如何本地部署虚VideoReTalking
环境:
Win10专业版
VideoReTalking
问题描述:
如何本地部署虚VideoReTalking
解决方案:
VideoReTalking是一个强大的开源AI对嘴型工具,它是我目前使用过的AI对嘴型工具中效果最好的一个!它是由西安电子科技大学、腾讯人工智能实验室和清华大学联合开发的。
1.安装git
next一直往下直到完成

安装时所有的选项都默认即可
2.安装Anaconda
conda是一个开源的软件包管理系统和环境管理系统,用于安装多个版本的软件包及其依赖关系,并在它们之间轻松切换。 conda是为 python程序创建的,适用于 Linux,OS X和Windows,也可以打包和分发其他软件。conda分为Anaconda和MiniConda。Anaconda是包含一些常用包的版本,Miniconda则是精简版,一般建议安装Anaconda,本文也以安装Anaconda为例;
anaconda是一个编程语言整合包,有了anaconda你可以更加方便的打库,切换环境,配置环境变量等
 next一直往下直到完成(需要一点时间)
next一直往下直到完成(需要一点时间)

添加环境变量
D:\ProgramData\anaconda3\condabin
安装成功之后,随便打开一个cmd窗口,输入“conda”如果出现的是如下的内容,即表示安装成功,否则就会报错“conda”不是内部或外部命令,也不是可运行的程序
或批处理文件
3.clone主程序到本地
在选定的文件夹空白处,点击鼠标右键,选择“Git Bash Here”,在打开的git命令窗口输入如下的命令:
git clone https://github.com/vinthony/video-retalking.git
主程序下载完成之后,可以关闭该git窗口,这时候在选定的磁盘空间有了一个名为“video-retalking”的文件夹;
4.创建和激活虚拟空间
首先进入到“video-retalking”文件夹中,在文件的路径栏输入“cmd”打开一个命令窗口,先后运行下面两行命令:
conda create -n video_retalking python=3.8
y
conda activate video_retalking
 5.安装ffmpeg
5.安装ffmpeg
在虚拟环境的命令窗口,输入如下的命令,安装FFmpeg:
conda install ffmpeg
6.安装torch和cuda
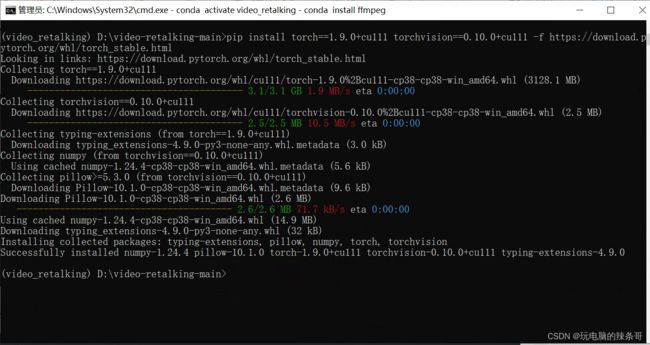
继续运行下面的这行命令,安装特定版本的torch和cuda:
pip install torch1.9.0+cu111 torchvision0.10.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html
这一步由于需要下载的文件比较大,最大的文件有3.1GB,因此你需要耐心等待它的下载和安装完成,具体的速度取决于你当地的网络情况
7.安装依赖组件
在torch和cuda安装结束之后,就可以安装VideoReTalking程序的依赖组件了,命令如下:
pip install -r requirements.txt

pip install torch2.0.0+cu118 torchvision0.15.1+cu118 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
8.需要安装的组件比较多,因此这一步也需要等待一定的时间,具体取决于你的网络情况
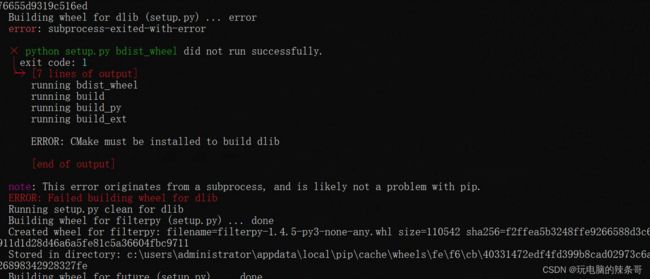
pip install dlib
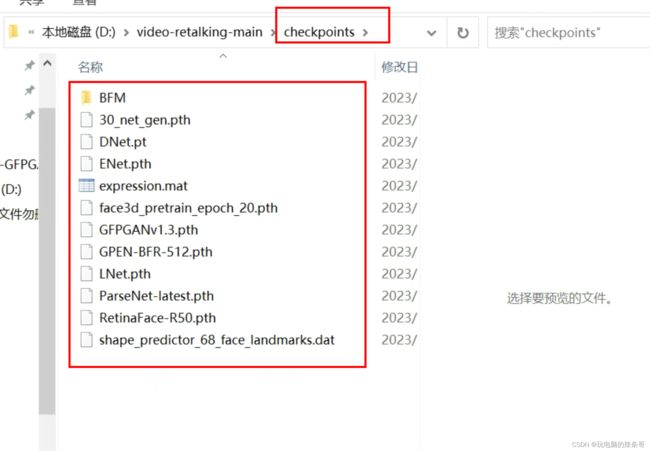
9.下载和安装模型checkpoints
将下面这个文件夹(包含11个模型和1个子文件夹“BFM”)全部下载下来,然后将这个下载下来的checkpoints文件夹放在项目的跟目录中:
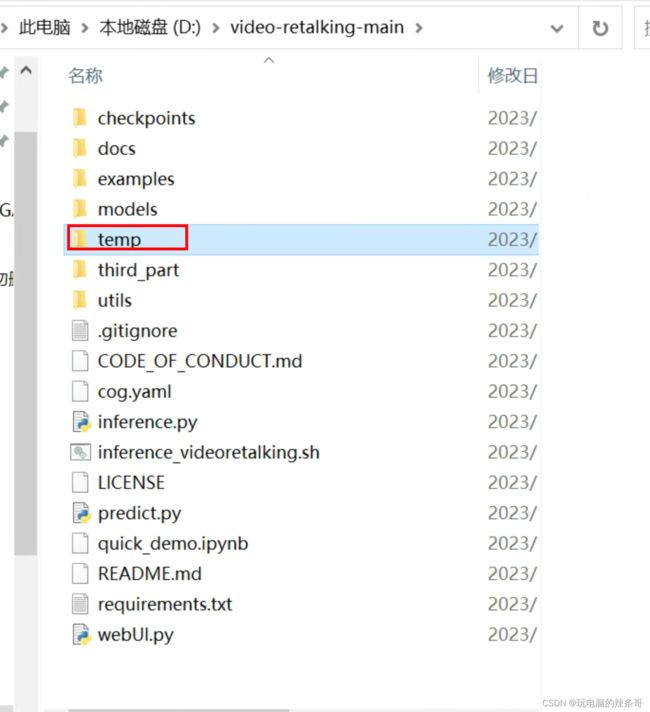
10.使用教程
在项目的根目录,新建一个“temp”文件夹,在temp文件夹中分别新建一个“video”文件夹和“audio”文件夹,分别用来存放用来对嘴型的视频文件和音频文件的临时文件
只需要新建这三个文件夹即可,实际使用中不需要将视频和音频文件先复制到这两个文件夹中,不管你的视频和音频文件在什么位置,系统会自动往这个temp下面的两个文件夹再复制一份
11.运行webui界面
在虚拟环境的状态下,输入如下的命令即可运行webui界面
python webUI.py
如果不在虚拟环境下,则需先激活虚拟环境,即在项目的根目录地址栏输入cmd,打开命令窗口,输入如下的命令激活虚拟环境:
conda activate video_retalking
报错
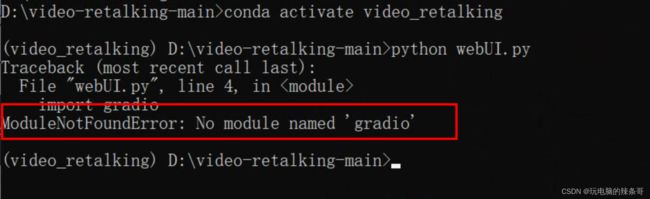 12.安装gradio
12.安装gradio
pip install gradio
13.运行python webUI.py
 14.http://127.0.0.1:7860
14.http://127.0.0.1:7860
15.项目第一次运行的时候还会下载几个小模型文件,体积不大,耐心等待即可!第二次之后运行就不需要再下载模型文件了!
16.如果不想每次都手动激活虚拟环境,可以下载下面的bat文件,将它放在根目录,每次使用的时候双击该bat文件即可运行webui页面@
频不宜过长,生成视频会循环使用源视频,无需上传长视频
视频为标准MP4格式、视频中只有一张人脸、每帧都要有人脸、人脸清晰可识别,人脸不过过大
\VideoReTalking\python.exe inference.py --face examples/face/1.mp4 --audio examples/audio/1.wav --outfile results/1_1.mp4
python inference.py --face examples/face/1.mp4 --audio examples/audio/1.wav --outfile results/1_1.mp4
参数解释
基础参数设置base_options.py
参数类型默认值解释
–name str ‘face_recon’ 实验名称,决定样本和模型存储的位置
–gpu_ids str ‘0’ GPU的ID,例如:0、0,1,2、0,2。使用-1表示CPU
–checkpoints_dir str ‘./checkpoints’ 模型存储的目录
–vis_batch_nums float 1 用于可视化的图像批次数
–eval_batch_nums float inf 用于评估的图像批次数,设置为inf表示所有图像都参与评估
–use_ddp bool True 是否使用分布式数据并行
–ddp_port str ‘12355’ DDP端口
–display_per_batch bool True 是否使用批次显示损失
–add_image bool True 是否将图像添加到Tensorboard中
–world_size int 1 分布式数据并行的总批次数
–model str ‘facerecon’ 选择要使用的模型
–epoch str ‘latest’ 要加载的模型的训练轮数,设置为’latest’表示使用最新的缓存模型
–verbose bool 如果指定,则打印更多调试信息
–suffix str ‘’ 自定义后缀,将添加到opt.name中,例如:{model}_{netG}_size{load_size}
参数名
类
型
默认值描述
DNet_path str ‘checkpoints/DNet.pt’ DNet模型的路径
LNet_path str ‘checkpoints/LNet.pth’ LNet模型的路径
ENet_path str ‘checkpoints/ENet.pth’ ENet模型的路径
face3d_net_path str ‘checkpoints/face3d_pretrain_epoch_20.pth’ face3d模型的路径
face str None 包含要使用的人脸的视频/图像的文件路径,此参数必填
audio str None 要用作原始音频源的视频/音频文件的文件路径,此参数必填
exp_img str ‘neutral’ 表情模板。可以是’neutral’,‘smile’或图像路径。默认为’neutral’
outfile str None 要保存结果视频的路径
fps float 25.0 只有当输入为静态图像时可以指定的帧率,默认为25.0
pads list [0, 20, 0, 0] 填充(上、下、左、右)。请确保至少包含下巴区域
face_det_batch_size int 4 人脸检测的批处理大小
LNet_batch_size int 16 LNet的批处理大小
img_size int 384 图像的大小(宽度和高度相等)
crop list [0, -1, 0, -1]
将视频裁剪为较小的区域(上、下、左、右)。在resize_factor和
rotate参数之后应用。如果有多个人脸,这很有用。 -1表示根据高
度、宽度自动推断值
box list [-1, -1, -1, -1]
为人脸指定一个固定的边界框。如果人脸检测失败,请仅在万不得已
时使用此选项。仅在人脸几乎不移动时有效。 语法:(上、下、左、
右)
nosmooth bool False 在短时间窗口内阻止平滑人脸检测
static bool False 指定输入是否为静态图像
up_face str ‘original’ 人脸朝向的方向。可以是’original’或其他用户指定的方向
one_shot bool False 一次处理整个视频而不是逐帧处理
without_rl1 bool False 不使用相对l1损失
tmp_dir str ‘temp’ 保存临时结果的文件夹路径
re_preprocess bool False 重新预处理视频(例如,检测新的人脸)
模型训练参数设置train_options.py,训练模型根据实际情况调整。
data_root str ./ 数据集根目录
flist str datalist/train
/masks.txt 训练集掩膜文件名列表
batch_size int 32 批处理大小
dataset_mode str flist 选择数据集加载方式。[None
serial_batches bool 如果为True,按顺序获取图像以形成批次;否则随机获取图像。
num_threads int 4 加载数据的线程数
max_dataset_size int inf 数据集允许的最大样本数。如果数据集目录包含的样本数超过max_dataset_size,则仅加
载子集。
preprocess str shift_scale_rot_flip 加载时图像的缩放和裁剪方式。[shift_scale_rot_flip
use_aug bool True 是否使用数据增强
验证参数数据类型默认值解释说明
flist_val str datalist/val/masks.txt 验证集掩膜文件名列表
batch_size_val int 32 验证集的批处理大小
可视化参数数据类型默认值解释说明
display_freq int 1000 在屏幕上显示训练结果的频率
print_freq int 100 在控制台上显示训练结果的频率
网络保存和加载参数数据类型默认值解释说明
save_latest_freq int 5000 保存最新结果的频率
save_epoch_freq int 1 在每个epoch结束时保存检查点的频率
evaluation_freq int 5000 评估的频率
save_by_iter bool 是否按迭代保存模型
continue_train bool 继续训练:加载最新模型
epoch_count int 1 起始epoch计数,我们按<epoch_count>,<epoch_count>+<save_latest_freq>,…保存模型
phase str train 训练、验证、测试等
pretrained_name str None 从其他检查点继续训练
训练参数数据类型默认值解释说明
n_epochs int 20 初始学习率的epoch数
lr float 0.0001 Adam的初始学习率
lr_policy str step 学习率策略。[linear
lr_decay_epochs int 10 每lr_decay_epochs个epoch乘以一个gamma
脸部对焦参数配置facerecon_model.py,这些参数默认即可。
网络结构参数数据类型默认值解释说明
net_recon str ‘resnet50’ 网络结构
init_path str ‘checkpoints/init_model/resnet50-0676ba61.pth’ 初始化路径
use_last_fc bool False 是否对最后一个全连接层进行零初始化
bfm_folder str ‘BFM’ BFM文件夹路径
bfm_model str ‘BFM_model_front.mat’ BFM模型
渲染器参数参数数据类型默认值解释说明
focal float 1015. 焦距
center float 112. 中心点
camera_d float 10. 相机参数d
z_near float 5. 近截面
z_far float 15. 远截面
训练参数
数据类
型
默认值解释说明
net_recog str ‘r50’ 人脸识别网络结构
net_recog_path str ‘checkpoints/recog_model/ms1mv3_arcface_r50_fp16
/backbone.pth’ 人脸识别网络的权重文件路径
use_crop_face bool False 是否使用裁剪掩码来计算照片损失
use_predef_M bool False 是否使用预定义的M矩阵来处理预测的人脸特征 (M矩阵
用于三维形状预测)
数据增强参数参数数据类型默认值解释说明
shift_pixs float 10.0 像素平移大小
scale_delta float 0.1 尺度缩放因子的变化范围
rot_angle float 10.0 旋转角度的变化范围 (单位:度)
损失权重参数数据类型默认值解释说明
w_feat float 0.2 特征损失权重
损失权重参数数据类型默认值解释说明
w_color float 1.92 颜色损失权重
w_reg float 3.0e-4 形状正则化损失权重
w_id float 1.0 身份正则化损失权重
w_exp float 0.8 表情正则化损失权重
w_tex float 1.7e-2 纹理正则化损失权重
w_gamma float 10.0 Gamma矫正损失权重
w_lm float 1.6e-3 关键点坐标损失权重
w_reflc float 5.0 反照率损失权重
其他使用方法
表情控制参数操作,可以通过添加以下参数来控制表情:
参数解释
–exp_img 预定义的表情模板。默认为"neutral"(中性表情)。可以选择"smile"(微笑)或提供一个图片路径。
–up_face 可以选择"surprise"(惊讶)或"angry"(愤怒)来使用 GANimation 修改上半部分脸部的表情。
17.经测试,源视频识别错误将导致失败。具体原因官方没有详细说明,以下为网友总结:
1、资源问题:
视频不宜过长,生成视频会循环使用源视频,不用担心视频短的问题。
2、视频为标准MP4格式、视频中只有一张人脸、每帧都要有人脸、人脸清晰可识别,人脸不过过大,几乎半个屏幕。人脸不可过度AI化。
音频没有太多要求,发音清晰即可。
3、只支持N卡。若您的配置过低也会造成卡住的情况。
4、以上无法解决问题请使用网盘中的案例视频进行测试。