自然语言处理中的词云生成
一.词云的介绍
自然语言处理中的词云技术是文本可视化的一种形式,用于展示文本数据中词语的频率分布。以下是词云在自然语言处理中的基本介绍和发展:
起源和发展: 词云的概念最初来源于信息可视化领域,用于将文本中的关键词以视觉方式呈现。在自然语言处理中,词云得到了广泛的应用,特别是在文本分析、舆情分析、关键词提取等任务中。
工作原理: 词云生成的基本原理是通过文本中每个词的频率来确定词语的大小,频率高的词显示更大,频率低的词显示更小。一般来说,生成词云的过程包括文本的分词、词频统计和可视化展示。
文本清洗和预处理: 为了生成有意义的词云,需要对文本进行清洗和预处理。这包括去除停用词、标点符号,进行分词等。清洁的文本有助于更准确地反映文本的主题和关键词。
技术工具: Python中的WordCloud库是一个常用的工具,用于生成词云。此外,其他数据可视化库如Matplotlib、Seaborn等也可以与词云生成库结合使用。
应用领域: 词云技术在自然语言处理中广泛应用于文本可视化、舆情分析、主题分析、关键词提取等任务。它为用户提供了直观、易懂的方式来了解文本数据的重要特征。
发展趋势: 随着自然语言处理和数据可视化技术的不断发展,词云技术也在不断演进。近年来,一些先进的可视化方法和工具被引入,使得生成更具交互性和信息密度的词云成为可能。
总体而言,词云作为一种简单而直观的文本可视化工具,对于初步了解文本数据的关键信息非常有用。然而,在更复杂的文本分析任务中,更先进的自然语言处理技术和可视化方法可能被采用。
二.基本步骤
词云是一种可视化技术,常用于展示文本数据中词语的频率分布。在自然语言处理中,词云生成可以通过以下步骤完成:
1.1 文本数据处理: 首先,需要准备文本数据。这可以是一段文章、评论、新闻等文本内容。确保文本数据已经被清理、分词,并去除了停用词(常见但无实际意义的词语)。
1.2 词频统计: 对处理后的文本进行词频统计,计算每个词语在文本中的出现频率。这可以通过简单的计数或使用专业的自然语言处理库进行。
1.3 生成词云图: 使用词云生成工具或库,将词频统计结果转换为可视化的词云图。常用的工具包括Python中的WordCloud库。
1.4 调整参数: 根据需求,可以调整词云生成的参数,例如字体、颜色、形状等。这有助于生成更具吸引力和表现力的词云图。
1.5 可视化展示: 将生成的词云图进行可视化展示。这可以通过将词云嵌入到网页、报告中,或直接显示在应用程序中。
三.案例分析
相关数据集如下链接
https://download.csdn.net/download/qq_37977007/88767801
# 1.导入模块包
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# 2.创建停用词的列表
stopwords = [line.strip() for line in open('english_stopwords.txt', 'r', encoding='utf-8').readlines()]
# 3.对句子进行分词
def seg_sentence(sentence):
words_sentence = jieba.cut(sentence.strip())
outstr = ''
for word_sentence in words_sentence:
if word_sentence not in stopwords:
if word_sentence != '\t':
outstr = outstr + word_sentence
outstr = outstr + " "
return outstr
if __name__ == "__main__":
# 4.读取文本,对文本的句子进行分词
inputs = open('wordcloud.txt', 'r', encoding='utf8')
outputs = open('output.txt', 'w')
for line in inputs:
line_Seg = seg_sentence(line)
outputs.write(line_Seg)
outputs.close()
inputs.close()
# 5.调用词云库构建词云,保存结果
wordcloud = open('output.txt', 'r')
mytext = wordcloud.read()
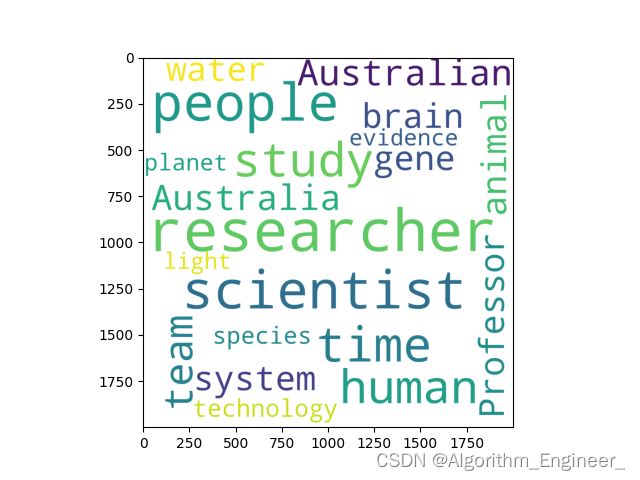
wordcloud = WordCloud(width=2000,height=2000,max_words=20,min_word_length=4, background_color="white").generate(mytext)
plt.imshow(wordcloud)
plt.show()
plt.savefig('result.png')
plt.axis('off')
四.词云中的参数介绍
在生成词云时,通常可以设置一些参数来调整词云的外观和生成方式。以下是一些常见的词云参数及其介绍:
width和height:
介绍: 指定词云图的宽度和高度。
示例: WordCloud(width=800, height=400)
background_color:
介绍: 指定词云的背景颜色。
示例: WordCloud(background_color="white")
max_words:
介绍: 指定词云中显示的最大单词数量。
示例: WordCloud(max_words=100)
collocations:
介绍: 控制是否考虑词汇搭配(collocations),即词语之间的共现关系。
示例: WordCloud(collocations=False)
stopwords:
介绍: 指定停用词列表,这些词将被排除在词云之外。
示例: WordCloud(stopwords={"the", "and", "is"})
font_path:
介绍: 指定用于词云的字体文件路径。
示例: WordCloud(font_path="path/to/font.ttf")
max_font_size:
介绍: 控制词云中最大字体的大小。
示例: WordCloud(max_font_size=50)
min_font_size:
介绍: 控制词云中最小字体的大小。
示例: WordCloud(min_font_size=10)
random_state:
介绍: 用于控制词云生成的随机性,设置相同的值可以得到相同的输出。
示例: WordCloud(random_state=42)
mask:
介绍: 指定用作词云形状的蒙版图像,词云将在该形状内生成。
示例: WordCloud(mask=mask_image)
这只是一些常见的参数,具体使用时可以根据需要调整。不同的词云生成库可能有不同的参数设置,具体参考相应库的文档。
五.词云相关的官方代码如下
# coding=utf-8
# Author: Andreas Christian Mueller
' xmlns="http://www.w3.org/2000/svg"'
' width="{}"'
' height="{}"'
'>'
.format(
width * self.scale,
height * self.scale
)
)
# Embed font, if requested
if embed_font:
# Import here, to avoid hard dependency on fonttools
import fontTools
import fontTools.subset
# Subset options
options = fontTools.subset.Options(
# Small impact on character shapes, but reduce size a lot
hinting=not optimize_embedded_font,
# On small subsets, can improve size
desubroutinize=optimize_embedded_font,
# Try to be lenient
ignore_missing_glyphs=True,
)
# Load and subset font
ttf = fontTools.subset.load_font(self.font_path, options)
subsetter = fontTools.subset.Subsetter(options)
characters = {c for item in self.layout_ for c in item[0][0]}
text = ''.join(characters)
subsetter.populate(text=text)
subsetter.subset(ttf)
# Export as WOFF
# TODO is there a better method, i.e. directly export to WOFF?
buffer = io.BytesIO()
ttf.saveXML(buffer)
buffer.seek(0)
woff = fontTools.ttLib.TTFont(flavor='woff')
woff.importXML(buffer)
# Create stylesheet with embedded font face
buffer = io.BytesIO()
woff.save(buffer)
data = base64.b64encode(buffer.getbuffer()).decode('ascii')
url = 'data:application/font-woff;charset=utf-8;base64,' + data
result.append(
''
.format(
font_family,
font_weight,
font_style,
url
)
)
# Select global style
result.append(
''
.format(
font_family,
font_weight,
font_style
)
)
# Add background
if self.background_color is not None:
result.append(
'
' width="100%"'
' height="100%"'
' style="fill:{}"'
'>'
''
.format(self.background_color)
)
# Embed image, useful for debug purpose
if embed_image:
image = self.to_image()
data = io.BytesIO()
image.save(data, format='JPEG')
data = base64.b64encode(data.getbuffer()).decode('ascii')
result.append(
'
' width="100%"'
' height="100%"'
' href="data:image/jpg;base64,{}"'
'/>'
.format(data)
)
# For each word in layout
for (word, count), font_size, (y, x), orientation, color in self.layout_:
x *= self.scale
y *= self.scale
# Get text metrics
font = ImageFont.truetype(self.font_path, int(font_size * self.scale))
(size_x, size_y), (offset_x, offset_y) = font.font.getsize(word)
ascent, descent = font.getmetrics()
# Compute text bounding box
min_x = -offset_x
max_x = size_x - offset_x
max_y = ascent - offset_y
# Compute text attributes
attributes = {}
if orientation == Image.ROTATE_90:
x += max_y
y += max_x - min_x
transform = 'translate({},{}) rotate(-90)'.format(x, y)
else:
x += min_x
y += max_y
transform = 'translate({},{})'.format(x, y)
# Create node
attributes = ' '.join('{}="{}"'.format(k, v) for k, v in attributes.items())
result.append(
'
' transform="{}"'
' font-size="{}"'
' style="fill:{}"'
'>'
'{}'
''
.format(
transform,
font_size * self.scale,
color,
saxutils.escape(word)
)
)
# TODO draw contour
# Complete SVG file
result.append('')
return '\n'.join(result)
def _get_bolean_mask(self, mask):
"""Cast to two dimensional boolean mask."""
if mask.dtype.kind == 'f':
warnings.warn("mask image should be unsigned byte between 0"
" and 255. Got a float array")
if mask.ndim == 2:
boolean_mask = mask == 255
elif mask.ndim == 3:
# if all channels are white, mask out
boolean_mask = np.all(mask[:, :, :3] == 255, axis=-1)
else:
raise ValueError("Got mask of invalid shape: %s" % str(mask.shape))
return boolean_mask
def _draw_contour(self, img):
"""Draw mask contour on a pillow image."""
if self.mask is None or self.contour_width == 0:
return img
mask = self._get_bolean_mask(self.mask) * 255
contour = Image.fromarray(mask.astype(np.uint8))
contour = contour.resize(img.size)
contour = contour.filter(ImageFilter.FIND_EDGES)
contour = np.array(contour)
# make sure borders are not drawn before changing width
contour[[0, -1], :] = 0
contour[:, [0, -1]] = 0
# use gaussian to change width, divide by 10 to give more resolution
radius = self.contour_width / 10
contour = Image.fromarray(contour)
contour = contour.filter(ImageFilter.GaussianBlur(radius=radius))
contour = np.array(contour) > 0
contour = np.dstack((contour, contour, contour))
# color the contour
ret = np.array(img) * np.invert(contour)
if self.contour_color != 'black':
color = Image.new(img.mode, img.size, self.contour_color)
ret += np.array(color) * contour
return Image.fromarray(ret)