broker启动并注册到zookeeper的/brokers/ids路径下
2)选择一个controller,controller是kafka集群中的一个broker,负责管理partition leader的选举
3)controller监控broker的上下线状态
4)当controller检测到leader broker宕机时,会触发leader选举
5)controller更新zookeeper中的/brokers/topics/~/state路径,写入新的leader信息
6)其它broker检测到controller的信息变更,更新本地的元数据
7)新的leaderbroker开始服务,接收读写请求
8)controller同时更新isr,即与leader数据保持同步的副本信息
9)如果controller自身宕机,将会有新的broker被选举为controller
10)选举过程中会考虑isr列表中的broker,确保数据的一致性和可靠性
11)完成leader选举和isr更新后,集群恢复到正常状态
3、案例
1)查看first的详细信息,注意观察副本分布情况
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first
Topic: first TopicId: aUFTM5wES7eSBiuSKT0UpA PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: first Partition: 0 Leader: 102 Replicas: 102,104,103 Isr: 102,104,103
Topic: first Partition: 1 Leader: 103 Replicas: 103,102,104 Isr: 103,102,104
Topic: first Partition: 2 Leader: 104 Replicas: 104,103,102 Isr: 104,103,102
2)停掉103上的kafka进程
[atguigu@hadoop103 kafka]$ bin/kafka-server-stop.sh
3)再次查看first的相应信息,观察副本分布
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first
Topic: first TopicId: aUFTM5wES7eSBiuSKT0UpA PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: first Partition: 0 Leader: 102 Replicas: 102,104,103 Isr: 102,104
Topic: first Partition: 1 Leader: 102 Replicas: 103,102,104 Isr: 102,104
Topic: first Partition: 2 Leader: 104 Replicas: 104,103,102 Isr: 104,102
4)处理分区leader分布不均匀问题
[atguigu@hadoop102 kafka]$ bin/kafka-leader-election.sh --bootstrap-server hadoop102:9092 --topic first --election-type preferred --partition 0
[atguigu@hadoop102 kafka]$ bin/kafka-leader-election.sh --bootstrap-server hadoop102:9092 --topic first --election-type preferred --partition 1
[atguigu@hadoop102 kafka]$ bin/kafka-leader-election.sh --bootstrap-server hadoop102:9092 --topic first --election-type preferred --partition 2
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first
Topic: first TopicId: aUFTM5wES7eSBiuSKT0UpA PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: first Partition: 0 Leader: 102 Replicas: 102,104,103 Isr: 102,104,103
Topic: first Partition: 1 Leader: 103 Replicas: 103,102,104 Isr: 102,104,103
Topic: first Partition: 2 Leader: 104 Replicas: 104,103,102 Isr: 104,102,103
###4.2.3 leader和follower故障处理细节
1、follower故障处理细节(被踢-重连-追上hw-连接成功)
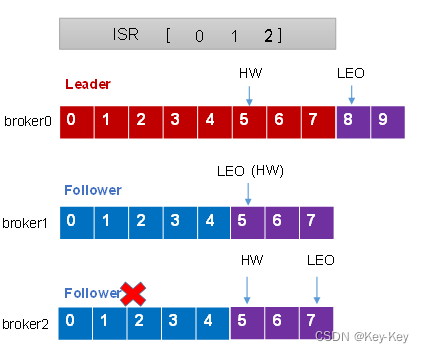
1)Follower发生故障后会被临时踢出isr
2)这个期间leader和follower继续接收数据
3)待该follower恢复后,follower会读取本地磁盘记录上次的hw,并将log文件高于hw的部分截取掉,从hw开始向leader进行同步
4)等该follower的leo大于等于该partition的hw,即follower追上leader之后,就可以重新加入isr了
2、leader故障处理细节(从isr队列读取ar中靠前的节点选为leader,新leader短则follower“剪”,反之则向leader同步)
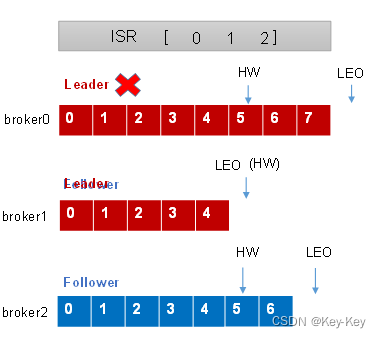
1)leader发生故障后,会从isr中选出一个新的leader
2)为保证对各副本之间的数据一致性,其余的follower会先将各自的log文件高于hw的部分截掉,然后从新的leader同步数据
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复
关键词:
leo:指的是每个副本最大的offset
hw:指的是消费者能见到的最大的offset,isr队列中最小的leo
4.3 文件存储
4.3.1 文件存储机制
1、topic数据的存储机制
2、查看文件存储
1)查看hadoop102的kafka文件存储
[atguigu@hadoop104 first-1]$ ls
00000000000000000092.index
00000000000000000092.log
00000000000000000092.snapshot
00000000000000000092.timeindex
leader-epoch-checkpoint
partition.metadata
2)直接查看log日志,是乱码需要使用工具查看
[atguigu@hadoop104 first-1]$ cat 00000000000000000092.log
\CYnF|©|©ÿÿÿÿÿÿÿÿÿÿÿÿÿÿ"hello world
3)通过工具查看
查看index文件
[atguigu@hadoop104 first-1]$ kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.index
Dumping ./00000000000000000000.index
offset: 3 position: 152
查看log文件
[atguigu@hadoop104 first-1]$ kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.log
Dumping datas/first-0/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 1 count: 2 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1636338440962 size: 75 magic: 2 compresscodec: none crc: 2745337109 isvalid: true
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 75 CreateTime: 1636351749089 size: 77 magic: 2 compresscodec: none crc: 273943004 isvalid: true
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 152 CreateTime: 1636351749119 size: 77 magic: 2 compresscodec: none crc: 106207379 isvalid: true
baseOffset: 4 lastOffset: 8 count: 5 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 229 CreateTime: 1636353061435 size: 141 magic: 2 compresscodec: none crc: 157376877 isvalid: true
baseOffset: 9 lastOffset: 13 count: 5 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 370 CreateTime: 1636353204051 size: 146 magic: 2 compresscodec: none crc: 4058582827 isvalid: true
3、index文件和log文件详解
1)详解
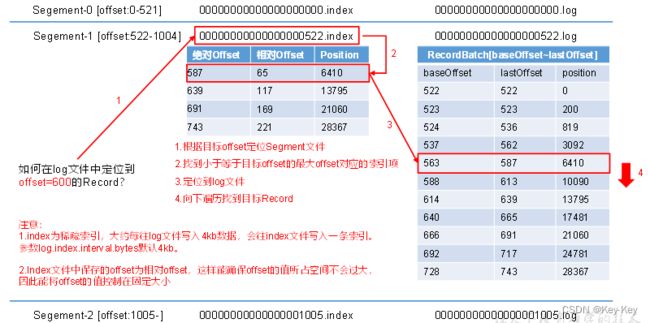
segment文件:kafka的日志被分割为多个segment,每个segment由一组连续的消息组成。例如,segment-0包含偏移量0到521的消息,segment-1包含偏移量522到1004的消息。
索引文件(.index):每个segment都有一个索引文件,用于快速查找特定偏移量的消息。这个文件包含一系列的索引项,每个索引项包含一个偏移量和对应日志文件中的位置(字节数)。
日志文件(.log):实际存储消息记录的文件。每条消息都有一个基准偏移量(baseOffset)和最后一个偏移量(lastOffset),以及它在文件中的位置(position)
2)日志存储参数配置
| 参数 | 描述 |
|---|---|
| log.segment.bytes | kafka中log日志是分成一块块存储的,此配置是指log日志划分成块的大小,默认值1G |
| log.index.interval.bytes | 默认4kb,kafka里面每当写入了4kb大小的日志(.log),然后就往index文件里面记录一个索引。稀疏索引 |
4.3.2 文件清理策略
1、kafka数据文件保持时间:默认是7天
2、kafka数据文件保持可通过如下参数修改
1)log.retention.hours:最低优先级小时,默认7天
2)log.retention.minutes:分钟
3)log.retention.ms:最高优先级毫秒
4)log.retention.check.interval.ms:负责设置检查周期,默认5分钟
3、那么一旦查过了设置的时间就会采取清理策略,清理策略有两种:delete和compact
1)delete策略
delete日志删除:将过去数据删除。
配置:log.cleanup.policy=delete
基于时间:默认打开,以segment中所有记录中的最大时间戳作为文件时间戳
基于大小:默认关闭,超过设置的所有日志大小,删除最早的segment
log.retention.bytes,默认等于-1,表示无穷大
2、compact日志策略

4.4 高效读写数据
1、kafka本身是分布式集群,可以采用分区技术,并行度高
2、读数据采用稀疏索引,可以快速定位要消费的数据
3、顺序写磁盘
kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。官方有数据表明,同样的磁盘,顺序写能到600MB/s,而随机写只有100K/s。中间省去大量磁头寻址的时间。
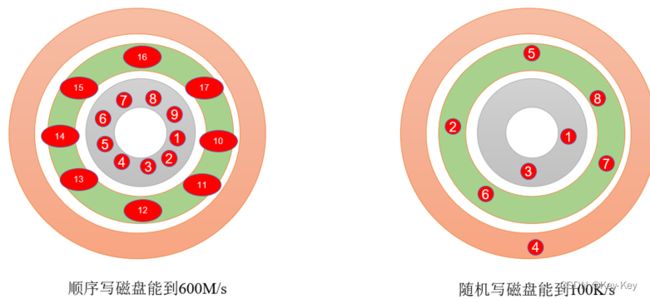
4、页存储+零拷贝技术
零拷贝:Kafka Broker应用层不关心存储的数据,所以就不走应用层,传输效率高。
PageCache页缓存:当上层有写操作的时候,操作系统只是将数据写入PageCache。当读操作发生时,先从PageCache中查找,如果找不到,再去磁盘中读取。

第 5 章:Kafka消费者
5.1 Kafka消费方式
Kafka的consumer采用pull(拉)模式从broker中读取数据
| push(推)模式 | 很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞 |
|---|---|
| pull模式 | 可以根据consumer的消费能力以适当的速率消费消息。不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,kafka的消费者在消费数据时会传入一个时常参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时常即为timeout |
5.2 Kafka消费者工作流程
5.2.1 消费者总体工作流程
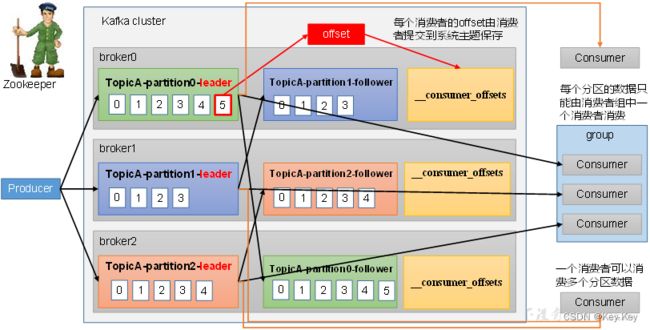
5.2.2 消费者组原理
Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
1)消费者组内每个消费者负责消费不同分区的数据,一个分区由一个组内消费者消费。
2)消费者者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。

注意:
如果向消费者组中添加更多的消费者,超过主题分区数量,则有一部分消费者就会闲置。不会接收任何消息。
消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
消费者组初始化流程
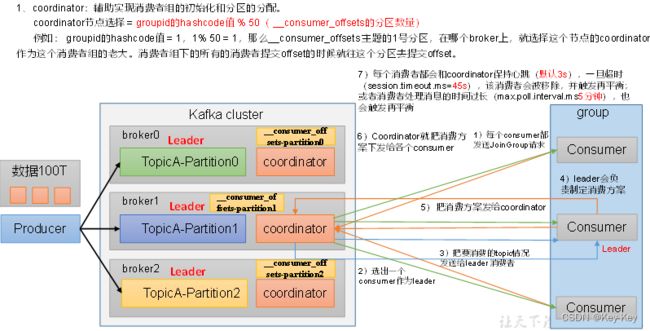
消费者组详细消费流程

5.2.3 消费者重要参数
| 参数名称 | 描述 |
|---|---|
| bootstrap.servers | 向Kafka集群建立初始连接用到的host/port列表。 |
| key.deserializer、value.deserializer | 指定接收消息的key和value的反序列化类型。要写全类名。 |
| group.id | 标记消费者所属的消费者组。 |
| enable.auto.commit | 默认值为true,消费者会自动周期性地向服务器提交偏移量。 |
| auto.commit.interval.ms | 若enable.auto.commit=true, 表示消费者提交偏移量频率,默认5s。 |
| auto.offset.reset | 当Kafka中没有初始偏移量或当前偏移量在服务器中不存在(如,数据被删除了),该如何处理? earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常。 anything:向消费者抛异常。 |
| offsets.topic.num.partitions | __consumer_offsets的分区数,默认是50个分区。 |
| heartbeat.interval.ms | Kafka消费者和coordinator之间的心跳时间,默认3s。该条目的值必须小于 session.timeout.ms ,也不应该高于 session.timeout.ms 的1/3。 |
| session.timeout.ms | Kafka消费者和coordinator之间连接超时时间,默认45s。超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是5分钟。超过该值,该消费者被移除,消费者组执行再平衡。 |
| fetch.min.bytes | 默认1个字节。消费者获取服务器端一批消息最小的字节数。 |
| etch.max.wait.ms | 默认500ms。如果没有从服务器端获取到一批数据的最小字节数。该时间到,仍然会返回数据。 |
| fetch.max.bytes | 默认Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受message.max.bytes (broker config)or max.message.bytes (topic config)影响。 |
| max.poll.records | 一次poll拉取数据返回消息的最大条数,默认是500条。 |
5.3 消费者API
5.3.1 独立消费者案例(订阅主题)

1、需求:创建一个独立消费者,消费first主题中的数据
注意:在消费者API代码中必须配置消费者组id
2、案例
1)创建包名:com.atguigu.kafka.consumer
2)编写代码
package com.atguigu.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class CustomConsumer {
public static void main(String[] args) {
// 1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
// 配置消费者组 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
// 3. 创建消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
// 4. 订阅主题
ArrayList<String> topics= new ArrayList<>();
topics.add("first");
consumer.subscribe(topics);
// 5. 拉取数据打印
while (true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
// 6. 遍历并输出消费到的数据
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord);
}
}
}
}
3)测试
(1)在IDEA中执行消费者程序
(2)hadoop102中创建kafka生产者,并输入数据
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first
>hello
(3)在IDEA中观察接收到的数据
ConsumerRecord(topic = first, partition = 1, leaderEpoch = 3, offset = 0, CreateTime = 1629160841112, serialized key size = -1, serialized value size = 5, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = hello)
5.3.2 消费者组案例
1、需求:观察消费者组消费数据时的如下特点
1)消费者组中的消费者消费不同分区的数据
2)消费者数量大于Topic的分区数时,会在消费者消费不到数据
2)每当消费者组内成员数发生变化时,就会进行主题分区对消费者的重分配
2、案例
1)添加日志框架jar
配置日志框架,可以将kafka的运行日志打印在控制台
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
2)创建主题
创建一个只有两个分区的topic,topic的名字为“groupTest01”
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --replication-factor 2 --partitions 2 --topic groupTest01
3)编辑消费者
复制两份基础消费者的代码,消费者组改为“group01”,订阅主题修改为“groupTest01”,在idea中同时启动,即开启同一个消费者组中的两个消费者。
package com.atguigu.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class CustomConsumer {
public static void main(String[] args) {
// 1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
// 配置消费者组 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group01");
// 3. 创建消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
// 4. 订阅主题
ArrayList<String> topics= new ArrayList<>();
topics.add("groupTest01");
consumer.subscribe(topics);
// 5. 拉取数据打印
while (true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
// 6. 遍历并输出消费到的数据
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord);
}
}
}
}
4)启动生产者后,观察控制台输出,先启动一个消费者customconsumer01后,观察控制台输出
package com.atguigu.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class CustomConsumer {
public static void main(String[] args) {
// 1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
// 配置消费者组 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group01");
// 3. 创建消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
// 4. 订阅主题
ArrayList<String> topics= new ArrayList<>();
topics.add("groupTest01");
consumer.subscribe(topics);
// 5. 拉取数据打印
while (true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
// 6. 遍历并输出消费到的数据
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord);
}
}
}
}
5)再启动一个消费者customconsumer02后,观察控制台输出
// CustomConsumer01控制台输出
Successfully synced group in generation Generation{generationId=2, memberId='consumer-group01-1-44ba7ef2-e39b-4d3d-a78f-0c1afeceb871', protocol='range'}
Notifying assignor about the new Assignment(partitions=[groupTest01-0])
Adding newly assigned partitions: groupTest01-0
// CustomConsumer02控制台输出
Successfully synced group in generation Generation{generationId=2, memberId='consumer-group01-1-acc35e3e-371b-4702-8b9b-376c6144e676', protocol='range'}
Notifying assignor about the new Assignment(partitions=[groupTest01-1])
Adding newly assigned partitions: groupTest01-1
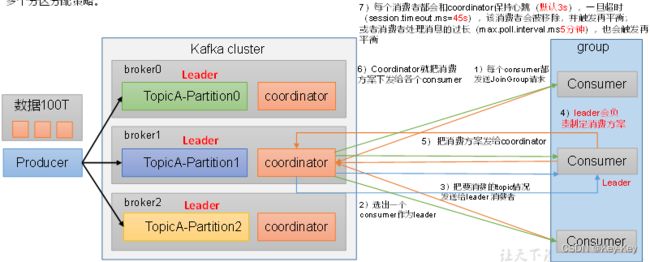
5.4 生产经验-分区分配策略及再平衡
分区的分配以及再平衡
1、一个consumer group中有多个consumer,一个topic有多个partition组成,现在的问题是,到底由哪个consumer来消费哪个partition的数据。
2、kafka有四种主流的分区分配策略:range、roundrobin、sticky、cooperativesticky
可以通过配置参数partition.assignment.strategy,修改分区的分配策略。默认策略是range+cooperativesticky。kafka可以同时使用多个分区分配策略。
| 参数名称 | 描述 |
|---|---|
| heartbeat.interval.ms | Kafka消费者和coordinator之间的心跳时间,默认3s。该条目的值必须小于 session.timeout.ms,也不应该高于 session.timeout.ms 的1/3。 |
| session.timeout.ms | Kafka消费者和coordinator之间连接超时时间,默认45s。超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是5分钟。超过该值,该消费者被移除,消费者组执行再平衡。 |
| partition.assignment.strategy | 消费者分区分配策略,默认策略是Range + CooperativeSticky。Kafka可以同时使用多个分区分配策略。可以选择的策略包括:Range、RoundRobin、Sticky、CooperativeSticky |
5.4.1 生产者分区分配之Range及再平衡
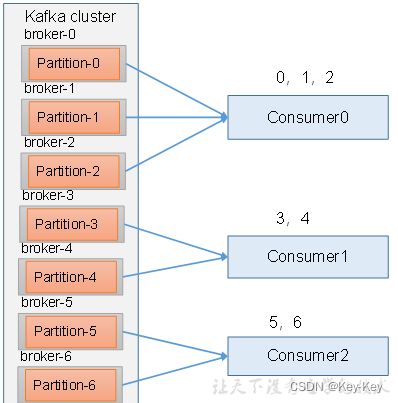
1、range分区策略原理
range是对每个topic而言的。
首先对同一个topic里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。
假如现在又7个分区,3个消费者,排序后的分区将会是0,1,2,3,4,5,6;消费者排完后将会是c0、c1、c2。
通过partitions数/consumer数来决定每个消费者应该消费几个分区,如果除不尽,那么前面几个消费者将会多消费1个分区。
例如,7/3=2余1,除不尽,那么消费者c0便会多消费1个分区。
注意:如果只是针对1个topic而言,c0消费者多消费1个分区影响不是很大。但是如果在n多个topic,那么针对每个topic,消费者c0都将多消费1个分区,topic越多,c0消费的分区会比其它消费者明显多消费n个分区。
2、range分区分配策略及再平衡案例
1)准备
(1)修改主题grouptest01的分区为7个分区
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic groupTest01--partitions 7
(2)创建3个消费者,并组成消费者组group02,消费主题grouptest01
(3)观察分区分配情况
启动第一个消费者,观察分区分配情况
// consumer01
Successfully synced group in generation Generation{generationId=1, memberId='consumer-group02-1-4b019db6-948a-40d2-9d8d-8bbd79f59b14', protocol='range'}
Notifying assignor about the new Assignment(partitions=[groupTest01-0, groupTest01-1, groupTest01-2, groupTest01-3, groupTest01-4, groupTest01-5, groupTest01-6])
Adding newly assigned partitions: groupTest01-3, groupTest01-2, groupTest01-1, groupTest01-0, groupTest01-6, groupTest01-5, groupTest01-4
启动第二个消费者,观察分区分配情况
// consumer01
Successfully synced group in generation Generation{generationId=2, memberId='consumer-group02-1-4b019db6-948a-40d2-9d8d-8bbd79f59b14', protocol='range'}
Notifying assignor about the new Assignment(partitions=[groupTest01-0, groupTest01-1, groupTest01-2, groupTest01-3])
Adding newly assigned partitions: groupTest01-3, groupTest01-2, groupTest01-1, groupTest01-0
// consumer02
Successfully synced group in generation Generation{generationId=2, memberId='consumer-group02-1-60afd984-6916-4101-8e72-ae52fa8ded6c', protocol='range'}
Notifying assignor about the new Assignment(partitions=[groupTest01-4, groupTest01-5, groupTest01-6])
Adding newly assigned partitions: groupTest01-6, groupTest01-5, groupTest01-4
启动第三个消费者,观察分区分配情况
// consumer01
Successfully synced group in generation Generation{generationId=3, memberId='consumer-group02-1-4b019db6-948a-40d2-9d8d-8bbd79f59b14', protocol='range'}
Notifying assignor about the new Assignment(partitions=[groupTest01-0, groupTest01-1, groupTest01-2])
Adding newly assigned partitions: groupTest01-2, groupTest01-1, groupTest01-0
// consumer02
Successfully synced group in generation Generation{generationId=3, memberId='consumer-group02-1-60afd984-6916-4101-8e72-ae52fa8ded6c', protocol='range'}
Notifying assignor about the new Assignment(partitions=[groupTest01-3, groupTest01-4])
Adding newly assigned partitions: groupTest01-3, groupTest01-4
// consumer03
Successfully synced group in generation Generation{generationId=3, memberId='consumer-group02-1-fd15f50f-0a33-4e3a-8b8c-237252a41f4d', protocol='range'}
Notifying assignor about the new Assignment(partitions=[groupTest01-5, groupTest01-6])
Adding newly assigned partitions: groupTest01-6, groupTest01-5
5.4.2 生产者分区分配之roundrobin策略及再平衡
1、roundrobin分区分配策略原理
roundrobin针对集群中所有topic而言。
roundrobin轮询分区策略,是把所有partition和所有consumer都列出来,然后按照hashcode进行排序,最后通过轮询算法来分配partition给到各个消费者。

2、roundrobin分区分配策略及再平衡案例
案例:
修改消费者代码,消费者组都是group03.
修改分区分配策略为roundobin
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, RoundRobinAssignor.class.getName());
依次启动3个消费者,观察控制台输出
启动消费者customconsumer01,观察控制台输出
// customConsumer01
Successfully synced group in generation Generation{generationId=1, memberId='consumer-group03-1-2d38c78b-b17d-4d43-93f5-4b676f703177', protocol='roundrobin'}
Notifying assignor about the new Assignment(partitions=[groupTest01-0, groupTest01-1, groupTest01-2, groupTest01-3, groupTest01-4, groupTest01-5, groupTest01-6])
Adding newly assigned partitions: groupTest01-3, groupTest01-2, groupTest01-1, groupTest01-0, groupTest01-6, groupTest01-5, groupTest01-4
启动消费者customconsumer02,观察控制台输出
// customConsumer01
Successfully synced group in generation Generation{generationId=2, memberId='consumer-group03-1-2d38c78b-b17d-4d43-93f5-4b676f703177', protocol='roundrobin'}
Notifying assignor about the new Assignment(partitions=[groupTest01-0, groupTest01-2, groupTest01-4, groupTest01-6])
Adding newly assigned partitions: groupTest01-2, groupTest01-0, groupTest01-6, groupTest01-4
// customConsumter02
Successfully synced group in generation Generation{generationId=2, memberId='consumer-group03-1-5771a594-4e99-47e8-9df6-ca820af6698b', protocol='roundrobin'}
Notifying assignor about the new Assignment(partitions=[groupTest01-1, groupTest01-3, groupTest01-5])
Adding newly assigned partitions: groupTest01-3, groupTest01-1, groupTest01-5
启动消费者customconsumer03,观察控制台输出
// customConsumer01
Successfully synced group in generation Generation{generationId=3, memberId='consumer-group03-1-2d38c78b-b17d-4d43-93f5-4b676f703177', protocol='roundrobin'}
Notifying assignor about the new Assignment(partitions=[groupTest01-0, groupTest01-3, groupTest01-6])
Adding newly assigned partitions: groupTest01-3, groupTest01-0, groupTest01-6
// customConsumter02
Successfully synced group in generation Generation{generationId=3, memberId='consumer-group03-1-5771a594-4e99-47e8-9df6-ca820af6698b', protocol='roundrobin'}
Notifying assignor about the new Assignment(partitions=[groupTest01-1, groupTest01-4])
Adding newly assigned partitions: groupTest01-1, groupTest01-4
// customConsumter03
Successfully synced group in generation Generation{generationId=3, memberId='consumer-group03-1-d493b011-d6ea-4c36-8ae5-3597db635219', protocol='roundrobin'}
Notifying assignor about the new Assignment(partitions=[groupTest01-2, groupTest01-5])
Adding newly assigned partitions: groupTest01-2, groupTest01-5
5.4.3 生产者分区分配之sticky及再平衡
1、粘性分区定义:
在执行一次新的分配之前,考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。粘性分区是kafka从0.11.x版本开始引入这种分配策略,首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化。
2、sticky分区分配策略及再平衡案例
1)修改分区分配策略,修改消费者组为grouptest03
// 修改分区分配策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, StickyAssignor.class.getName());
2)分别启动三个消费者后,查看第三次分配如下
启动消费者customconsumer01,观察控制台输出
// customConsumer01
Successfully synced group in generation Generation{generationId=1, memberId='consumer-group06-1-19e1e6a4-e2ca-467d-909f-3769dc527d34', protocol='sticky'}
Notifying assignor about the new Assignment(partitions=[groupTest01-0, groupTest01-1, groupTest01-2, groupTest01-3, groupTest01-4, groupTest01-5, groupTest01-6])
Adding newly assigned partitions: groupTest01-3, groupTest01-2, groupTest01-1, groupTest01-0, groupTest01-6, groupTest01-5, groupTest01-4
启动消费者customconsumer02,观察控制台输出
// customConsumer01
Successfully synced group in generation Generation{generationId=2, memberId='consumer-group06-1-19e1e6a4-e2ca-467d-909f-3769dc527d34', protocol='sticky'}
Notifying assignor about the new Assignment(partitions=[groupTest01-0, groupTest01-1, groupTest01-2, groupTest01-3])
Adding newly assigned partitions: groupTest01-3, groupTest01-2, groupTest01-1, groupTest01-0
// customConsumer02
Successfully synced group in generation Generation{generationId=2, memberId='consumer-group06-1-6ea3622c-bbe8-4e13-8803-d5431a224671', protocol='sticky'}
Notifying assignor about the new Assignment(partitions=[groupTest01-4, groupTest01-5, groupTest01-6])
Adding newly assigned partitions: groupTest01-6, groupTest01-5, groupTest01-4
启动消费者customconsumer03,观察控制台输出
// customConsumer01
Successfully synced group in generation Generation{generationId=3, memberId='consumer-group06-1-19e1e6a4-e2ca-467d-909f-3769dc527d34', protocol='sticky'}
Notifying assignor about the new Assignment(partitions=[groupTest01-0, groupTest01-1, groupTest01-2])
Adding newly assigned partitions: groupTest01-2, groupTest01-1, groupTest01-0
// customConsumer02
Successfully synced group in generation Generation{generationId=3, memberId='consumer-group06-1-6ea3622c-bbe8-4e13-8803-d5431a224671', protocol='sticky'}
Notifying assignor about the new Assignment(partitions=[groupTest01-4, groupTest01-5])
Adding newly assigned partitions: groupTest01-5, groupTest01-4
// customConsumer03
Successfully synced group in generation Generation{generationId=3, memberId='consumer-group06-1-eb0ac20c-5d94-43a7-b7c1-96a561513995', protocol='sticky'}
Notifying assignor about the new Assignment(partitions=[groupTest01-3, groupTest01-6])
Adding newly assigned partitions: groupTest01-3, groupTest01-6
3)杀死消费者~01,观察控制台输出
// customConsumer02
Successfully synced group in generation Generation{generationId=4, memberId='consumer-group06-1-6ea3622c-bbe8-4e13-8803-d5431a224671', protocol='sticky'}
Notifying assignor about the new Assignment(partitions=[groupTest01-4, groupTest01-5, groupTest01-0, groupTest01-2])
Adding newly assigned partitions: groupTest01-2, groupTest01-0, groupTest01-5, groupTest01-4
// customConsumer03
Successfully synced group in generation Generation{generationId=4, memberId='consumer-group06-1-eb0ac20c-5d94-43a7-b7c1-96a561513995', protocol='sticky'}
Notifying assignor about the new Assignment(partitions=[groupTest01-3, groupTest01-6, groupTest01-1])
Adding newly assigned partitions: groupTest01-3, groupTest01-1, groupTest01-6
5.5 offset位移
5.5.1 offset的默认维护位置
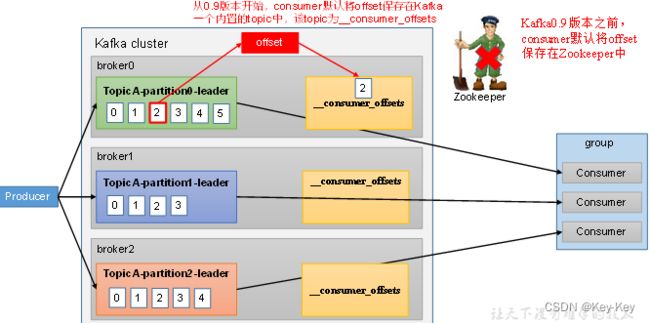
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
kafka0.9版本之前,consumer默认将offset保存在zookeeper,从0.9版本开始,consumer默认将offset保存在kafka一个内置的topic中,该topic为__consumer_offsets。
在consumer_offsets主题里面采用key+value的方式存储数据。key是groupid+topic+分区号,value是当前offset的值。每个一段时间,kafka内部就会对这个topic进行compact(压实),即每个groupid+topic+分区号就保留最新的数据。
1、消费offset案例
1)设计思想:
__consumer_offsets为kafka中的topic,那就可以通过消费者进行消费。
2)在配置文件config/consumer.properties中添加配置exclude.internal.topics=false,默认就是true,表示不能消费系统主题。我们为了查看系统主题数据,需要将参数修改为false。
[atguigu@hadoop102 kafka]$ vim /opt/module/kafka/config/consumer.properties
exclude.internal.topics=false
3)在命令行创建一个新的topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --create --topic atguigu --bootstrap-server hadoop102:9092 --partitions 2 --replication-factor 2
4)启动生产者向主题atguigu中生产数据
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh --topic atguigu --bootstrap-server hadoop102:9092
5)启动消费者消费主题atguigu中生产数据
[atguigu@hadoop104 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic atguigu --group test
注意:指定消费者组的名称,能够更好的观察数据存储位置(key->groupid+topic+分区号)
6)启动消费者消费主题__consumer_offsets
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server hadoop102:9092 --consumer.config config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning
7)消费到的数据
[test,atguigu,1]::OffsetAndMetadata(offset=7, leaderEpoch=Optional[0], metadata=, commitTimestamp=1622442520203, expireTimestamp=None)
[test,atguigu,0]::OffsetAndMetadata(offset=8, leaderEpoch=Optional[0], metadata=, commitTimestamp=1622442520203, expireTimestamp=None)
5.5.2 自动提交offset
1、自动提交offset图示
为了使我们能够专注于自己的业务逻辑,kafka提供了自动提交offset的功能。
自动提交offset的相关参数:
1)enable.auto.commit:是否开启自动提交offset功能,默认是true
2)auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s

2、编写代码
1)需要用到的类
kafkaconsumer:需要创建一个消费者对象,用来消费数据
consumerconfig:获取所需的一系列配置参数
consumerrecord:每条数据都要封装成一个consumerrecord对象
为了使我们能够专注于自己的业务逻辑,kafka提供了自动提交offset的功能。
2)消费者自动提交offset
package com.atguigu.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class CustomConsumer {
public static void main(String[] args) {
// 1. 创建kafka消费者配置类
Properties properties = new Properties();
// 2. 添加配置参数
// 添加连接
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
// 配置消费者组
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
// 是否自动提交offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 提交offset的时间周期,默认5s,
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 3. 创建kafka消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
// 4. 设置消费主题 形参是列表
consumer.subscribe(Arrays.asList("first"));
// 5. 消费数据
while (true){
// 6. 读取消息
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
// 7. 输出消息
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.value());
}
}
}
}
5.5.3 手动提交offset
1、手动提交offset图示

虽然自动提交offset十分简单便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此kafka还提供了手动提交offset的api。
手动提交offset的方法有两种:分别是commitsync(同步提交)和commitasync(异步提交)。两者的相同点是,都会将本次提交的一批数据最高的偏移量提交;不同点是,同步提交阻塞当前进程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而异步提交则没有失败重试机制,故有可能提交失败。
1)commitsync(同步提交):必须等待offset提交完毕,再去消费下一批数据。
2)commitasync(异步提交):发送完提交offset请求后,就开始消费下一批数据。
同步提交offset
由于同步提交offset有失败重试机制,故更加可靠
package com.atguigu.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class CustomConsumerByHand {
public static void main(String[] args) {
// 1. 创建kafka消费者配置类
Properties properties = new Properties();
// 2. 添加配置参数
// 添加连接
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
// 配置消费者组
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
// 是否自动提交offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// 提交offset的时间周期
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 3. 创建kafka消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
// 4. 设置消费主题 形参是列表
consumer.subscribe(Arrays.asList("first"));
// 5. 消费数据
while (true){
// 6. 读取消息
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
// 7. 输出消息
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.value());
}
// 同步提交offset
consumer.commitSync();
}
}
}
异步提交offset
同步提交offset更可靠一些,但是由于其会阻塞当前线程,直到提交成功。因此吞吐量会受到很大的影响。因此更多的情况下,会选用异步提交offset的方式。
package com.atguigu.kafka.consumer;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.util.Arrays;
import java.util.Map;
import java.util.Properties;
public class CustomConsumerByHand {
public static void main(String[] args) {
// 1. 创建kafka消费者配置类
Properties properties = new Properties();
// 2. 添加配置参数
// 添加连接
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
// 配置消费者组
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
// 是否自动提交offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// 提交offset的时间周期
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 3. 创建kafka消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
// 4. 设置消费主题 形参是列表
consumer.subscribe(Arrays.asList("first"));
// 5. 消费数据
while (true){
// 6. 读取消息
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
// 7. 输出消息
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.value());
}
// 异步提交offset
consumer.commitAsync(new OffsetCommitCallback() {
/**
* 回调函数输出
* @param offsets offset信息
* @param exception 异常
*/
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
// 如果出现异常打印
if (exception != null ){
System.err.println("Commit failed for " + offsets);
}
}
});
}
}
}
5.5.4 指定offset消费
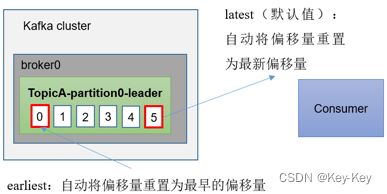
当kafka中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量时(例如该数据已被删除),该怎么办?
1、earliest:自动将偏移量重置为最早的偏移量
2、latest(默认值):自动将偏移量重置为最新偏移量
3、none:如果未找到消费者组的先前偏移量,则向消费者抛出异常
5.5.5 数据漏消费和重复消费分析
1、问题:无论是同步提交还是异步提交offset,都有可能会造成数据的漏消费或者重复消费
2、漏消费:先提交offset后消费,有可能造成数据的漏消费
3、重复消费:而先消费后提交offset,有可能会造成数据的重复消费
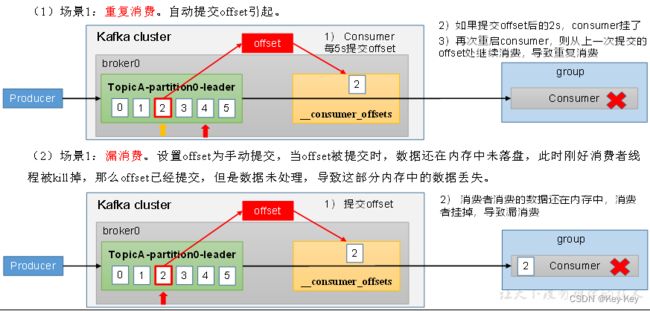
5.6 生产经验之Consumer事务
1、消费者事务
如果想完成Consumer端的精准一次性消费,那么需要kafka消费端将消费过程和提交offset过程做原子绑定。此时我们需要将kafka的offset保存到支持事务的自定义介质(比如mysql)。者部分知识会再后续项目部分涉及。
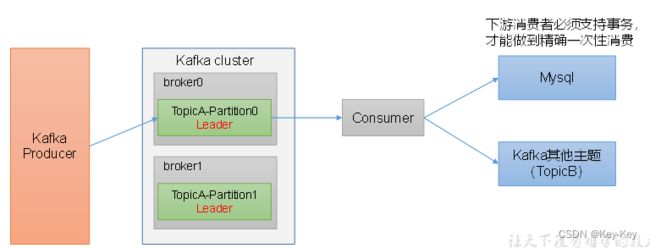
5.7 数据积压(消费者如何提高吞吐量)
1、如果是kafka消费能力不足,则可以考虑增加topic的分区数,并且同时提升消费组的消费者数量,消费者数=分区数。

2、如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数量过少(拉取数据/处理时间<生产速度),使处理的数据小于生产的数据,也会造成数据积压。

| 参数名称 | 描述 |
|---|---|
| fetch.max.bytes | 默认Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受message.max.bytes (broker config)or max.message.bytes (topic config)影响。 |
| max.poll.records | 一次poll拉取数据返回消息的最大条数,默认是500条 |
第 6 章:kafka-eagle监控
kafka-eagle框架可以监控kafka集群的整体运行情况,再生产环境中经常使用。
6.1 kafka准备
1、关闭kafka集群
[atguigu@hadoop102 kafka]$ kafka.sh stop
2、修改kafka启动命令
[atguigu@hadoop102 kafka]$ vim /opt/module/kafka/bin/kafka-server-start.sh
……
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
注意:修改之后在启动kafka之前要分发之其它节点
6.2 安装kafka-eagle
1、上传压缩包kafka-~bin.tar.gz到集群/opt/software目录
[atguigu@hadoop102 software]$ ll
-rw-rw-r--. 1 atguigu atguigu 81074069 4月 19 20:07 kafka-eagle-bin-2.0.8.tar.gz
2、将jar包解压到本地
[atguigu@hadoop102 software]$ tar -zxvf kafka-eagle-bin-2.0.8.tar.gz
3、进入刚才解压的目录,再次将jar包解压到/opt/module/目录下
[atguigu@hadoop102 kafka-eagle-bin-2.0.8]$ tar -zxvf efak-web-2.0.8-bin.tar.gz -C /opt/module/
4、修改kafka-eagle名称为eagle
[atguigu@hadoop102 module]$ mv efak-web-2.0.8/ efak
6.3 配置eagle
1、修改eagle的配置文件system-config.properties
[atguigu@hadoop102 efak]$ vim conf/system-config.properties
######################################
# multi zookeeper & kafka cluster list
# Settings prefixed with 'kafka.eagle.' will be deprecated, use 'efak.' instead
######################################
efak.zk.cluster.alias=cluster1
cluster1.zk.list=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
######################################
# zookeeper enable acl
######################################
cluster1.zk.acl.enable=false
cluster1.zk.acl.schema=digest
cluster1.zk.acl.username=test
cluster1.zk.acl.password=test123
######################################
# broker size online list
######################################
cluster1.efak.broker.size=20
######################################
# zk client thread limit
######################################
kafka.zk.limit.size=32
######################################
# EFAK webui port
######################################
efak.webui.port=8048
######################################
# kafka jmx acl and ssl authenticate
######################################
cluster1.efak.jmx.acl=false
cluster1.efak.jmx.user=keadmin
cluster1.efak.jmx.password=keadmin123
cluster1.efak.jmx.ssl=false
cluster1.efak.jmx.truststore.location=/data/ssl/certificates/kafka.truststore
cluster1.efak.jmx.truststore.password=ke123456
######################################
# kafka offset storage
######################################
cluster1.efak.offset.storage=kafka
######################################
# kafka jmx uri
######################################
cluster1.efak.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi
######################################
# kafka metrics, 15 days by default
######################################
efak.metrics.charts=true
efak.metrics.retain=15
######################################
# kafka sql topic records max
######################################
efak.sql.topic.records.max=5000
efak.sql.topic.preview.records.max=10
######################################
# delete kafka topic token
######################################
efak.topic.token=keadmin
######################################
# kafka sasl authenticate
######################################
cluster1.efak.sasl.enable=false
cluster1.efak.sasl.protocol=SASL_PLAINTEXT
cluster1.efak.sasl.mechanism=SCRAM-SHA-256
cluster1.efak.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka" password="kafka-eagle";
cluster1.efak.sasl.client.id=
cluster1.efak.blacklist.topics=
cluster1.efak.sasl.cgroup.enable=false
cluster1.efak.sasl.cgroup.topics=
cluster2.efak.sasl.enable=false
cluster2.efak.sasl.protocol=SASL_PLAINTEXT
cluster2.efak.sasl.mechanism=PLAIN
cluster2.efak.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="kafka" password="kafka-eagle";
cluster2.efak.sasl.client.id=
cluster2.efak.blacklist.topics=
cluster2.efak.sasl.cgroup.enable=false
cluster2.efak.sasl.cgroup.topics=
######################################
# kafka ssl authenticate
######################################
cluster3.efak.ssl.enable=false
cluster3.efak.ssl.protocol=SSL
cluster3.efak.ssl.truststore.location=
cluster3.efak.ssl.truststore.password=
cluster3.efak.ssl.keystore.location=
cluster3.efak.ssl.keystore.password=
cluster3.efak.ssl.key.password=
cluster3.efak.ssl.endpoint.identification.algorithm=https
cluster3.efak.blacklist.topics=
cluster3.efak.ssl.cgroup.enable=false
cluster3.efak.ssl.cgroup.topics=
######################################
# kafka sqlite jdbc driver address
######################################
# 配置mysql连接
efak.driver=com.mysql.jdbc.Driver
efak.url=jdbc:mysql://hadoop102:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=你的密码
######################################
# kafka mysql jdbc driver address
######################################
#efak.driver=com.mysql.cj.jdbc.Driver
#efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
#efak.username=root
#efak.password=你的密码
6.4 添加环境变量
[atguigu@hadoop102 kafka]$ sudo vim /etc/profile.d/my_env.sh
# kafkaEfak
export KE_HOME=/opt/module/efak
export PATH=$PATH:$KE_HOME/bin
注意:source /etc/profile
[atguigu@hadoop102 kafka]$ source /etc/profile
6.5 启动eagle
[atguigu@hadoop102 efak]$ bin/ke.sh start
*******************************************************************
* Kafka Eagle Service has started success.
* Welcome, Now you can visit 'http://192.168.202.102:8048/ke'
* Account:admin ,Password:123456
*******************************************************************
* <Usage> ke.sh [start|status|stop|restart|stats] </Usage>
* <Usage> https://www.kafka-eagle.org/
*******************************************************************
注意:启动之前需要先启动zk以及kafka

第 7 章:kafka-kraft模式
7.1 kafka-kraft架构

左图为kafka现有架构,元数据在zookeeper中,运行时动态选举controller,由controller进行kafka集群管理。右图为kraft模式架构(实验性),不再依赖zookeeper集群,而是用三台controller节点代替zookeeper,元数据保存在controller中,由controller直接进行kafka集群管理。
好处是:
1、kafka不再依赖外部框架,而是能够独立运行
2、controller管理集群时,不再需要从zookeeper中先读取数据,集群性能上升
3、由于不依赖zookeeper,集群扩展时不再受到zookeeper读写能力限制
4、controller不再动态选举,而是由配置文件规定。这样我们可以有针对性地加强controller节点的配置,而不是像以前一样对随机controller节点的高负载束手无策。
7.2 kafka-kraft集群部署
1、再次解压一份kafka安装包
[atguigu@hadoop102 software]$ tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
2、重命名为kafka2
[atguigu@hadoop102 module]$ mv kafka_2.12-3.0.0/ kafka2
3、在hadoop102上修改/opt/module/~/server.properties配置文件
[atguigu@hadoop102 kraft]$ vim server.properties
#kafka的角色(controller相当于主机、broker节点相当于从机,主机类似zk功能)
process.roles=broker, controller
#节点ID
node.id=2
#controller服务协议别名
controller.listener.names=CONTROLLER
#全Controller列表
controller.quorum.voters=2@hadoop102:9093,3@hadoop103:9093,4@hadoop104:9093
#不同服务器绑定的端口
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
#broker服务协议别名
inter.broker.listener.name=PLAINTEXT
#broker对外暴露的地址
advertised.Listeners=PLAINTEXT://hadoop102:9092
#协议别名到安全协议的映射
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
#kafka数据存储目录
log.dirs=/opt/module/kafka2/data
4)分发kafka2
4、分发kafka2
atguigu@hadoop102 module]$ xsync kafka2/
注意:
① 在hadoop103和hadoop104上需要对node.id相应改变,值需要和controller.quorum.voters对应。
② 在hadoop103和hadoop104上需要根据各自的主机名称,修改相应的advertised.Listeners地址。
5、初始化集群数据目录
1)首先生成存储目录唯一ID
[atguigu@hadoop102 kafka2]$ bin/kafka-storage.sh random-uuid
J7s9e8PPTKOO47PxzI39VA
2)用该id格式化kafka存储目录(三台节点)
[atguigu@hadoop102 kafka2]$ bin/kafka-storage.sh format -t J7s9e8PPTKOO47PxzI39VA -c /opt/module/kafka2/config/kraft/server.properties
[atguigu@hadoop103 kafka2]$ bin/kafka-storage.sh format -t J7s9e8PPTKOO47PxzI39VA -c /opt/module/kafka2/config/kraft/server.properties
[atguigu@hadoop104 kafka2]$ bin/kafka-storage.sh format -t J7s9e8PPTKOO47PxzI39VA -c /opt/module/kafka2/config/kraft/server.properties
6、启动kafka集群
[atguigu@hadoop102 kafka2]$ bin/kafka-server-start.sh -daemon config/kraft/server.properties
[atguigu@hadoop103 kafka2]$ bin/kafka-server-start.sh -daemon config/kraft/server.properties
[atguigu@hadoop104 kafka2]$ bin/kafka-server-start.sh -daemon config/kraft/server.properties
7、停止kafka集群
[atguigu@hadoop102 kafka2]$ bin/kafka-server-stop.sh
[atguigu@hadoop103 kafka2]$ bin/kafka-server-stop.sh
[atguigu@hadoop104 kafka2]$ bin/kafka-server-stop.sh
7.3 kafka-kraft集群启动停止脚本
1、在/home/atguigu/bin目录下创建文件kf2.sh脚本文件
[atguigu@hadoop102 bin]$ vim kf2.sh
脚本如下:
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------启动 $i Kafka2-------"
ssh $i "/opt/module/kafka2/bin/kafka-server-start.sh -daemon /opt/module/kafka2/config/kraft/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka2-------"
ssh $i "/opt/module/kafka2/bin/kafka-server-stop.sh "
done
};;
esac
2、添加执行权限
[atguigu@hadoop102 bin]$ chmod +x kf2.sh
3、启动集群命令
[atguigu@hadoop102 ~]$ kf2.sh start
4、停止集群命令
[atguigu@hadoop102 ~]$ kf2.sh stop