flink系列--flinksql cdc源码分析
前言
关于cdc(change data capture)不知道的小伙伴们可以去百度一下,简单来说就是对于数据库的变更进行一个探测,因为数据库的更改对于客户端来说是没有感知的,你需要开启线程去查询,才知道数据有没有更新,但是就算是查询,如果是直接select * from ....,这样获取的结果还要和上次获取的结果对比,才知道数据有没有发生变化,耗时大,一个简单的思路是在要查询的表中添加一个updateTimestamp字段,然后判断updateTimestamp字段是否大于上次查询时的时间,如果大于,明显在上次查询之后数据更改了,如果小于或者等于说明没有更改。这样确实可以感知数据库的数据变化。可是这样做的缺点是与业务耦合度大呀,要是你的业务表没有updateTimestamp字段,你还需要自己加上这个字段。其次定时查询数据库也会造成数据库的压力。那么另外一种牛逼的方式那就是基于日志的cdc(刚才说的那种方式是基于查询的cdc),这种方式可以完美解决上述方法的缺点,做到低延迟、高吞吐、精准度高。不知道大家知不知道mysql的binlog,这个东西不知道可以百度一下,其实就是记录数据更改的日志。你增删改一条数据,这个日志就会记录一条数据(查询自然不需要记录,因为查询不会对数据库造成更改),日志的设计是为了数据库故障恢复而设计的,其实他的另一大用处就是应用于cdc。现在客户端要感知数据库的变更,不需要去查询数据库的具体数据了,而是直接查询日志。删除(更新、增加)一条数据,日志就增加一条数据,那就直接把这个增加的数据发给客户端,客户端就知道数据发生变化了,然后对数据进行合并。我们知道日志是追加模式的,这种模式非常适合流数据。你再仔细想一想,流数据是个啥样子,不就是一条一条数据的流吗,正好日志也是一条一条数据的增加,(kafka不就是append-only模式吗,其实就是追加模式,其实kafka本质上的设计就是基于日志特点设计的)基于这一认识,那我们就可以清楚地知道,binlog本质就是把数据库这种批数据的模式,转换为流数据模式。所以想要知道数据库数据是否变更,直接查询日志就可以了,这样是不是可以达到低延迟(有变更直接发过来)、高吞吐(不管数据库发生多大的变化,日志都会记录,而且不会去查询数据库,并不会给数据库造成查询压力,所以数据量大,也可以获取数据的更新)、精确度高(从日志获取的数据更改,准确度能不高吗)。说完了前置知识,接下来就要讲讲咱们的sql-cdc。
概念
首先,咱们研究这个flinksql cdc,就要知道他是个什么东西,有啥用。概括来说就是flink在join mysql类关系型数据库的时候,不需要先把数据库的数据同步到kafka,然后再通过kafka进行join,现在不需要这个操作了,flinksql直接集成了cdc,可以直接对接关系型数据库,不需要kafka这个中间件。有的人问价格kafka有啥的吗,反正kafka还可以解耦,这样还不错啊。但是你想过没有多了一个中间件,中间会消耗多少东西(数据库进了kafka需要序列化、反序列化、磁盘落地,这些都需要消耗时间、磁盘资源)。所以flinksql直接对接cdc会省掉好多资源,而且还简化了系统。首先咱们来看看之前cdc对接kafka是咋样的。
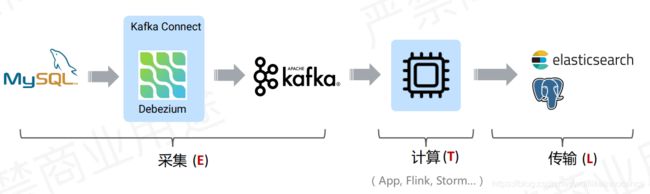
不要介意这张图的水印哈,这是网上截图过来的(哈哈),很明显数据的同步就归属到kafka的工作了,其实sql cdc就是直接去掉kafka中间层,如下图:

看到转变了吗,也就是flinksql可以直接把etl过程直接解决了,都不需要中间件作为数据采集层,看到上图和这个图的对比自然能想到flinksql能直接对接cdc,肯定集成了debezium等同步组件。
分析
说完概念咱们就可以分析sql-cdc了,其实说白了就是这个对接cdc就是要个sourcefunction可以处理cdc数据。其实看我上篇博客flink connector源码分析,就可以知道sourcefunction最重要的两个函数就是open和run这两个生命周期方法,也说了这两个生命周期方法的执行时机,在了解这个知识的前提下,那咱们就照猫画虎的分析着。
首先要分析sql cdc就需要去github额外下载源码,因为这个sql-cdc并没有合并到flink1.11的主分支去,网址:flink-cdc-connector,下载之后可以看到他的工程结构非常清晰,有支持mysql和postgres数据库的两个模块,还有与一个同步数据的debezium模块,其实用canal等同步工具也可以实现,flink1.11暂时没有实现。

看一下flink-sql-connector-mysql-cdc和flink-sql-connector-postgres-cdc模块就知道还没有任何类,不知道啥意思,主要的实现在于flink-connector-mysql-cdc和flink-connector-postgres-cdc这两个包。
拿mysql来说,其实最主要的就是用MySQLSource类build一个DebeziumSourceFunction出来,也就是MysqlSource就是一个Builder,包括table模块中的MysqlTableSource也会调用MysqlSource来build一个DebeziumSourceFunction,所以今天的主角就是DebeziumSourceFunction。因为上一篇博客flink connector源码分析分析过sourcefunction,所以我们就直接看open和run的逻辑,就不细节讲open和run是如何以及何时调用的,总结上一篇博客来说就是先回调用open初始化sourcefunction一些属性,run就是把数据拉取过来然后emit出去。
所以首先来看看open
public void open(Configuration parameters) throws Exception {
super.open(parameters);
ThreadFactory threadFactory = new ThreadFactoryBuilder()
.setNameFormat("debezium-engine")
.build();
this.executor = Executors.newSingleThreadExecutor(threadFactory);
}可以看到open这里就是创建一个线程池,非常简单。接下来看看run
public void run(SourceContext sourceContext) throws Exception {
properties.setProperty("name", "engine");
properties.setProperty("offset.storage", FlinkOffsetBackingStore.class.getCanonicalName());
if (restoredOffsetState != null) {
// restored from state
properties.setProperty(FlinkOffsetBackingStore.OFFSET_STATE_VALUE, restoredOffsetState);
}
// DO NOT include schema payload in change event
properties.setProperty("key.converter.schemas.enable", "false");
properties.setProperty("value.converter.schemas.enable", "false");
// DO NOT include schema change, e.g. DDL
properties.setProperty("include.schema.changes", "false");
// disable the offset flush totally
properties.setProperty("offset.flush.interval.ms", String.valueOf(Long.MAX_VALUE));
// disable tombstones
properties.setProperty("tombstones.on.delete", "false");
// we have to use a persisted DatabaseHistory implementation, otherwise, recovery can't continue to read binlog
// see https://stackoverflow.com/questions/57147584/debezium-error-schema-isnt-know-to-this-connector
// and https://debezium.io/blog/2018/03/16/note-on-database-history-topic-configuration/
properties.setProperty("database.history", FlinkDatabaseHistory.class.getCanonicalName());
// reduce the history records to store
properties.setProperty("database.history.store.only.monitored.tables.ddl", "true");
if (engineInstanceName == null) {
// not restore from recovery
engineInstanceName = UUID.randomUUID().toString();
FlinkDatabaseHistory.registerEmptyHistoryRecord(engineInstanceName);
}
// history instance name to initialize FlinkDatabaseHistory
properties.setProperty(FlinkDatabaseHistory.DATABASE_HISTORY_INSTANCE_NAME, engineInstanceName);
// dump the properties
String propsString = properties.entrySet().stream()
.map(t -> "\t" + t.getKey().toString() + " = " + t.getValue().toString() + "\n")
.collect(Collectors.joining());
LOG.info("Debezium Properties:\n{}", propsString);
this.debeziumConsumer = new DebeziumChangeConsumer<>(
sourceContext,
deserializer,
restoredOffsetState == null, // DB snapshot phase if restore state is null
this::reportError);
// create the engine with this configuration ...
this.engine = DebeziumEngine.create(Connect.class)
.using(properties)
.notifying(debeziumConsumer)
.using((success, message, error) -> {
if (!success && error != null) {
this.reportError(error);
}
})
.build();
if (!running) {
return;
}
// run the engine asynchronously
executor.execute(engine);
// on a clean exit, wait for the runner thread
try {
while (running) {
if (executor.awaitTermination(5, TimeUnit.SECONDS)) {
break;
}
if (error != null) {
running = false;
shutdownEngine();
// rethrow the error from Debezium consumer
ExceptionUtils.rethrow(error);
}
}
}
catch (InterruptedException e) {
// may be the result of a wake-up interruption after an exception.
// we ignore this here and only restore the interruption state
Thread.currentThread().interrupt();
}
} 代码有点多但是逻辑不难理顺吧,先是设置一大堆默认属性,这些属性当然是为了给debenium使用。接下来创建了一个DebeziumChangeConsumer,以及用properties和DebeziumChangeConsumer创建了DebeziumEngine,最后用线程池来执行DebeziumEngine,不懂debenium没关系(我也不懂),但是看看DebeziumChangeConsumer和DebeziumEngine两个类,就知道这个sourcefunction很简单。
先来看看DebeziumChangeConsumer
public class DebeziumChangeConsumer implements DebeziumEngine.ChangeConsumer>
public interface ChangeConsumer {
void handleBatch(List var1, DebeziumEngine.RecordCommitter var2) throws InterruptedException;
} 可以看到DebeziumChangeConsumer只实现了一个接口,接口也只有一个方法,
public void handleBatch(
List> changeEvents,
DebeziumEngine.RecordCommitter> committer) throws InterruptedException {
try {
for (ChangeEvent event : changeEvents) {
SourceRecord record = event.value();
deserialization.deserialize(record, debeziumCollector);
......
// emit the actual records. this also updates offset state atomically
emitRecordsUnderCheckpointLock(debeziumCollector.records, record.sourcePartition(), record.sourceOffset());
}
} catch (Exception e) {
LOG.error("Error happens when consuming change messages.", e);
errorReporter.reportError(e);
}
} 可以看到这个逻辑非常简单,就是先把debenium获取到的cdc数据先反序列化一波,直接emit到下游了,那问题来了,handleBatch中的参数数据是如何获取的呢,既然是debenium获取的,而且只有一个DebeziumEngine(这个是个runnable)。那咱们就先看看DebeziumEngine,因为DebeziumEngine是debezium的组件跟flink没关系,所以可能不太懂,但是没关系,我之前也没看过debezium,你慢慢分析他就出来了。好了,刚才咱们知道DebeziumEngine是个Runnable(其实也是个接口,默认实现为EmbeddedEngine)。既然是runnable那就主要看看他的run方法。
public void run() {
if (this.runningThread.compareAndSet((Object)null, Thread.currentThread())) {
......
this.task = (SourceTask)taskClass.getDeclaredConstructor().newInstance();
......
this.task.initialize(taskContext);
this.task.start((Map)taskConfigs.get(0));
while(this.runningThread.get() != null) {
List changeRecords = null;
changeRecords = this.task.poll();
this.handler.handleBatch(changeRecords, committer);
}
......
}其实run方法有200行代码,我把没多大用处的省略了,留下了几行重要的代码,相信你看这几行也能懂得大概意思了,首先会创建一个task,然后启动他,明显是启动task去获取任务。接下启动任务之后就会在循环里面poll数据,说明task里面肯定有一个组赛队列,接着handler会处理获取的数据,还记得刚才咱们说的DebeziumChangeConsumer吗,他就是咱们的handler呀,正好刚才咱们还愁着handleBatch中的参数从哪里来,现在看到了吧,就是从这里来。
现在咱们知道原来数据是从task的阻塞队列里面的,那么,task启动之后肯定是把数据方法阻塞队列中了,基于这样的猜想咱们来看看task。这里咱们主要看看task的start做了啥
public final void start(Map props) {
......
this.stateLock.lock();
......
this.coordinator = this.start(config);
......
this.stateLock.unlock();
}
public ChangeEventSourceCoordinator start(Configuration config) {
......
BinlogReader binlogReader = new BinlogReader("binlog", this.taskContext, (HaltingPredicate)null);
chainedReaderBuilder.addReader(binlogReader);
......
this.readers = chainedReaderBuilder.build();
this.readers.uponCompletion(this::completeReaders);
this.readers.initialize();
this.readers.start();
......
} 第一个start不用看,第二个start是MySqlConnectorTask实现的,看类名明显知道这是处理mysql的,其实在start里面会创建好多Reader(BinlogReader用于增量获取,SnapshotReader用于第一次全量拉取),然后放到ChainedReader中。后面我就不继续跟了,比较繁琐,我说一下核心逻辑。
1.MySqlConnectorTask的ChainedReader包含多个Reader,这些reader就是用来获取全量数据和增量数据,这些数据会放进抽象类AbstractReader中的BlockingQueue中
2.在Debezium的run方法中会从task中poll数据
3.task会从Reader中的blockingQueue拿数据
4.数据拿到之后会交给DebezinumConsumer,DebezinumConsumer会先反序列化数据,然后emit给下游
大概画个图吧,不然还是会懵,因为文笔不好,不能很好表达。

其实就是把数据获取之后就放到阻塞队列中,而不能直接emit,这也是为了解耦。线程直接把读取、反序列化、发送下游一起做的话,会使系统吞吐率下降。(比如读取半天也没有读取到,那就半天也不能发射数据给下游)
总结:到这里就完了,其实这个source从这个图中看,逻辑还是很简单的。因为再继续跟下去都是debezium的数据,所以我就不跟了。这篇博客其实写的很仓促,用了接近3个小时。主要是周末时间太短了呀,没时间写,请看官们见谅啊。咱们下周见。