【大模型实践】使用 Langchain-Chatchat 进行本地部署
如果你是NLP领域初学者,欢迎关注我的博客,我不仅会分享理论知识,更会通过实例和实用技巧帮助你迅速入门。我的目标是让每个初学者都能轻松理解复杂的NLP概念,并在实践中掌握这一领域的核心技能。
通过我的博客,你将了解到:
- NLP的基础概念,为你打下坚实的学科基础。
- 实际项目中的应用案例,让你更好地理解NLP技术在现实生活中的应用。
- 学习和成长的资源,助你在NLP领域迅速提升自己。
不论你是刚刚踏入NLP的大门,还是这个领域的资深专家,我的博客都将为你提供有益的信息。一起探索语言的边界,迎接未知的挑战,让我们共同在NLP的海洋中畅游!期待与你一同成长,感谢你的关注和支持。欢迎任何人前来讨论问题。
一、Langchain-Chatchat
1、概述
Langchain-Chatchat 是一个基于 ChatGLM 大语言模型与 Langchain 应用框架实现,开源、可离线部署的检索增强生成 (RAG) 大模型的本地知识库问答应用项目。
GitHub:https://github.com/chatchat-space/Langchain-Chatchat
2、实现原理
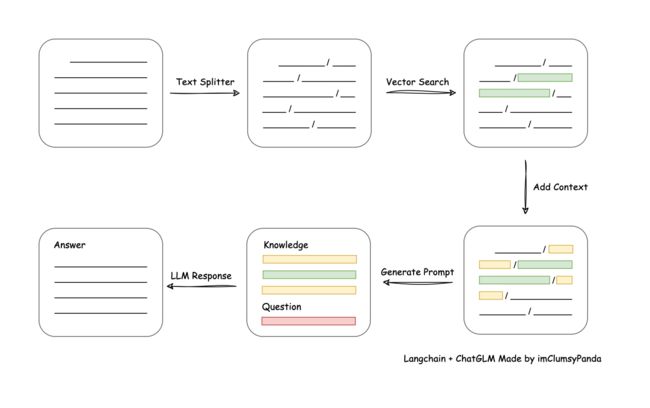
本项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k 个 -> 匹配出的文本作为上下文和问题一起添加到 prompt 中 -> 提交给 LLM 生成回答。
从文档处理角度来看,实现流程如下:
二、开发环境准备
1、软件要求
Linux Ubuntu 22.04.5 kernel version 6.7
Python 版本: >= 3.8( 很不稳定 ), < 3.11
CUDA 版本: >= 12.12、硬件要求(根据模型参数多少确定)
ChatGLM2-6B & LLaMA-7B
最低显存要求: 7GB
推荐显卡: RTX 3060, RTX 2060
LLaMA-13B
最低显存要求: 11GB
推荐显卡: RTX 2060 12GB, RTX 3060 12GB, RTX 3080, RTX A2000
Qwen-14B-Chat
最低显存要求: 13GB
推荐显卡: RTX 3090
LLaMA-30B
最低显存要求: 22GB
推荐显卡: RTX A5000, RTX 3090, RTX 4090, RTX 6000, Tesla V100, RTX Tesla P40
LLaMA-65B
最低显存要求: 40GB
推荐显卡: A100, A40, A6000
注意
若使用 int8 推理,则显存大致为 int4 推理要求的 1.5 倍
若使用 fp16 推理,则显存大致为 int4 推理要求的 2.5 倍
数据仅为估算,实际情况以 nvidia-smi 占用为准。
同时,Embedding 模型将会占用 1-2G 的显存,历史记录最多会占用数 G 显存,因此,需要多冗余一些显存。
内存最低要求: 内存要求至少应该比模型运行的显存大。
三、部署
1、拉取仓库
git clone https://github.com/chatchat-space/Langchain-Chatchat.git若网络原因无法拉取,手动下载、解压即可
2、进入目录
cd Langchain-Chatchat3、创建虚拟环境
conda create -n chatchat python=3.104、激活使用虚拟环境
conda activate chatchat5、安装全部依赖
pip install -r requirements.txt
pip install -r requirements_api.txt
pip install -r requirements_webui.txt 默认依赖包括基本运行环境(FAISS 向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
6、初始化配置文件
python copy_config_example.py脚本将会将所有 config 目录下的配置文件样例复制一份到 config 目录下,方便开发者进行配置。 接着,开发者可以根据自己的需求,对配置文件进行修改。
basic_config.py:基础配置项:配置记录日志的格式和储存路径,通常不需要修改。
kb_config.py:数据库配置:配置分词器、知识库、向量数据库等信息
model_config.py:模型配置项:包含本地 LLM 模型、本地 Embeddings 模型、在线 LLM 模型 API 的相关配置
prompt_config.py:提示词配置项:提示词配置分为三个板块,分别对应三种聊天类型:基础的对话提示词、与知识库对话的提示词、与 Agent 对话的提示词。
server_config.py:服务和端口配置项:不需要进行大量的修改,仅需确保对应的端口打开,并不互相冲突即可。server_config.py 中的配置优先于 startup.py 中的默认值,注意避免配置文件覆盖
7、模型下载
模型下载取决于自己的网络情况,这里需要提前下载 THUDM/chatglm2-6b 与 BAAI/bge-large-zh 到本地,然后在 model_config.py 中配置
1. 若网络良好 (全球畅通无阻) 则完全不需要先下载模型,在执行过程中会自动下载相关模型。
2. 如果网络存在问题,则可以事先下载好需要的模型,然后在 model_config.py 文件中配置,具体配置参考异常 3 中的处理办法
注意:
Windows 环境下,会默认自动将该模型下载到 C:\Users\Admin.cache\torch\sentence_transformers 目录下,若下载失败,参考异常 3 中的处理办法
8、初始化知识库
第一次运行本项目,知识库尚未建立,或者配置文件中的知识库类型、嵌入模型发生变化,需要以下命令初始化或重建知识库:
python init_database.py --recreate-vs如果已经有创建过知识库,可以先执行以下命令创建或更新数据库表:
python init_database.py --create-tables第一次使用时,会自动下载 BAAI/bge-large-zh 模型,用于知识库的初始化构建
(chatchat) root@master:~/Langchain-Chatchat# python init_database.py --recreate-vs
recreating all vector stores
2023-12-20 21:40:48,647 - faiss_cache.py[line:80] - INFO: loading vector store in 'samples/vector_store/bge-large-zh' from disk.
2023-12-20 21:40:48,999 - SentenceTransformer.py[line:66] - INFO: Load pretrained SentenceTransformer: /root/models/bge-large-zh
Batches: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.80it/s]
2023-12-20 21:40:51,466 - loader.py[line:54] - INFO: Loading faiss with AVX2 support.
2023-12-20 21:40:51,751 - loader.py[line:56] - INFO: Successfully loaded faiss with AVX2 support.
2023-12-20 21:40:51,761 - faiss_cache.py[line:80] - INFO: loading vector store in 'samples/vector_store/bge-large-zh' from disk.
Batches: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 72.05it/s]
2023-12-20 21:40:51,783 - utils.py[line:286] - INFO: RapidOCRLoader used for /root/onethingai-tmp/Langchain-Chatchat/knowledge_base/samples/content/llm/img/ 分布式训练技术原理-幕布图片 -124076-270516.jpg
2023-12-20 21:40:51,784 - utils.py[line:286] - INFO: RapidOCRLoader used for /root/onethingai-tmp/Langchain-Chatchat/knowledge_base/samples/content/llm/img/ 分布式训练技术原理-幕布图片 -20096-279847.jpg
2023-12-20 21:40:51,785 - utils.py[line:286] - INFO: RapidOCRLoader used for /root/onethingai-tmp/Langchain-Chatchat/knowledge_base/samples/content/llm/img/ 分布式训练技术原理-幕布图片 -220157-552735.jpg
2023-12-20 21:40:51,785 - utils.py[line:286] - INFO: RapidOCRLoader used for /root/onethingai-tmp/Langchain-Chatchat/knowledge_base/samples/content/llm/img/ 分布式训练技术原理-幕布图片 -36114-765327.jpg
2023-12-20 21:40:51,786 - utils.py[line:286] - INFO: RapidOCRLoader used
Batches: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6/6 [00:01<00:00, 3.43it/s]
正在将 samples//root/onethingai-tmp/Langchain-Chatchat/knowledge_base/samples/content/test_files/test.txt 添加到向量库,共包含 59 条文档████████████████████████████████████▋ | 5/6 [00:01<00:00, 3.05it/s]
Batches: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 2.41it/s]
正在将 samples//root/onethingai-tmp/Langchain-Chatchat/knowledge_base/samples/content/llm/img/ 大模型推理优化策略-幕布图片 -930255-616209.jpg 添加到向量库,共包含 3 条文档███████████████████████████████████| 2/2 [00:00<00:00, 2.52it/s]
Batches: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 43.48it/s]
正在将 samples//root/onethingai-tmp/Langchain-Chatchat/knowledge_base/samples/content/llm/img/ 大模型推理优化策略-幕布图片 -789705-122117.jpg 添加到向量库,共包含 1 条文档 | 0/1 [00:009、启动项目
启动项目整个过程中,坑也比较多,参考异常 2 与异常 3 中的处理办法。
一键启动脚本 startup.py, 一键启动所有 Fastchat 服务、API 服务、WebUI 服务
python startup.py -a 启动时,如果没用在 model_config.py 中配置配置模型信息,则会自动模型下载 THUDM/chatglm3-6b 到本地使用
==============================Langchain-Chatchat Configuration==============================
操作系统:Linux-6.1.56-1.2.3-x86_64-with-glibc2.35.
python 版本:3.10.13 | packaged by conda-forge | (main, Oct 26 2023, 18:07:37) [GCC 12.3.0]
项目版本:v0.2.8
langchain 版本:0.0.344. fastchat 版本:0.2.34
当前使用的分词器:ChineseRecursiveTextSplitter
当前启动的 LLM 模型:['chatglm3-6b', 'zhipu-api', 'openai-api'] @ cuda
{'device': 'cuda',
'host': '0.0.0.0',
'infer_turbo': False,
'model_path': '/root/models/chatglm3-6b',
'model_path_exists': True,
'port': 20002}
{'api_key': '',
'device': 'auto',
'host': '0.0.0.0',
'infer_turbo': False,
'online_api': True,
'port': 21001,
'provider': 'ChatGLMWorker',
'version': 'chatglm_turbo',
'worker_class': }
{'api_base_url': 'https://api.openai.com/v1',
'api_key': '',
'device': 'auto',
'host': '0.0.0.0',
'infer_turbo': False,
'model_name': 'gpt-3.5-turbo',
'online_api': True,
'openai_proxy': '',
'port': 20002}
当前 Embbedings 模型: bge-large-zh @ cuda
==============================Langchain-Chatchat Configuration==============================
2023-12-20 21:44:16,058 - startup.py[line:650] - INFO: 正在启动服务:
2023-12-20 21:44:16,058 - startup.py[line:651] - INFO: 如需查看 llm_api 日志,请前往 /root/Langchain-Chatchat/logs
2023-12-20 21:44:20 | INFO | model_worker | Register to controller
2023-12-20 21:44:20 | ERROR | stderr | INFO: Started server process [8455]
2023-12-20 21:44:20 | ERROR | stderr | INFO: Waiting for application startup.
2023-12-20 21:44:20 | ERROR | stderr | INFO: Application startup complete.
2023-12-20 21:44:20 | ERROR | stderr | INFO: Uvicorn running on http://0.0.0.0:20000 (Press CTRL+C to quit)
2023-12-20 21:44:21 | INFO | model_worker | Loading the model ['chatglm3-6b'] on worker 6c239f49 ...
Loading checkpoint shards: 0%| | 0/7 [00:00}
{'api_base_url': 'https://api.openai.com/v1',
'api_key': '',
'device': 'auto',
'host': '0.0.0.0',
'infer_turbo': False,
'model_name': 'gpt-3.5-turbo',
'online_api': True,
'openai_proxy': '',
'port': 20002}
当前 Embbedings 模型: bge-large-zh @ cuda
服务端运行信息:
OpenAI API Server: http://127.0.0.1:20000/v1
Chatchat API Server: http://127.0.0.1:7861
Chatchat WEBUI Server: http://0.0.0.0:8501
==============================Langchain-Chatchat Configuration==============================
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to False.
You can now view your Streamlit app in your browser.
URL: http://0.0.0.0:8501 10、访问 Web UI
Web UI 地址:http://127.0.0.1:8501
11、API 服务
不是一键启动,则可以单独启动 API 服务:
python server/api.py访问:http://0.0.0.0:7861/docs
12、Web UI 服务
不是一键启动,则可以单独启动 Web UI 服务:
streamlit run webui.py访问:http://localhost:8501/
四、异常集合
1、异常 1
场景:
初始化配置文件
python init_database.py --recreate-vs问题:
cannot import name 'Doc' from 'typing_extensions'解决:
因为安装的 typing_extensions 版本不正确,需要重新安装
pip install typing_extensions==4.8.02、异常 2
场景:
启动项目
python startup.py -a问题:
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a singl
e OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE t
o allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.解决 1:
这里使用 Anaconda 创建虚拟环境,其中有 ibiomp5md.dll 文件,重命名以备份该文件,如:libiomp5md.dll.back
解决 2:
在 startup.py 文件上方设置环境变量,保证前后顺序
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'3、异常 3
场景:
启动项目过程中
python startup.py -a问题:
| OSError: We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached files and it looks like THUDM/chatglm3-6b is not the path to a directory containing
a file named config.json.解决:
默认使用的 LLM 模型 THUDM/ChatGLM3-6B 与 Embedding 模型 BAAI/bge-large-zh,会远程连接模型网站。这里使用魔法也不得行,不知为啥,具体模型网站能访问的。
下载 LLM 模型 THUDM/ChatGLM3-6B 与 Embedding 模型 BAAI/bge-large-zh
1. 访问 https://huggingface.co/BAAI/bge-large-zh 下载
2. 访问 https://huggingface.co/THUDM/chatglm3-6b 下载
然后修改 configs/model_config.py 文件,指定模型存放位置与使用模型名称,需保证存放模型目录下的模型文件名与 model_config.py 文件使用的名称一致。
# 统一存放模型位置
MODEL_ROOT_PATH = "../../../models"
# 选用的 Embedding 名称
EMBEDDING_MODEL = "bge-large-zh"
# 要运行的 LLM 名称,可以包括本地模型和在线模型
LLM_MODELS = ["chatglm3-6b", "zhipu-api", "openai-api"]
MODEL_PATH = {
"embed_model": {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec-base": "shibing624/text2vec-base-chinese",
"text2vec": "GanymedeNil/text2vec-large-chinese",
"text2vec-paraphrase": "shibing624/text2vec-base-chinese-paraphrase",
"text2vec-sentence": "shibing624/text2vec-base-chinese-sentence",在这个充满科技魔力的时代,自然语言处理(NLP)正如一颗璀璨的明星般照亮我们的数字世界。当我们涉足NLP的浩瀚宇宙,仿佛开启了一场语言的奇幻冒险。正如亚历克斯·康普顿所言:“语言是我们思想的工具,而NLP则是赋予语言新生命的魔法。”这篇博客将引领你走进NLP前沿,发现语言与技术的交汇点,探寻其中的无尽可能。不论你是刚刚踏入NLP的大门,还是这个领域的资深专家,我的博客都将为你提供有益的信息。一起探索语言的边界,迎接未知的挑战,让我们共同在NLP的海洋中畅游!期待与你一同成长,感谢你的关注和支持。欢迎任何人前来讨论问题。