迁移混合模型-基于新数据的迁移学习预测-寻找普通苹果与其他苹果
以已经训练好的模型A为起点,在新场景中,根据新数据建立模型B。
目的:将某个领域或任务上学习到的知识或模式,应用到不同但相关的领域或问题中。
英文:transfer learning


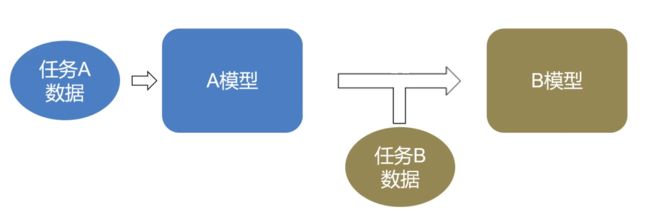
模型A存储了模型结构、权重系数(weights)
模型B基于新数据,实现了对模型A的部分结构或权重系数的更新
- 特征提取
使用模型A,移除输出层,提取目标特征信息
- 结构引用
使用模型A的结构,重新/二次训练权重系数参数
- 部分训练
使用模型A的结构,重新训练部分层的权重系数参数
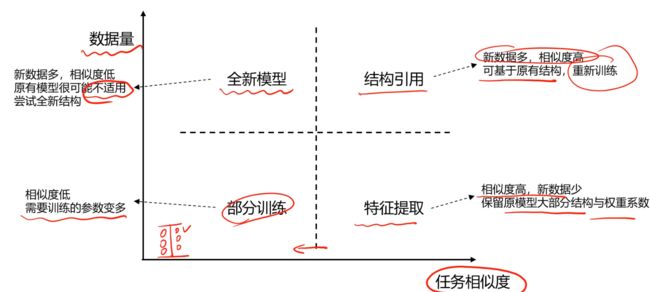
不用局限于某种方式,根据情况灵活运用

在线学习
给已经训练好的模型输入新的数据,模型将进行更新,适应新数据的趋势。
目的:针对新数据,在不需要对全数据集进行再次训练的基础上,实现模型更新
英文:online learning
适合场景:场景中有连续的数据流
特点:不改变模型结构,根据新数据更新权重系数

任务:针对航空公司机票价格,在不同时期,如何确定不同的价格
方式一:考虑天气、假期、旅行人数、同时期其他公司航班数、历史参考价格等等,建立一个专家模型
方式二:根据客户的实时购票情况,预测客户对不同价格的购买意愿,根据意愿度调整价格
输入数据:起点/终点信息、对应价格
输出结果:客户是否票
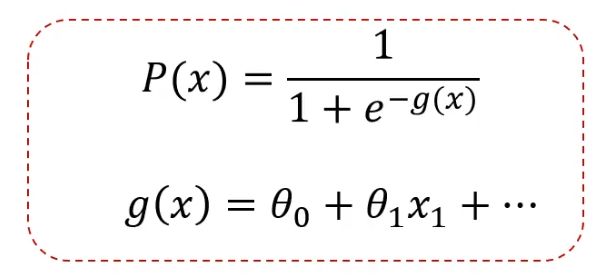
混合模型
数据决定模型表现上限
期望:更多的高质量数据
- 正常数据
- 穷尽类别
- 标注正确
现实:大部分为普通数据
- 交杂异常数据
- 包含部分类别
- 标注标准不一致
工业检测案例

无法穷尽电池所有瑕疵
苹果检测

样本总数30个,普通苹果和其他苹果各占约一半,其中有10个普通苹果已经标注,其他样本均无标签,建立模型区别普通/其他苹果
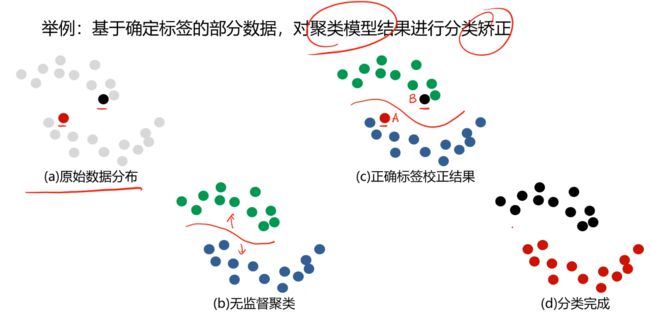
半监督学习
监督学习与无监督学习相结合的一种学习方法,它同时利用有标记样本与无标记样本进行学习
目的:在标记样本有限的情况下,尽可能识别出总样本的共同特性
英文:Semi-Supervised Learning

伪标签学习:用有标签数据训练一个分类器,然后用这个分类器对无标签数据进行分类,产生伪标签(pseudo label),按一定规则挑选出认为分类正确的无标签样本,将其与有标签样本作为数据对分类器进行训练。
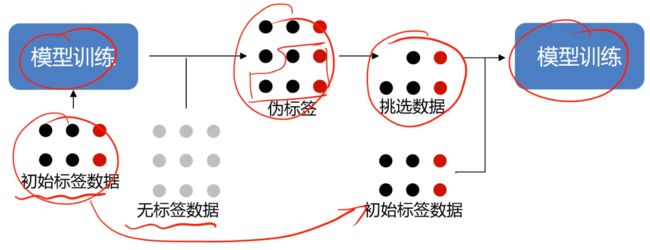
思考:如果规则不好确认怎么办?比如,数据维度太高,很难找到一个合适的规则!
核心:想办法利用标签数据提供的正确信息,灵活运用于模型中。
不局限于某种特定的方式 实现监督+无监督的灵活运用!
有标签数据提取特征的半监督学习
- 用有标签数据训练网络
- 通过隐藏层提取特征,基于特征数据对无标签数据进行建模预测
机器学习+深度学习
实战准备
实战一:基于新数据的迁移学习预测
建立MLP模型
from keras.models import Sequential
from keras.layers import Dense
model1 = Sequential()
model1.add(Dense(units=50, input_dim = 1, activation='relu'))
model1.add(Dense(units=50,activation='relu'))
model1.add(Dense(units=1, activation = 'linear'))
model1.compile(optimizer='adam',loss='mean_squared_error')
model1.summary()
模型训练与二次训练
model.fit(x,y)
model.fit(x2,y2)
模型保存到本地
from sklearn.externals import joblib
joblib.dump(model1,'model1.m')
加载本地模型
model2 = joblib.load('model1.m')
实战二:寻找普通苹果与其他苹果
数据增强,扩充确认为普通苹果的样本数量:
from keras.preprocessing.image import ImageDataGenerator
path = 'original_data'#图片加强的文件路径
dst_path = 'gen_data'
datagen = ImageDataGenerator(rotation_range=10,width_shift_range=0.1,height_shift_range=0.02,horizontal_flip=True,
vertical_flip=True)
gen = datagen.flow_from_directory(path,target_size=(224,224),
batch_size=2, save_to_dir=dst_path,
save_prefix='gen',save_format='jpg')
for i in range(100):
gen.next()
单张图片载入:
from keras.preprocessing.image import load_img, img_to_array
img_path = '1.jpg'
img = load_img(img_path,target_size=(224,224))
img = img_to_array(img)
可视化
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize=(5,5))
plt.imshow(img)
模型加载
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
import numpy as np
model_vgg = VGG16(weights='imagenet',include_top=False)
X = np.expand_dims(img,axis=0)
X = preprocess_input(X)
特征提取
features = model_vgg.predict(X)
特征数据格式预处理
features = features.reshape(1,7*7*512)
批量数据加载
import os
folder = 'train_data'
dirs = os.listdir(folder)
#print(dirs)
#名称合并
img_path = []
for i in dirs:
if os.path.splitext(i)[1] == '.jpg':
img_path.append(i)
img_path = [folder + "//" + i for i in img_path]
定义一个提取图片特征的方法:
def modelProcess(img_path,model):
img = load_img(img_path,target_size = (224,224))
img = img_to_array(img)
X = np.expand_dims(img,axis=0)
X = preprocess_input(X)
X_VGG = model.predict(X)
X_VGG = X_VGG.reshape(1,7*7*512)
return X_VGG
批量提取图片特征
features_train = np.zeros([len(img_path),7*7*512])
for i in range(len(img_path)):
feature_i