第十三章RNN网络样本的生成方法
RNN网络样本的生成:
神经网络的输入采用的是向量,循环神经网络、LSTM网络也是一个时间序列,这个时间序列怎么进行编码?
1.生成窗口数据,并转化为列表
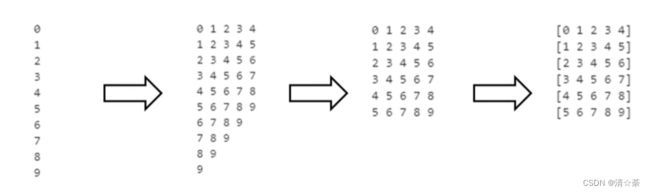
在本章节中,我们将模拟循环神经网络的样本生成方法。首先我们模拟生成一个序列数据然后将数据转变为窗口数据并剔除不完整的数据,最终转化为列表。
代码实现:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
# 生成序列数据
dataset = tf.data.Dataset.range(10)#0~9共10个数生成的数据。
for val in dataset:
print(val.numpy())
# 获得窗口数据,窗口大小为5
dataset = tf.data.Dataset.range(10)
dataset = dataset.window(5, shift=1)#加窗方法,窗口大小为5,shift序列每次移动一个数据,5就是指每1个子序列是5个数
for window_dataset in dataset:
for val in window_dataset:
print(val.numpy(), end=" ")#越往后移数据越少
print()
结果如下:
0 1 2 3 4
1 2 3 4 5
2 3 4 5 6
3 4 5 6 7
4 5 6 7 8
5 6 7 8 9
6 7 8 9
7 8 9
8 9
9
# 去掉不完整的数据
dataset = tf.data.Dataset.range(10)
dataset = dataset.window(5, shift=1, drop_remainder=True)#窗口设置为5个数,drop_reminder设置为True,表示遍历的时候5个数遍历完成但是剩下的数据并不丢掉,每滑动1个数,如果数据不够5个数,从窗口已经划过的这个数里面,从前往后补充。
for window_dataset in dataset:
for val in window_dataset:
print(val.numpy(), end=" ")
print()
得到的每个子序列等长。
结果如下:
0 1 2 3 4
1 2 3 4 5
2 3 4 5 6
3 4 5 6 7
4 5 6 7 8
5 6 7 8 9
# 转为numpy列表
dataset = tf.data.Dataset.range(10)
dataset = dataset.window(5, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(5))
for window in dataset:
print(window.numpy())
[0 1 2 3 4]
[1 2 3 4 5]
[2 3 4 5 6]
[3 4 5 6 7]
[4 5 6 7 8]
[5 6 7 8 9]
2.模拟生成特征和标签,并打乱
神经网络的输入数据集通常对应了特征数据和标签,所以我们在这里将数据划分。另外神经网络的输入数据序列不一定是有序的,所以我们在此处将序列打散。
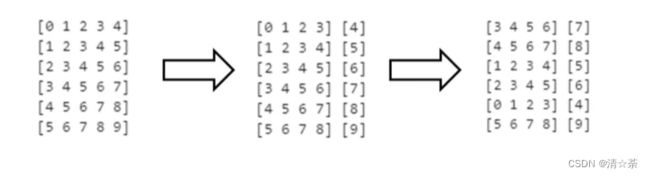
用flat_map方法,加上一个匿名函数,把窗口分成两部分。
flat_map和map方法的功能就是让5个数据作为一批,其中这个五个数据前四个数据作为X,第五个数据作为Y。
# 打散数据
dataset = tf.data.Dataset.range(10)
dataset = dataset.window(5, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(5))
dataset = dataset.map(lambda window: (window[:-1], window[-1:]))
for x,y in dataset:
print(x.numpy(), y.numpy())
[0 1 2 3] [4]
[1 2 3 4] [5]
[2 3 4 5] [6]
[3 4 5 6] [7]
[4 5 6 7] [8]
[5 6 7 8] [9]
dataset = tf.data.Dataset.range(10)
dataset = dataset.window(5, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(5))#把序列改造成样本,调用匿名函数lambda。
dataset = dataset.map(lambda window: (window[:-1], window[-1:]))
dataset = dataset.shuffle(buffer_size=10)#shuffle方法就是把样本集中的数据顺序打乱。
for x,y in dataset:
print(x.numpy(), y.numpy())
[3 4 5 6] [7]
[4 5 6 7] [8]
[1 2 3 4] [5]
[2 3 4 5] [6]
[0 1 2 3] [4]
[5 6 7 8] [9]
3.设置数据批量
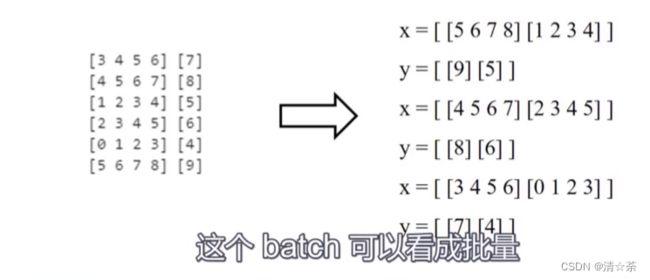
在神经网络训练的过程中,我们通常不会一次性采取全批量数据进行训练,通常是将整个数据集分为若千个batch,我们使用的是小批量的数据生成一个batch。所以我们在此处将两个数据生成一个batch。
# 设置数据批量,每两个数据为一批次,把数据列表转为数组。
dataset = tf.data.Dataset.range(10)
dataset = dataset.window(5, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(5))
dataset = dataset.map(lambda window: (window[:-1], window[-1:]))
dataset = dataset.shuffle(buffer_size=10)
for x,y in dataset:#数据分批,把两个数据作为一批。
print("x = ", x.numpy())
print("y = ", y.numpy())
x = [[5 6 7 8]
[1 2 3 4]]
y = [[9]
[5]]
x = [[4 5 6 7]
[2 3 4 5]]
y = [[8]
[6]]
x = [[3 4 5 6]
[0 1 2 3]]
y = [[7]
[4]]
RNN预测时间序列
代码:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
1.时间序列的生成
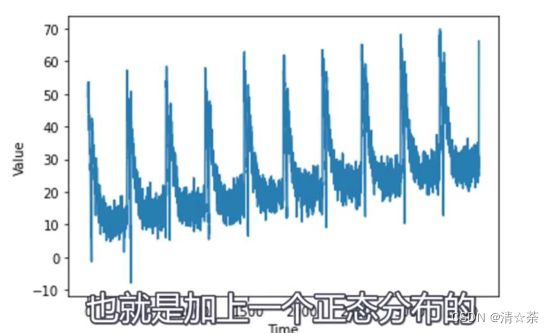
首先,我们需要生成一个时间序列。通过前面介绍的时间序列生成方法生成时间序列,本案例中的时间序列由四部分组成: 基线序列、直线趋势序列、周期性趋势序列和一个呈正态分布的误差,大致如图。
# 1. 模拟生成时间序列
def plot_series(time, series, format="-", start=0, end=None):
plt.plot(time[start:end], series[start:end], format)
plt.xlabel("Time")
plt.ylabel("Value")
plt.grid(True)
def trend(time, slope=0):
return slope * time
def seasonal_pattern(season_time):
"""Just an arbitrary pattern, you can change it if you wish"""
return np.where(season_time < 0.4,
np.cos(season_time * 2 * np.pi),
1 / np.exp(3 * season_time))
def seasonality(time, period, amplitude=1, phase=0):
"""Repeats the same pattern at each period"""
season_time = ((time + phase) % period) / period
return amplitude * seasonal_pattern(season_time)
def noise(time, noise_level=1, seed=None):
rnd = np.random.RandomState(seed)
return rnd.randn(len(time)) * noise_level
time = np.arange(4 * 365 + 1, dtype="float32")
baseline = 10
series = trend(time, 0.1)
baseline = 10
amplitude = 40
slope = 0.05
noise_level = 5
# Create the series
series = baseline + trend(time, slope) + seasonality(time, period=365, amplitude=amplitude)
# Update with noise
series += noise(time, noise_level, seed=42)
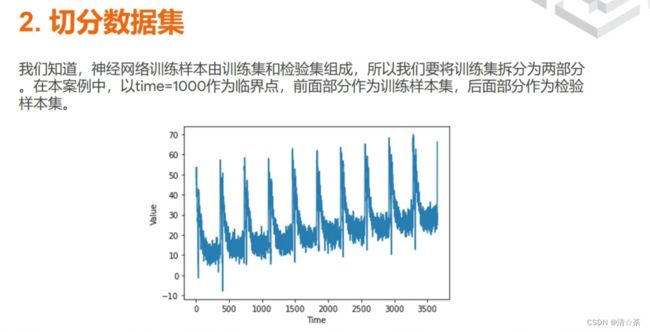
## 2.切分数据集
#我们知道,神经网络训练样本由训练集和检验集组成,所以我们要将训练集拆分为两部分在本案例中,以time=1000作为临界点,前面部分作为训练样本集,后面部分作为检验样本集。
split_time = 1000
time_train = time[:split_time]
x_train = series[:split_time]
time_valid = time[split_time:]
x_valid = series[split_time:]
window_size = 20
batch_size = 32
shuffle_buffer_size = 1000
# 模拟生成数据集
#参数说明:序列数据,窗口大小,批次大小,随机缓存大小
#输出:(特征,标签)
def windowed_dataset(series, window_size, batch_size, shuffle_buffer):
dataset = tf.data.Dataset.from_tensor_slices(series)
dataset = dataset.window(window_size + 1, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_size + 1))
dataset = dataset.shuffle(shuffle_buffer).map(lambda window: (window[:-1], window[-1]))#窗口数据作为RNN数据集,shuffle数据顺序打乱。
dataset = dataset.batch(batch_size).prefetch(1)
return dataset
# 使用单层神经网络预测时间序列
dataset = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)
print(dataset)
l0 = tf.keras.layers.Dense(1, input_shape=[window_size])
model = tf.keras.models.Sequential([l0])
model.compile(loss="mse", optimizer=tf.keras.optimizers.SGD(lr=1e-6, momentum=0.9))
model.fit(dataset,epochs=100,verbose=0)
print("Layer weights {}".format(l0.get_weights()))

forecast = []
for time in range(len(series) - window_size):
forecast.append(model.predict(series[time:time + window_size][np.newaxis]))
forecast = forecast[split_time-window_size:]
results = np.array(forecast)[:, 0, 0]
plt.figure(figsize=(10, 6))
plot_series(time_valid, x_valid)
plot_series(time_valid, results)

# 计算绝对误差
tf.keras.metrics.mean_absolute_error(x_valid, results).numpy()
5.0009346