C语言学习笔记---指针(6)
目录
先复习一下上节课的部分重点
设计和实现bubble_sort2()
接下来强化一下sizeof和strlen的对比
关于sizeof
关于strlen
数组和指针笔试题的解析
一维数组
字符数组
先复习一下上节课的部分重点
回调函数是什么?回调函数就是一个通过函数指针调用的函数
qsort的使用就是一个典型的使用回调函数的案例
由于本节还是和排序有关,需再复习一下冒泡排序和qsort()函数
学知识就是要不厌其烦地回顾 lol
void Bubble_arr(int arr[], int sz)
{
int i = 0;//趟数
for (i = 0; i < sz - 1; i++)
{
//一趟冒泡排序的过程
int j = 0;//下标
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = 0;//临时变量
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
void print_arr(int arr[], int sz)
{
int i = 0;//下标
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
//想实现升序排序
int arr[10] = { 0,1,4,7,8,5,2,3,6,9 };
int sz = sizeof(arr) / sizeof(int);
Bubble_arr(arr, sz);
print_arr(arr, sz);
return 0;
}上一节我们讲过冒泡排序的缺点就是把函数参数的类型限制死了,只能打印整型数组
那我们要打印浮点型数组或者其他类型的数组怎么办?
上一节我们介绍了qsort函数来打印任意类型的数组
qsort是一个库函数,可以直接使用,它的实现是使用快速排序算法来排序的
注意:qsort是库函数,使用时必须包含头文件#include
qsort函数一共有四个参数
qsort(void*base,//待排序的数组的起始位置(数组名存放的就是数组的起始位置)
size_t num,//待排序的数组的元素个数
size_t size,//待排序的数组的元素大小
int(*compar)(const void*p1,const void*p2));
第四个参数是个函数指针,指向一个函数,被指向的函数是用来比较待排序数组中的两个元素的,
比如p1指向一个元素,p2指向一个元素,被指向的函数就是用来比较p1和p2的
被指向的函数的参数和返回值类型必须和int(*compar)(const void*p1,const void*p2))保持一致,参数类型可以在函数体内将void*强制性转换后再比较大小
补充一下:qsort的参数之所以设计成void*类型的指针,是因为qsort可能排序任意类型的数据
为了能够接受任意可能得指针类型,设计成void*(这种类型就算个垃圾桶一样,谁的地址都可以给它传)
以上代码可以用qsort优化一下:
#include//qsort库函数头文件
int cmp_int(const void* p1, const void* p2)
{
return *(int*)p1 - *(int*)p2;
}
void print_arr(int arr[], int sz)
{
int i = 0;//下标
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
int arr[10] = { 0,1,4,7,8,5,2,3,6,9 };
int sz = sizeof(arr) / sizeof(int);
qsort(arr, sz, sizeof(arr[0]), cmp_int);//将这四个参数传给C语言封装好的qsort库函数进行处理
print_arr(arr, sz);//打印qsort库函数执行完后的结果
return 0;
} 看到这,是不是对qsort的认识又进了一步呢?
qsort也可以排列结构体等类型的数据
接下来学习新知识:
设计和实现bubble_sort2()
这个函数能够排序任意类型的数据
(相当于自己写一个类似于 C语言封装好的qsort库函数 的函数)
怎么做呢?我们可以在冒泡排序的基础上改造一下;
改造的前提,还是使用冒泡排序
怎么改造呢?有三个地方要改造:
void Bubble_arr(int arr[], int sz)//1.参数要改造
{
int i = 0;//趟数---这里不需要改造
for (i = 0; i < sz - 1; i++)
{
//一趟冒泡排序的过程
int j = 0;//下标
for (j = 0; j < sz - 1 - i; j++)//---这里不需要改造
{
if (arr[j] > arr[j + 1])//---2.比较的地方要改造,使用回调函数改造
{
int tmp = 0;//临时变量
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
//3.交换的地方也需要改造
}
}
}
}改造后的代码:
//封装一个用来交换的函数
void swap(char*buf1, char*buf2,size_t width)
//两个实参(char*)base + j * width 和 (char*)base + (j + 1)width已经被前置类型转换成char*指针,
//也就是存放了char型元素的地址的指针,所以用char*指针来接收
{
//遍历元素中的每一个字节,对应交换
int i = 0;//交换的次数,也可以理解每一个元素所占字节的下标
for (i = 0; i < width; i++)//数据类型占多少宽度(字节),就交换多少对字节,交换的对数也就是交换的次数
{
//交换buf1和buf2对应的一个字节
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;//地址+1
buf2++;//地址+1
}
}
void Bubble_sort(void*base, size_t sz, size_t width,int(*cmp)(const void*p1,const void*p2))//改造
//相当于自己写一个类似于 C语言封装好的qsort库函数 的函数,所以要传这四个参数过来
//int sz也可以,cmp函数必须得给主函数返回一个值(<0 / >0 / ==0),才能执行交换,
//因为我们只是想比较p1和p2的值,不希望p1和p2的值被修改,所以要加上const修饰
{
int i = 0;//趟数
for (i = 0; i < sz-1; i++)
{
//一趟冒泡排序的过程
int j = 0;//下标
for (j = 0; j < sz - 1 - i; j++)
{
//if (arr[j] > arr[j + 1])//改造前
//因为我们还不知道传过来的数组中的元素是什么类型的,我们只知道数组的起始位置,多少个元素和每个元素占字节的大小(宽度)
//有什么办法拿到下标为j和j+1的元素的地址拿到,并传给cmp()函数呢?
//请看:
//我们将void*base强制类型转换成(char*),每个char占一个字节
//然后加下标j*元素的宽度,就得到了下标为j的元素的地址
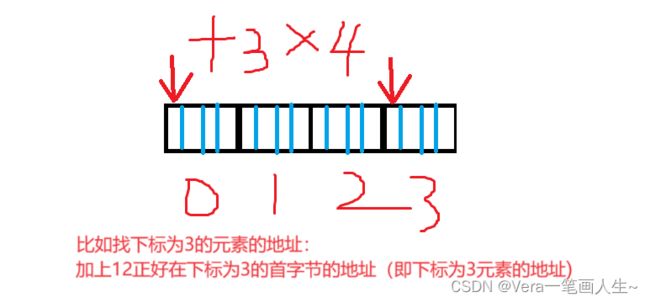
//比如元素是int类型,宽度是4的字节,那下标为3的元素就是:起始位置+3*4=12个字节,这时正好指向下标为3的元素的首字节的地址(即元素的地址)
//如果看不懂请看下图1
if (cmp( (char*)base+j*width, (char*)base+(j+1)*width )>0)//改造
//(char*)base + j * width----对应arr[j]
//(char*)base+(j+1)width----对应arr[j + 1]
//将(char*)base+j*width,(char*)base+(j+1)width这两个参数传给cmp()函数进行比较
//如果cmp()函数返回的值是>0的,说明(char*)base + j * width>(char*)base+(j+1)width,为了实现升序排序,要执行交换
//怎么交换?可以封装一个交换的函数
{
swap((char*)base + j * width, (char*)base + (j + 1)*width,width);
//由于数据类型未知,所以要把width也要传过去给交换函数知道
//改造
}
}
}
}【图一】
到这里,一个类似于 C语言封装好的qsort库函数 的Bubble_arr函数就打造好了,开始使用!
//提供一个用来比较两个元素大小的函数,即int *(cmp)(const void*p1,const void*p2)
int cmp_int(const void* p1, const void* p2)
{
return *(int*)p1 - *(int*)p2;
}
//打印交换后的结果
void print_arr(int arr[], size_t sz)
{
int i = 0;//下标
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
//假设想把一个int型数组升序排列
int arr[10] = { 0,1,4,7,8,5,2,3,6,9 };
size_t sz = sizeof(arr) / sizeof(int);//计算数组的元素的个数
size_t width = sizeof(arr[0]);//计算每个元素的宽度,即每个元素的所占字节数
Bubble_sort(arr, sz, width, cmp_int);//将这四个参数传给
print_arr(arr, sz);//打印qsort库函数执行完后的结果
return 0;
}排序整型数组成功!
接下来我们使用这个Bubble_sort函数来排序结构体的数据
结构体上一节已经复习过了,不再复习了,直接写
#include//strcmp函数的头文件
//定义一个结构体
struct stu
{
char name[20];//字符型数组,最多可以放19个英文字母,还有一个是\0
int age;
};
//按名字来比较
int cmp_by_name(const void* p1, const void* p2)
{
//将void*强制转换为结构体指针,结构体指针里面存放着结构体元素的地址->通过地址找到该元素
return strcmp(((struct stu*)p1)->name, ((struct stu*)p2)->name);//(p1存放了结构体成员的地址)->成员
//上一节讲过strcmp可以比较字符串的大小
}
//打印按名字排序的结果
void print_by_name(struct stu arr[], int sz)
{
int i = 0;//下标
for (i = 0; i < sz; i++)
{
printf("%s %d\n", arr[i].name, arr[i].age);//访问结构体成员信息:结构体变量名/数组名[下标].结构体成员
}
}
//按年龄来比较
int cmp_by_age(const void* p1, const void* p2)
{
return *(int*)p1- *(int*)p2;
}
//打印按年龄排序的结果
void print_by_age(struct stu arr[], int sz)
{
int i = 0;//下标
for (i = 0; i < sz; i++)
{
printf("%s %d\n", arr[i].name, arr[i].age);//访问结构体成员信息:结构体变量名/数组名[下标].结构体成员
}
}
void swap(char* buf1, char* buf2, size_t width)
{
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
void Bubble_sort(void* base, size_t sz, size_t width, int(*cmp)(const void* p1, const void* p2))//改造
{
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width) > 0)
{
swap((char*)base + j * width, (char*)base + (j + 1) * width, width);
}
}
}
}
int main()
{
struct stu arr[3] = { {"zhangsan",34},{"wangwu",12},{"lisi",42} };//struct 结构体标签名 结构体变量名/数组名[],在数组里面初始化结构体成员
int sz = sizeof(arr) / sizeof(arr[0]);
Bubble_sort(arr, sz, sizeof(arr[0]), cmp_by_name);//假设按名字来比较
print_by_name(arr, sz);
Bubble_sort(arr, sz, sizeof(arr[0]), cmp_by_age);//假设按年龄来比较
print_by_age(arr, sz);
return 0;
} 看到这,应该对于qsort底层的代码逻辑有了更清晰的认识!
接下来强化一下sizeof和strlen的对比
后续学习有大用途!所以先铺垫一下:
关于sizeof
sizeof()其实是一种操作符,不是函数!是单目操作符
sizeof 计算变量所占内存内存空间⼤⼩的,单位是字节
如果操作数是类型的话,计算的是使⽤类型创建的变量所占内存空间的⼤⼩
它只关注占⽤内存空间的⼤⼩,不在乎内存中存放什么数据
sizeof返回值打印的时候最好是用%zd,不过也可以用%d
%zd 用来格式化 ssize_t 类型(有符号整数类型)或 size_t 类型(无符号整数类型)的值
这个占位符是用于确保正确的格式化,并且可以在有符号和无符号整数之间正确切换。
当你使用 %zd 时,它可以用于 ssize_t 和 size_t 类型,因此适用于带符号和无符号整数。
int main()
{
int a = 10;
printf("%zd\n", sizeof(a));//可以理解为用int类型套出来的数据都是4个字节
printf("%zd\n", sizeof a);//也可以这样写,可以省略括号
printf("%zd\n", sizeof(int));
//printf("%zd\n", sizeof int);//但是不可以这样写
//计算数组
int arr1[4] = { 0 };
char arr2[4] = { 0 };
printf("%d\n", sizeof(arr1));//16
printf("%d\n", sizeof(arr2));//4
//int [4] //数组去掉数组名表示数组的类型
//因此也可以这样算:
printf("%d\n", sizeof(int[4]));//16
printf("%d\n", sizeof(char[4]));//4
return 0;
}关于strlen
strlen 是C语⾔库函数,功能是求字符串⻓度。
函数原型如下:size_t strlen(const char* str);//给strlen传参传的是一个地址
使用时需包含头文件#include
int main()
{
char arr[] = "abcdef";//字符数组的原型"abcdef\0"
size_t len = strlen(arr);
printf("%zd\n",len);//6,统计的是\0之前的字符个数,遇到\0才终止计算,不计入内
//和sizeof对比一下:
size_t sz=sizeof(arr);
printf("%zd\n", sz);//7,因为sizeof计算的是占用内存的大小,而'\0'也是一个字符,所以也占内存,也计入内
//把元素改成20看看效果
char arr1[20] = "abcdef";
size_t len1 = strlen(arr1);
printf("%zd\n", len1);//6,计算的还是字符个数,只关注个数
size_t sz1 = sizeof(arr1);
printf("%zd\n", sz1);//20,为arr1数组开辟了20个元素的空间,没有初始化的元素默认为0,只关注内存,不关注数组里面存的是什么数据
//再看看这个效果
char arr2[3] = { 'a','b','c' };
printf("%zd", strlen(arr2));//计算出来的是一个随机值
//因为strlen需要遇到'\0'才会终止计算,而arr2中只有三个元素[3],没有'\0',所以无法计算出准确的长度
//注意:以下是个典型的错误写法:
//char arr[6] = "abcdef";//因为这个字符串包括一个'\0',所以准确来说应该是7个字符,所以元素个数不是6,而是7
return 0;
}数组和指针笔试题的解析
一维数组
先再次强调一遍:
数组名一般表示数组首元素的地址
但是有2个例外:
1.sizeof(单独一个数组名),数组名表示整个数组,计算的是整个数组的大小,单位是字节
2.&数组名,数组名表示整个数组,取出的是数组的地址
除此之外,所有遇到的数组名都是数组首元素的地址
int main()
{
int a[] = { 1,2,3,4 };//a数组有4个元素,每个元素是int类型的数据
printf("%zd\n", sizeof(a));//16
printf("%zd\n", sizeof(a + 0));//4,因为a表示的就是数组首元素的地址,a+0等于没有+,还是首元素的地址
//那地址的大小是多少呢?地址的大小就是指针的大小,
//在64位环境下,一个指针的大小是8个字节,在32位的环境下,一个指针的大小是4个字节
printf("%zd\n", sizeof(*a));//4,因为a表示的就是数组首元素的地址,解引用之后找到首元素,首元素是int型,所以是4个字节
printf("%zd\n", sizeof(a + 1)); //4或者8,因为a表示的就是数组首元素的地址, a==&a[0],
//那a+1就相当于是一个整型的指针int* +1,就跳过一个整型,所以a+1指向下一个整型的地址,那地址的大小就是指针的大小,4或者8
printf("%zd\n", sizeof(a[1]));//4,计算的是下标位1的元素的大小,int 4个字节
printf("%zd\n", sizeof(&a));//4或者8,计算的是整个数组的地址的大小,只要是地址的大小就是指针的大小,4或者8
//int(*pa)[4]=&a;
//int(*)[4]//数组指针,这样的类型解引用后找到的是一个大小为4的整型数组,则计算出来的就是16的字节
printf("%zd\n", sizeof(*&a));//16,先取到整个数组的地址,再解引用找到整个数组,*和&抵消,其实等价于sizeof(a)
//&a的类型是数组指针,数组指针解引用访问一个数组的大小,是16个字节
printf("%zd\n", sizeof(&a + 1));//4或者8,取到整个数组的地址,+1就跳过一个数组指向外面某一块内存的地址,只要是地址,大小都是4或者8
printf("%zd\n", sizeof(&a[0]));//4或者8,取到下标为0的元素的地址,大小是4或者8
printf("%zd\n", sizeof(&a[0] + 1));//4或者8,取到首元素的地址,+1指向第二个元素的地址,大小是4或者8
return 0;
}字符数组
int main()
{
char arr[] = { 'a','b','c','d','e','f' };//arr数组中有6个元素
printf("%d\n", sizeof(arr));//6
printf("%d\n", sizeof(arr + 0));//4/8,是地址,大小就是4或者8
printf("%d\n", sizeof(*arr));//1
printf("%d\n", sizeof(arr[1]));//1
printf("%d\n", sizeof(&arr));// 4/8
printf("%d\n", sizeof(&arr + 1));// 4/8
printf("%d\n", sizeof(&arr[0] + 1));// 4/8
return 0;
}
换成strlen算算::
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(arr));//随机值,第一个元素开始向后数,没有遇到'\0'
printf("%d\n", strlen(arr + 0));//随机值,首元素的地址还是首元素的地址
//printf("%d\n", strlen(*arr));//err,因为strlen需要接收的是地址,
//而我们直接传了一个首元素‘a',而'a'的ASCII是97,strlen就把97当成了地址,strlen还要通过这个地址找它对应的字符,程序崩溃
//printf("%d\n", strlen(arr[1]));//err,'b'的ASCII码值是98,和上面一样的结果
printf("%d\n", strlen(&arr));//随机值,从第一个元素开始向后数,没有遇到'\0'
printf("%d\n", strlen(&arr + 1));//随机值,跳过一个数组,越界访问,没有遇到'\0'
printf("%d\n", strlen(&arr[0] + 1));//随机值,从第二元素开始向后数,没有遇到'\0'
return 0;
}以上结果不明白的可以留言或者私信!秒回!
预知后事如何,请听下回分解......