可碧教你C++——哈希

在文章的开始,先祝大家牢大年快乐

哈希的简介
unordered系列
在C++11里,加入了两个新的container——unordered_set和unordered_map。
 其使用方式与map和set类似,但是其底层实现则与其完全不同。set和map的底层数据结构为红黑树,而unordered系列的底层数据结构则为哈希表。哈希表的特点是无法按照数据大小进行排列,但是相应的其效率比红黑树稍微高一些。
其使用方式与map和set类似,但是其底层实现则与其完全不同。set和map的底层数据结构为红黑树,而unordered系列的底层数据结构则为哈希表。哈希表的特点是无法按照数据大小进行排列,但是相应的其效率比红黑树稍微高一些。
但是,哈希并非是狭义的一种数据结构。哈希是一种思想,在接触哈希表之前,其实我们就已经接触到了很多哈希的知识。比如统计字符串中各个字符出现的次数,我们可以先开辟一个26个空间的数组,然后根据字符c-'a'来直接对应位置,这便是哈希。
哈希的例题
217. 存在重复元素 - 力扣(LeetCode) https://leetcode.cn/problems/contains-duplicate/description/
https://leetcode.cn/problems/contains-duplicate/description/
何为哈希?
就像我们看到鸡就会想到鸽鸽,看到雪豹就会想到芝士


如我们将字符映射到数组中的具体位置一样,哈希代表的是一层或多层映射关系。哈希通过某种算法将一个值映射为另一个易于保存或者易于查找的值,当我们保存一个值时便通过这某一算法将数据转化为另一数据进行保存,而查找时也通过查找转化后的数据间接进行查找,最终这一算法和容器的实现便被称作为——哈希表

哈希表
哈希表是一个数组。但是其插入元素并非线性插入,而是根据某种映射关系,将元素插入到相应映射的位置,从而方便查找。也就是说,哈希表的插入和查找都是跳跃式的直接访问,通过这种跳跃将线性的查找复杂度急剧下降。
哈希有种种映射,但是哈希表只有一种。所以,哈希表在实现的时候,只采用了一种很常用的映射关系——除余映射。也就是把每一个进入哈希表的数除余一个数,得到的结果为哈希表对应的结果。
打个比方,一个哈希表有10个空间,于是便可以将插入哈希表的所有数除余10,31就对应空间1,52就对应空间2,以此类推。但是,我们又不可避免会面临另一个问题:31和61除余10都等于1,但是空间1只有一个,应该怎么办?这类问题我们统称为——哈希冲突。
哈希冲突
两个不同的值通过某个哈希函数映射到了同一个位置,便被称为哈希冲突。
哈希冲突是不可避免的。因为数据是无限的,而空间是有限的,无论空间开辟多大,最终都会有两种相同的哈希映射值出现。但是,我们可以采取多种方法去避免哈希冲突,一共可以分为三类——多重哈希,闭散列和开散列。
多重哈希
虽然我们采用了除余的哈希映射方式,但是这并不代表我们只能使用这一个哈希映射。我们可以先通过多几层的哈希映射,让这些数据的关联性尽可能降低,最后再用除余映射定位,避免哈希冲突的出现。
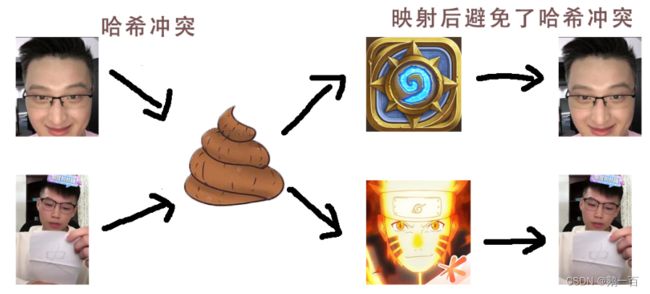
同样,当我们将字符串存储入哈希表的时候,其实就已经进行了一次映射。字符串是没有办法除余一个整数的,我们先通过映射将字符串变为一个整数,然后再用映射后的整数来进行除余操作。
但是,如果我们使用传统的ASCII码值对应,问题就大了:

kobe和kboe的ASCII码值和相同,但是其哈希冲突了。
对于这个问题,其实一直都没有一个很好的解决方案。各大数学家在这类问题上进行了很多研究,也提出了很多解决方案,但是各有利弊,其中综合下来还是有着一个最好的算法来避免字符串的哈希冲突:
字符串的哈希算法https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html
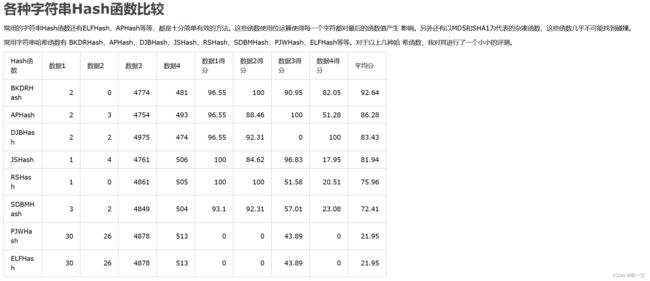
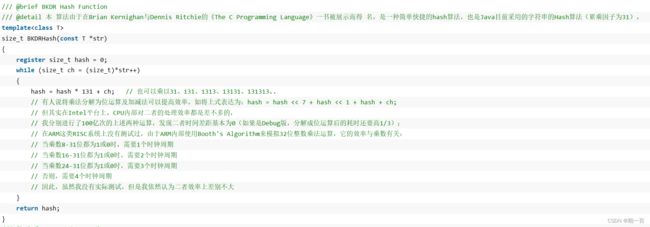
当然,具体原因我们便不多做深究了,以上内容的高深算法也只是了解,只需要记住科学家们交给我们的结论就可以了。
闭散列
闭散列是解决哈希冲突一个很简单粗暴的方法,相应带来的后果便是不怎么常用。哈希冲突了,那就把冲突的元素肘开,一直肘到没有冲突的地方为止。

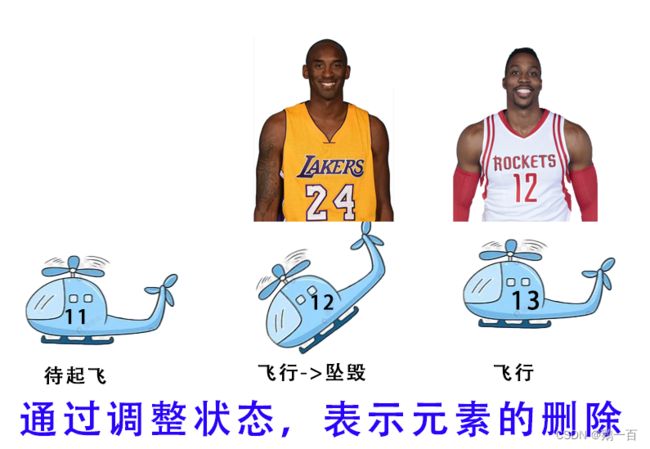
但是这种方法会存在一个问题:假如我们把哈希表的所有元素都初始置为0,但是如果我们真的要插入0,那我们咋知道这个0是原本初始化的还是被插入的?
其中一个很简单的解决方法,我们将数组的每一个空间都保存一个状态,通过该状态来判断这个空间存储的元素是否有效

//状态
enum state
{
EMPTY,
EXIST,
DELETE
};
//数组每一个空间存储的元素
template
struct elem
{
K _key;
V _val;
state _st;//存储一个状态
}; 同时,有这个状态的存储,我们就无需再在哈希表的删除上多下功夫。我们只需要把这个元素的状态由EXIST变为DELETE,就表示这块空间的元素已经被删除了。
负载因子
我们在制作这个哈希表的时候,很容易会发现几个问题:
- 哈希表的空间是有限的,但是插入的元素是无限的,哈希表总有扩容的时候
- 如果哈希表濒临满表,那会不断产生哈希冲突,最终就变成了一个不具有映射特征的数组
- 当哈希表扩容之后,原本数组的大小发生了变化,哈希映射也发生了变化
而解决这几个问题,也便引入了一个新的概念——负载因子。
负载因子代表数组所承受的元素的比例,比如一个数组容量是100,存储了40个元素,那负载因子便为0.4;对于闭散列,负载因子最大的时候自然是数组存满的时候为1.
负载因子有什么用?其作用便是解决第二个问题。负载因子越大,数组越满,哈希冲突便越多,而为了不过多去破化哈希映射的关系,当负载因子超过一定大小时,数组便需要进行扩容,并非只有数组满了才进行扩容
而哈希表的扩容,因为哈希映射关系是对容量的除余,容量发生了变化,哈希映射也发生了变化。所以, 哈希表的扩容不单单是copy整个数组,哈希表的扩容需要将原表的每个元素都重新计算哈希映射关系,然后插入到新表里。
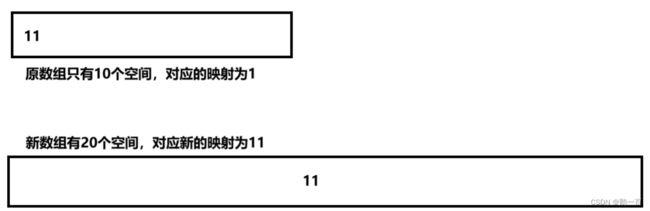
闭散列哈希表的实现
一般的,我们将最大负载因子设为0.75,将哈希表初容量设为10
每次插入新元素的时候,我们要先检查负载因子是否超过最大值,如果超过了则需要扩容。
//线性探测哈希闭散列
template//key-val键对模型
class HashTable
{
enum state//状态
{
EMPTY,
EXIST,
DELETE
};
struct elem//数组的每一个元素
{
K _key;
V _val;
state _st;
};
public:
HashTable(size_t capacity=10)
:_size(0)
{
_table.resize(capacity);
}
bool insert(const K& key, const V& val)
{
CheckFactor();//检查是否超过最大负载因子
size_t HashAddress = key % _table.capacity();//哈希映射
while (_table[HashAddress]._st == EXIST)//如果哈希冲突,则继续向后找空余位置
{
if (_table[HashAddress]._key == key)//如果哈希表中已有该元素,则插入失败
return false;
HashAddress++;
if (HashAddress == _table.capacity())//到哈希表末尾时,返回从头开始查找
HashAddress = 0;
}
//当状态是EMPTY或者DELETE时,才可以插入
_table[HashAddress]._key = key;
_table[HashAddress]._val = val;
_table[HashAddress]._st = EXIST;
_size++;
return true;
}
int find(const K& key)
{
size_t HashAddress = key % _table.capacity();//哈希映射
while (!(_table[HashAddress]._st == EMPTY))//因为负载因子小于1,所以一定有空余空间
{
if (_table[HashAddress]._st == EXIST && _table[HashAddress]._key == key)
return HashAddress;
HashAddress++;
if (HashAddress == _table.capacity())
HashAddress = 0;
}
return -1;//如果没有找到,则返回-1
}
bool erase(const K& key)
{
int HashAddress = find(key);
if (key == -1)
return false;
_table[HashAddress]._st = DELETE;
_size--;
return true;
}
size_t size() const
{
return _size;
}
bool empty() const
{
return _size == 0;
}
private:
vector _table;
size_t _size;
float MaxLoadFactor = 0.75;//负载因子
bool CheckFactor()
{
if ((float)_size / _table.capacity() >= MaxLoadFactor)//检查负载因子是否大于0.75
{
HashTable newtable(_table.capacity() * 2);
for (auto e : _table)//将每一个元素放入新表
{
if (e._st == EXIST)
{
newtable.insert(e._key,e._val);
}
}
swap(_table, newtable._table);//交换旧表和新表,旧表会自动释放
}
return true;
}
}; 开散列
和闭散列类似,用一张图便可以概括开散列
 所以,开散列又叫为哈希桶,数组中每一块空间所存的不再是单个元素,而是一个单链表,如果产生了哈希冲突,便将单链表中向下插入新元素,而非通过移位来避免哈希冲突。
所以,开散列又叫为哈希桶,数组中每一块空间所存的不再是单个元素,而是一个单链表,如果产生了哈希冲突,便将单链表中向下插入新元素,而非通过移位来避免哈希冲突。
而如果某个单链表的数据量过大, 还可以将单链表转换为红黑树,来提高查找效率。
那哈希桶需不需要负载因子呢?当然。 如果数据量过多,每个单链表的长度变大,那么最终哈希表的查找消耗就变成了单链表的查找消耗,为线性消耗,得不偿失。同时因此,就算哈希冲突可以解决,我们也要尽量避免哈希冲突来减少查找的消耗。
开散列哈希桶的实现
因为哈希桶每一个空间可以存储多个数据,所以我们负载因子可以放大为1。
而扩容的时候,我们一样需要重新寻找映射,然后在新表中插入。
//哈希桶开散列
template
class HashBucket
{
struct ListNode
{
K _key;
V _val;
ListNode* next=nullptr;
};
public:
HashBucket(size_t capacity = 10)
:_size(0)
{
_bucket.resize(capacity);
}
~HashBucket()
{
for (auto e : _bucket)
{
ListNode* cur = e;
while (cur)
{
ListNode* next = cur->next;
delete cur;
cur = next;
}
}
}
bool insert(const K& key, const V& val)
{
if (find(key))
return false;
CheckFactor();
//插入:单链表的头插
size_t HashAddress = key % _bucket.capacity();
ListNode* NewNode = new ListNode;
NewNode->_key = key;
NewNode->_val = val;
NewNode->next = _bucket[HashAddress];
_bucket[HashAddress] = NewNode;
_size++;
return true;
}
ListNode* find(const K& key)
{
size_t HashAddress = key % _bucket.capacity();
ListNode* cur = _bucket[HashAddress];
while (cur)
{
ListNode* next = cur->next;
if (cur->_key == key)
return cur;
cur = next;
}
return nullptr;
}
bool erase(const K& key)
{
size_t HashAddress = key % _bucket.capacity();
ListNode* pre = nullptr;
ListNode* cur = _bucket[HashAddress];
while (cur)
{
if (cur->_key == key)
{
if (pre == nullptr)
{
_bucket[HashAddress] = cur->next;
}
else
{
pre->next = cur->next;
}
delete cur;
return true;
}
pre = cur;
cur = cur->next;
}
return false;
}
private:
vector _bucket;
size_t _size;
float MaxLoadFactor = 1;
void CheckFactor()
{
if ((float)_size / _bucket.capacity() >= MaxLoadFactor)
{
HashBucket newbucket(_bucket.capacity() * 2);
for (auto& e : _bucket)
{
ListNode* cur = e;
while (cur)
{
ListNode* next = cur->next;
size_t HashAddress = cur->_key % newbucket._bucket.capacity();
//把每一个元素头插到新表的对应位置
cur->next = newbucket._bucket[HashAddress];
newbucket._bucket[HashAddress] = cur;
cur = next;
}
e = nullptr;
}
_bucket.swap(newbucket._bucket);
}
}
}; 有人可能要问,单链表的插入和删除这么麻烦,那为什么不用双链表来实现?
别问,库里就是用的单链表

哈希的应用
篇幅所限,哈希的应用放在了另一篇文章,具体的应用有位图,布隆过滤器,哈希切割
哈希的应用http://t.csdnimg.cn/xepez
