机器学习平台建设(六)
四、OpenPAI
前文介绍了机器学习平台的功能以及建设机器学习平台要考虑的因素。本节会介绍OpenPAI,即微软的开源机器学习平台。它可用于企业私有部署,也可部署在云平台中。它解决了建模训练时的算力和资源管理的问题。OpenPAI的开发很活跃,问题也能得到及时响应,还在积极开发新功能中。
OpenPAI代码及文档地址:https://github.com/Microsoft/pai
特点
OpenPAI是为数不多的用于私有部署的机器学习平台。在微软内部管理了几百块GPU,应用规模上得到了很好的验证。同时支持数台服务器的小规模部署。
OpenPAI和Visual Studio、Visual Studio Code的工具 AI工具集成在了一起,利用这些强大的集成开发环境同时,也可以方便的提交并管理训练任务、数据资源。
OpenPAI是通用的机器学习平台。理论上支持任何计算密集型,甚至存储密集型的任务。通过预先配置的Docker,已经支持了包括TensorFlow,Keras,CNTK等流行的计算框架,并支持框架自带的分布式训练任务。硬件上已支持GPU、内存、CPU的分配,通过扩展,还可以支持更多的硬件类型。
架构
OpenPAI基于Kubernetes的容器化,Yarn的资源分配,并集成了HDFS作为存储管理等开源组件构建的通用的机器学习平台。用户提交作业(即机器学习训练任务)后,就会自动分配资源,创建Docker实例,并运行指定的命令。因此,OpenPAI是一个通用的算力管理平台。通过提供一系列预构建好的Docker,OpenPAI可以方便的执行TensorFlow, Keras,CNTK等流行的机器学习框架的训练任务。
OpenPAI将复杂性包装了起来,只有master和worker两种角色。Master提供了web api和界面,以及Kubernetes的master节点等;worker用于运行实际计算的docker实例。
下图为OpenPAI的架构示意图。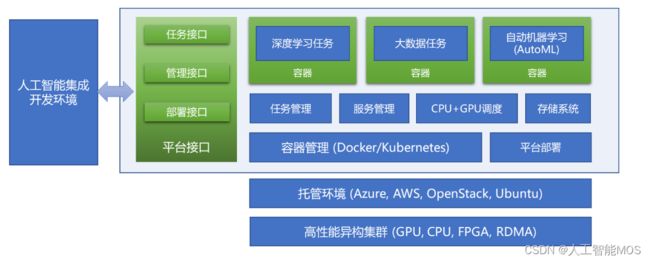
算力管理
OpenPAI提供了作业的队列管理。另外,通过自己配置Docker,还能搭建出Jupyter Notebook这样的交互式开发训练环境。
在其队列管理中,用户只需要声明每个作业需要的资源类型,给定所需的docker镜像路径,代码位置等信息,即可等待系统分配资源,并运行训练作业。
OpenPAI的作业支持机器学习框架的分布式运算。如,可指派两个实例作为参数服务器,另外4个实例作为计算节点。OpenPAI开始执行此作业时,会先保留足够的资源,然后启动这些节点,开始分布式计算。在节点启动后,OpenPAI即可知道所有节点的IP、ssh端口等信息,并将这些信息通过环境变量或命令行参数的方式传给运行的脚本,从而让每个节点能发现其它所有节点。
在多用户的情况下,OpenPAI通过Virtual Cluster来解决资源分配问题。虚拟 Cluster可理解为虚拟的集群。不同的Virtual Cluster有不同的资源配额,可以将用户分配到一个或多个Virtual Cluster中。如果某个Virtual Cluster使用的资源超了,并且其它Virtual Cluster有空闲资源,则OpenPAI会使用空闲资源来运行。通过这样的管理,能实现多种场景。如:两个小团队各分配一个50%资源的Virtual 簇。团队A每天都有训练任务在持续进行,对资源的需求是越多越好。而团队B的资源使用是突发性的,一旦有需求,希望其能尽快完成。平时,团队A会使用团队B的空闲资源来加速自己的训练,一旦团队B有了突发任务,团队A占用团队B的训练任务就会被停下来,让团队B的任务先训练。又如,将生产需要的模型训练和试验需要的模型训练都在一个集群中进行,各用一个Virtual 簇。给生产分配100%的资源,而模型试验分配0%的资源。这样,一旦生产资源有空闲就可用于试验,但会优先保障生产资源。
作业
提交给OpenPAI的每个训练任务,称为作业(Job)。作业由一个json配置文件描述。通过Visual Studio Tools for AI以及 Visual Studio Code Tools for AI可以方便的提交训练作业和最新的代码。
作业配置
作业的json文件包含了训练任务的基本信息。下文是简化了的任务示例,对主要的参数进行介绍,以方便理解OpenPAI的用法。
-
普通作业
{ "jobName": "mnist_024", "image": "openpai/pai.example.tensorflow", "codeDir": "hdfs://\:\
jobName:这是每个作业的名称,需要全局唯一。
image:这是作业运行的docker镜像的地址。示例中是OpenPAI预构建的TensorFlow的镜像地址。
codeDir:它表示了将要运行的代码位置。在docker启动后,会将此目录的内容拷贝到docker中的/root下。例如本例中,会将mnist目录内容拷贝到docker中的/root/mnist下。
taskRoles:这是作业需要的docker实例的定义模板数组。数组中每个项目是一个docker模板的定义。
taskNumber:这个docker模板在实例化时的数量,即这个模板创建几个docker实例。在单机运行的docker实例中,这个数字应为1。
cpuNumber、memoryMB、gpuNumber:对应于其名字,分别为CPU、内存、GPU的数量。这为当前任务模板定义了要使用资源的规格。OpenPAI会根据这些信息来分配计算节点。
command:这是Docker实例启动后,运行的命令。这条命令运行结束后,Docker会被销毁。如果命令行返回值不为0,任务会被标记为失败。
-
分布式作业
{ "jobName": "mnist_024", "image": "openpai/pai.example.tensorflow", "codeDir": "hdfs://\:\
这是利用TensorFlow分布式训练功能的作业配置。此配置会分配两个参数服务器以及两个计算节点。分布式作业的具体内容和普通作业类似,但会有多个taskRoles中的节点。它们会被分配不同的资源。可以看到taskNumber数量为2,表示每种角色需要两个docker实例。
在command参数中可以看到有一些$开头的变量。这些是OPENPAI内置变量。可以将分布式系统各个角色的主机地址、ssh端口传给所有节点。这样,在任何分布式组网的系统中,都能够拿到所有的节点信息。
提交作业
Visual Studio和Visual Studio Code中的插件管理可以找到Tools for AI插件。的工具 AI是微软为机器学习准备的扩展。配合Visual Studio和Visual Studio Code的集成开发环境,为机器学习开发提供了更强大的支持。
Tools for AI其中一项功能就是远程训练任务管理,它支持OpenPAI作为远程服务器,能够提交、管理任务,管理存储。具体使用方法可参考OpenPAI的官方文档。
下图为Visual Studio中OpenPAI的任务提交界面。
下图为Visual Studio中OpenPAI的作业管理界面。
下图为Visual Studio中OpenPAI的存储管理界面。
下图为Visual Studio Code中OpenPAI的作业管理界面。
下图为Visual Studio Code中OpenPAI的存储管理界面。
运维
OpenPAI可以管理大规模的GPU平台,提供了负载、服务器健康等多种工具。通过运维工具,能够观察集群的负载情况,找到集群瓶颈。另外,还能细粒度的看到某台服务器的负载情况,了解每台服务器的健康状况。通过OpenPAI平台,能够看到每个组件和每个作业的日志文件,进行更详细的分析。
通过OpenPAI的web界面,也可以提交、管理训练作业。
下图为OpenPAI的集群仪表盘。
下图为OpenPAI的服务器列表。
下图为某台服务器的负载情况