汇编语言入门
目录
前言:
为什么要学汇编?
学前必备知识:
第一章:汇编版本
第二章:内存地址的分配
第三章:现代计算机的基本框架
图灵计算机:
冯诺依曼计算机体系:
现代计算机基本架构:
第四章:主存储器的内部结构
第五章:DosBox的debug模式
DEBUG模式下的常用命令
r命令:
d命令:查看内存中的内容
E命令:修改内存中的内容
第六章:jmp指令
jmp指令:跳到某个具体的内存地址,执行该内存地址上的指令,同时从下往上执行。
inc指令:用法:inc bx,让bx中的值加1
第七章:字
第八章:CPU从内存读取数据
第九章 汇编对栈的访问
汇编如何指挥入栈、出栈
栈段寄存器SS,栈顶指针寄存器SP
栈的操作
执行入栈、出栈时,如何保证栈顶不超出栈空间呢?
小结一句话:在汇编中,我们可以自己修改SS,SP的值,来人为的创造出一块栈空间。
目前学习了三种段:指令段,数据段,栈段
编辑
第九章:认识汇编代码
伪指令:
第十章:汇编代码案例
第十一章:运行和追踪汇编代码
第十二章:
第十三章:Loop指令
第十四章:段前缀
段前缀的必要性:
常用的写法:loop和[bx]配合使用,访问一段连续的内存单元
段附加寄存器es的用法:重要
前言:
为什么要学汇编?
在现代社会中,汇编似乎很少有人会用,是否这就代表着它的没落呢?
其实不然,汇编在一些我们不太知道的小众领域仍然发光发热,如逆向工程(外挂制作、软件破解)、驱动程序设计等,此外,汇编是一种低级语言,它比任何一门计算机语言都贴近计算机底层,是所有高级语言的鼻祖,学习它,能让你真正理解高级语言,从一个使用者,变成一个真正的编程大牛!
如果你在使用java,学习汇编,你可以深入理解jvm底层运行机制,而不再陷入熟读八股文但是却造不出一个轮子的困境,
如果你在使用C,C++,它可以帮助你真正的理解C程序的底层机制,让你理解指针,引用,内存地址,寄存器这些概念的真面目,
可以这么说,如果你要真正理解C语言,C++,java,你不学汇编是永远达不到那个水平的!!!
SO,在这个浮躁的社会,跟我一起学汇编吧!
学前必备知识:
由于汇编是一门直接跟计算机硬件打交道的语言,请你学习我的本教程之前,如果有时间请务必学习一下计算机组成原理这门课程,如果还学了操作系统就更好了,这对你在学习过程中不被繁杂的硬件知识所恶心非常有帮助,
个人推荐视频链接:王道计算机考研 计算机组成原理_哔哩哔哩_bilibili
第一章:汇编版本
汇编语言不像我们学习java、C等语言,这些高级语言整体都是在各自的初始版本上迭代至今的,如java迭代至今,已经到了jdk17。汇编与它们都不同,不同的CPU架构对应不同的汇编版本,
汇编版本主要分为3个:
- X86架构的INTEL CPU :我们把Intel X86 CPU所采用的汇编,称为X86版本的汇编,
- X86架构的CPU,其实就是已经快要绝迹了的32位架构,如果你的计算机是一个32位计算机,那么它就是采用的X86架构的CPU,采用的汇编指令也是X86。
- X64架构的INTEL CPU:我们把INTEL X64 CPU采用的汇编,称为X64版本的汇编,
- 它就是我们现在最常见的64位计算机所采用的CPU。
- ARM架构的CPU:ARM芯片主要存在于手机端,且在手机端已经占据了绝对统治地位,如苹果的M1,M2就是采用的ARM架构。
汇编可以说是跟CPU深度绑定,不同版本的CPU,内存地址结构也大不相同,所以它们的汇编指令也会有差异,总体来说:X86与X64相似,ARM独自成一套体系,
而我们本次作为入门的汇编版本《《《=====》》》是比X86更早的8086版本,X86是由8086发展而来的,所以它比X86更简单,如果我上来就介绍难度更高的X86,X64,可能很难让人看懂。
第二章:内存地址的分配
在8086PC机中,地址总线的条数是20根,所以它能表示的总内存大小是:2^20 * 1B = 1048576B = 1024 * 1024 B = 1024 * 1KB = 1MB,所以,8086PC机中内存总的大小最多是1MB,受限于地址总线的条数无法再多了。
但是,在一个正常的计算机中,还会有显卡,网卡等各类BIOS ROM设备,CPU也要操作它们,所以为了控制上的方便,计算机的设计者们对内存条、显存、网卡等各类BIOS,系统BIOS都进行了统一编址,
最终呈现的效果就是这样的: 各类设备的存储器分布不在不同位置,但是它们都统一归为了逻辑上的整体。
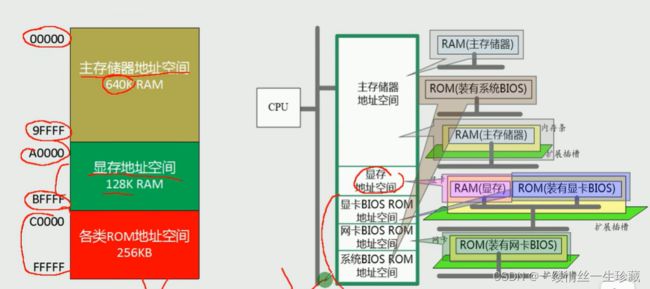
内存地址中:
00000 到 9FFFF是主存储器地址空间,占640KB,它由DRAM芯片组成
A0000 到 BFFFF是显存地址空间,占128KB,它也是有RAM芯片组成
C0000 到 FFFFF是各类BIOS ROM地址空间,如显卡BIOS ROM,网卡BIOS ROM,系统BIOS ROM,占256KB,(但系统BIOS ROM是在最下面)
你可能会有疑问,为什么8086PC机中内存地址是5位的十六进制数呢?
还是因为8086PC机的地址总线是20条,所以它能代表的最大宽度是20位,我们为了方便,用十六进制替代二进制进行记忆,实际上计算机底层还是以二进制进行编址,1个16进制位 = 4个二进制位,因为 2^4 = 16,所以用16进制表示20位的二进制,必须用5位16进制才能表示完。
第三章:现代计算机的基本框架
图灵计算机:
最早的计算机由英国科学家,计算机科学之父,人工智能之父图灵创造,它将人类思考的方式类比到计算机上,如:人类计算1+2=3,就是先从人眼输入1 和 2,同时输入控制信号 + ,这三个信息被传输到人的大脑,经由大脑运算后,再通过手将结果3输出到纸上,
在这个过程中,人眼就是输入设备,1和2就是输入进来的数据,+ 就是控制信号,大脑就是运算器,手就是输出设备,至此,人类历史上的第一个简单计算机框架诞生,这是一个历史性的时刻!
冯诺依曼计算机体系:
随着时间发展,冯诺依曼提出了更贴近现代的计算机框架====冯诺依曼计算机体系,
以存储器为核心的计算机框架,

又由于运算器与控制器之间的关系十分紧密,所以在现代计算机中,运算器与控制器一般都是被集成在同一个芯片上的,这个芯片就叫做CPU。
而CPU与主存储器一起共同构成了主机,(该主机非彼主机)
所以把上面的架构图转换一下,就是这样:
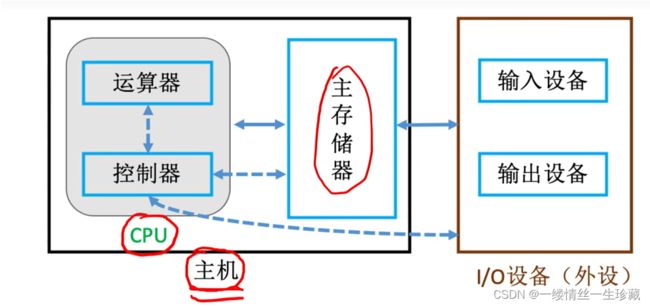
现代计算机基本架构:

第四章:主存储器的内部结构

第五章:DosBox的debug模式
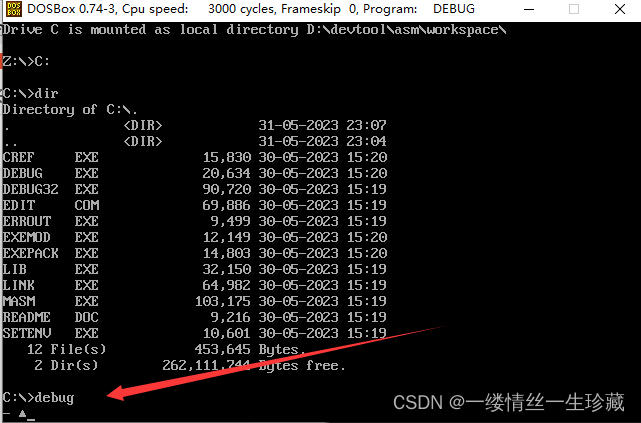
第一步:启动DosBox
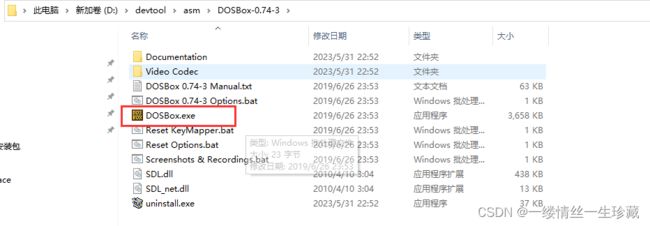
第二步:创建一个文件夹用于存放汇编代码 D:\devtool\asm\workspace
第三步:将常用工具放入workspce中
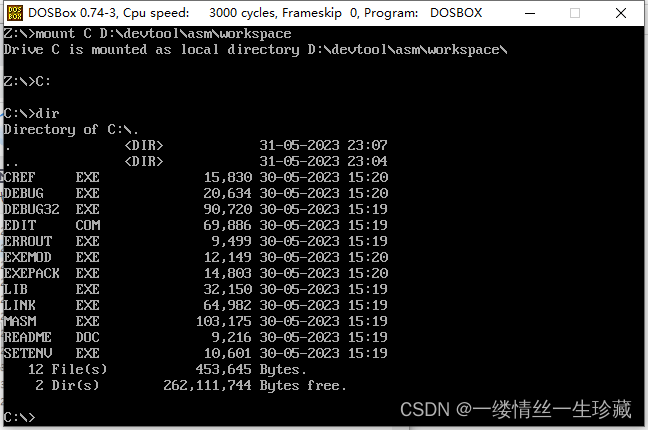
第四步:挂载,在DosBox中输入MOUNT C D:\devtool\asm\workspace
第五步:输入C: 进入虚拟的c盘
第六步:输入dir命令,查看当前文件夹中有什么,
我们可以看到,刚才拷贝进来的exe程序都在。
第七步:输入debug命令,就可以启动debug窗口,
下面这个样子就代表进入了debug模式
DEBUG模式下的常用命令
r命令:
1. r 查看当前所有寄存器的内容
2. r ax 还可以修改一个寄存器的值,输入r ax,再按回车,再输入新值就可以了,这个新值默认是16进制。
r后面直接跟寄存器名,中间没有空格,也是一样的效果,如rax也是修改寄存器ax的值。
d命令:查看内存中的内容
1. d 段地址:偏移地址,可以从指定地址处,开始显示内存中128个字节值。
2. d 段地址:偏移地址 结尾偏移地址,列出内存中指定地址范围内的内容,结尾偏移地址相当于规定了一个范围,
举例:d 2000:0000 000f,这样的话,就会列出16个字节的内容,也可以写成d 2000:0 f
3. d后面如果不跟地址,那么就会默认有个地址,从这个默认地址开始显示内存中128个字节的内容
E命令:修改内存中的内容
1. e 段地址:偏移地址 数据1 数据2 ...
举例①:e 2000:0000 12,意思就是将逻辑地址为2000:0000的内存内容,修改为十六进制的12,注意:8086中是以1个字节为编址单位。
举例②:e 2000:0000 12 34 56 AB 3F F3,就会把从2000:0000开始的内容,依次变成12 34 56 AB 3F F3,再用d 2000:0000命令查看,就是这个样子:
 值得注意的是:右边我圈起来的,就是左边数据的ASC码形式,比如十六进制的34就是ASC码中的4,56对应V,3F对应?,其他的几个在ASC中没有含义,所以就是圆点。
值得注意的是:右边我圈起来的,就是左边数据的ASC码形式,比如十六进制的34就是ASC码中的4,56对应V,3F对应?,其他的几个在ASC中没有含义,所以就是圆点。
2. e 段地址:偏移地址 通过逐个询问的方式进行修改
如果敲空格,就代表同意修改,并继续修改下一个字节。
如果敲回车,就代表结束修改。
第六章:jmp指令
jmp指令:跳到某个具体的内存地址,执行该内存地址上的指令,同时从下往上执行。
在汇编中,不允许直接给段寄存器赋立即数,比如CS,IP这两个段寄存器的值就无法使用debug中的r命令赋值,也不能使用汇编的mov指令赋值,只能是CPU根据自己的规则自己修改段寄存器的值,因为段寄存器很关键,设计者们担心我们弄错。
但是提供了一个jmp指令,通过jmp 段地址:偏移地址,就可以跳到某个具体的内存地址上,执行该地址处的指令,这句话的本质是:将CS段寄存器中的值修改为jmp后面的段地址,IP段寄存器中的值修改为后面的偏移地址。
上面 jmp 段地址:偏移地址 这种写法是同时修改CS、IP中的内容,
还可以仅仅修改IP寄存器中的内容,用法是:jmp 某通用寄存器的名称,比如 jmp ax, 这句话的意思,就是将通用寄存器ax中的值作为偏移地址传到IP中,然后它会找到当前状态下的CS段寄存器中的段地址,将两者拼接成真实物理地址,从而找到要跳转的位置。
inc指令:用法:inc bx,让bx中的值加1
第七章:字
对8086CPU来说,它是16位的,它就是16位作为一个字的长度,
对64位CPU来说,他就是64位作为一个字,32位CPU,就是32位作为一个字。
第八章:CPU从内存读取数据
汇编案例1:
这段代码仔细看,
mov bx, 1000H // 先将1000H放到通用寄存器的原因是:不能直接给段寄存器赋立即数,但是可以将通用寄存器中的立即数赋给段寄存器,所以要用通用寄存器中转一下。
mov ds, bx
mov al,[0] // [0]表示偏移地址,偏移地址为0000,地址参数要用中括号括起来,0000可简写为0,所以偏移地址0000就是[0],mov al,[0] 的意思是:它会自动去找当前状态下段寄存器ds中的数据段地址,将数据段地址乘以16,再与偏移地址[0]相加,就可以得到数据的真实物理地址,所以mov al,[0]的意思就是将该真实物理地址中的数据,赋给通用寄存器ax中的低8位寄存器al;
为什么不能直接将立即数赋给段寄存器呢?因为计算机的设计者们没有设计这样的电路。
汇编案例2:
mov bx, 1000H
mov ds, bx
mov [0] ,al // 将al中的数据,赋给真实物理地址 ds + [0],真实物理地址也就是10000H
注意:这两种写法的区别
第一种: 第二种:
mov bx, 1000H mov bx, 1000H
mov ds, bx mov ds, bx
mov al,[0] mov ax,[0]
第一种因为是al寄存器,它是8位的,所以它从真实物理地址 1000:0处读取数据时,读出来的是字节型数据,也就是只读8位出来。
第二种因为是ax寄存器,它是16位的,所以它从1000:0处读取数据时,读出来的是字型数据,也就是会读16位出来。
第九章 汇编对栈的访问
汇编如何指挥入栈、出栈
push指令:向栈中放入数据
pop指令:从栈中取数据(取的是栈顶的数据)
举例:
push ax, 意思是将寄存器ax中的数据存入栈,
pop ax,意思是取出栈顶的数据放入ax中,
注意:出栈,入栈都是以字为单位,不能以字节为单位,如果要字节大小的数据,就要在前面补0。
注意:栈不是属于操作系统,也不是属于某种语言,是在CPU中用电路就已经实现了栈结构。
栈段寄存器SS,栈顶指针寄存器SP
刚才说,CPU已经通过电路实现了栈的结构,它将某片内存空间划分成了栈空间,那么CPU到底是如何知道哪一片空间就是栈呢?就需要有个东西来记录,在8086CPU中,有两个寄存器,
SS寄存器,该寄存器专门用来存放栈顶的段地址,
SP寄存器,该寄存器专门用来存放栈顶的偏移地址,
---在任何时刻,SS:SP组成的真实物理地址都指向栈顶,
栈的操作
在汇编中,我们可以通过指定SS和SP的值,来将一段内存空间设置成栈空间,就如下面的代码
mov ax,1000H
mov ss,ax //将1000H移入SS中,此时SS中的段地址就是1000H,这句话还有个含义是:指定了栈底的位置是10000H+0 = 10000H
mov sp,0010H // 将0010H移入栈顶指针寄存器SP中,这句话的含义是:将10000H + 0010H = 10010H位置作为栈顶
这样执行后,我们就开辟了一块从10000H到1000FH的空间为栈空间,初始时SS:SP为1000H:0010H,他就是栈顶,但是栈顶是不是栈空间的,从栈顶上面的一个字节到栈底的位置,才是真正存放数据的地方。

接着,我们可以往栈里面推入数据,这个操作叫压栈,还可以用pop命令出栈。
注意:每执行一次push指令,SP中的偏移地址就会-2,也就是栈顶往上移动,反过来,每执行一次pop指令,SP的值就会+2,为什么是2呢?因为入栈出栈是以1个字为单位,8086CPU是16位,一次就是1个字,两个字节,所以就是2。
mov ax,001AH
mov bx,001BH
push ax
push bx
push ax
push bx

执行入栈、出栈时,如何保证栈顶不超出栈空间呢?
CPU只知道栈顶在何处(由SS:SP指定),但是CPU是不知道栈空间有多大的,
所以非常可能出现栈顶超界问题,而在汇编语言中,它并不会像高级语言那样对栈顶超界做出检查,只有我们程序员自己知道栈空间的大小,所以我们在编程时要自己注意这个问题。
小结一句话:在汇编中,我们可以自己修改SS,SP的值,来人为的创造出一块栈空间。
目前学习了三种段:指令段,数据段,栈段
综合案例,请你用汇编,自己将下图中的内存分为三种段:

第九章:认识汇编代码
伪指令,由编译器执行的指令,不会被CPU执行,伪指令是用来指导编译器工作做的。
最后两句的
mov ax,4c00h
int 21h 这两句话的意思相当于C++中的return 0,表示程序结束,将程序的控制权交给操作系统

伪指令:
段定义:一个汇编程序是由多个段组成,这些段被用来存放指令,数据,或被当做栈来使用。
一个有意义的汇编程序至少要有一个段,这个段用来存放指令,也就是指令段,也可以叫代码段。
格式:
段名 segment ---表示段的开始
段名 ends(有s) ---表示段的结束
end (没有s):表示汇编程序的结束,不加的话,CPU不知道哪里是会汇编程序的结束。
assume(假设),用法:assume cs : 段名 意思是:让某个段寄存器,这里是让CS段寄存器与该段进行绑定。
第十章:汇编代码案例
案例1:求2的3次方
assume cs:abc
abc segment
mov ax,2
add ax,ax
add ax,ax
mov ax,4c00h
int 21h
abc ends
end

第十一章:运行和追踪汇编代码
DosBox中输入debug p4-1.exe, p4-1.exe是编译好的程序名,表示用debug模式装载该程序。

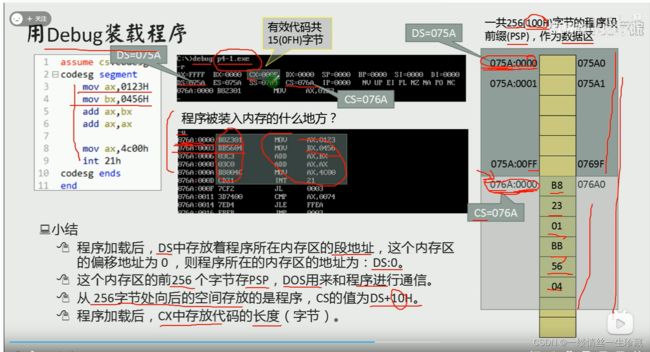
第十二章:

第十三章:Loop指令
用法:计算2的12次方

s:add ax,ax 中的s是标号,也就是一个标记
add ax,ax是要循环的语句,
整体的过程就是:先执行一次add ax,ax 再没有执行loop s之前,将cx中的值减1,再判断cx中的值是否为0,如果不为零,就执行loop s,就会跳转到标记s处,执行add ax,ax语句,直到cx中的值等于0了就会跳出循环,所以cx中初始值是多大,那么就会循环多少次。
所以,在进入loop循环之前,一定要给cx赋值
loop编程案例2:计算123x236,结果要存储在ax中,不用乘法指令,因为还没学,用loop指令做
assume cs:code
code segment
mov ax,0
mov cx,123
s: add ax,236
loop s
mov ax,4c00h
int 21h
code ends
end
loop编程案例3:取出ffff:0006字节单元中的数据,将其乘以3,并存储到dx中
assume cs:code
code segment
mov dx,0
mov ax,0ffffH //注意:在汇编中,数据不能以字母开头,要在前面加0,所以就是offffH
mov ds,ax //指定数据段DS的值为ffffH
mov bx,6
mov al,[bx] //在ffff:0006处取出1个字节数据放入al中
mov ah,0 // 这里将ah也置为0,这里非常重要,有两点原因:①将高八位置为0,那么ax的值就跟al相等了,就是等效的。②万一ah中原来就有数据,你就将其抹除了,否则可能出bug。
mov cx,3
s:add dx, ax //在此时ax的值就跟al保持一致了
loop s
mov ax,4c00H
int 21h
code ends
end
其他必要的考虑,在计算过程中,我们还要考虑寄存器dx中的数据是否会超出dx的最大范围,dx是16位的,它最大能存的无符号数是65535,而ffff:0006是一个字节型的数据,它最大的值是255,乘以3也不会超过65535,所以不会超界,但是假如把dx换成dl,超界就是必然的了,因为dl最大的数就是255。 这个问题非常重要。
第十四章:段前缀
段前缀的必要性:
一个编译的异常现象:使用mov ax,[0] 这种操作内存地址中的数据的语法,可能在编译时,会把[0] 编译成立即数0,变成mov ax,0 整个意思就完全变了,这是编译中存在的问题,不是bug,但原因现在还说不清楚,后面才能解释。

解决办法:

这种写法中的ds: 就是段前缀,
总结一句话就是:当你要把一个常量(也就是数字)作为偏移地址使用时,请你在前面加上段寄存器。
常用的写法:loop和[bx]配合使用,访问一段连续的内存单元
案例:计算ffff:0~ffff:b字节单元中的数据的总和,将结果存储在dx中
assume cs:code
code segment
mov dx,0
mov ax,0ffffH
mov ds,ax
mov bx,0
mov cx,12
s:mov al,ds:[bx]
mov ah,0
add dx,ax
inc bx
loop s
mov ax,4c00h
int 21h
code end
end
段附加寄存器es的用法:重要
案例:将ffff:0~ffff:b中每个字节的值,移动到0:200~0:20b处, (注意,在汇编中,这样写是非常不安全的,因为你并不知道目标处的地址是否存放着系统指令,如果是一些固定的地址,存放着固定的系统指令,你这样操作就会把系统指令覆盖掉,导致系统异常,我这里只是为了讲案例才这么做。)

根据我们前面学习的知识,我们可以给一个初步的方案:在loop循环中将代码段寄存器ds的值不断的来回修改,一会儿是ffff,一会儿是0,这样才能在两个段中来回的切换,显然这种方式比较麻烦。

造成这个问题的原因:实际上是因为数据段地址寄存器只有一个ds,要是多一个数据段地址寄存器就好了,此时段附加寄存器es就有用了,就像下面这样:
注意:下图中的mov dl,[bx] ,这句没有段前缀的,默认就是用ds中的段地址,

第十五章:在代码段中使用数据
dw指令:定义字型数据,define word
db指令:定义字节型数据,define byte
dd指令:定义双字型数据,define double

上面的代码依然有问题,因为代码段一执行时,指令指针寄存器IP中的值就是0000,代表从代码段第一个位置读指令,而我们上面的案例中,代码段的前列全是数据,后面才是代码,你将ip指向数据,最终就会出错。
所以应该这样调整:在代码段中,你应该用start标号标注出第一条指令的位置,同时在end后面加上start标号,这才是汇编的正确写法(重要)。

第十七章:在代码段中使用栈
案例:利用汇编完成下面功能----利用栈,将程序中定义的数据逆序存放

第十八章:将数据,代码,栈放在不同的段中(正确的汇编代码结构)
正确的结构:
这种结构的好处:段跟段之间分开了,代码更容易读,并且有了start标号,当这三个段被读取到内存中时,CPU就知道将start标号所在位置的地址作为IP寄存器的初始化地址,也就是整个程序的入口。

注意:在写汇编代码时,我们必须初始化ds,ss,sp寄存器,但是ip寄存器,cs寄存器我们不用初始化,ip寄存器的值就是start标号所在的位置,cs寄存器的值:因为一个程序中至少要有一个段,就是代码段,所以肯定会有cs寄存器,所以cs寄存器的值在程序被加载到内存中时,就已经被自动确定好了,不用我们处理。
但ds,ss,sp的值需要我们自己初始化,就像下图中圈起来的地方,用data段,stack段的地址给ds,ss赋值。

第十九章:内存寻址方式
1.处理字符的方法
在ASC码中,

汇编中的与运算:and dest,src 将一个字节的dest与src做与运算,然后将结果放入dest中。
汇编中的或运算:or dest,src 将一个字节的dest与src做或运算,然后将结果放入dest中。
例题:大小写转换

2.[bx+idata]方式寻址
举例:mov ax,[bx+200] 的含义就是:将偏移地址为bx+200,段地址为ds中数值,的地址中的数据放入ax中。
指令mov ax,[bx+200]的其他等效写法:
- mov ax,[200+bx]
- mov ax,200[bx] 注意:不是乘
- mov ax,[bx].200
3.用[bx+idata]对大小写字符转换程序做优化
之前的代码是分两个循环执行的,我们可以用[bx+idata]实现,在一个循环中完成转换。

优化后的汇编代码,用C语言表示就是:

所以说:【bx+idata】的这种寻址方式,为高级语言实现数组提供了便利,其中bx的值就相当于数组的下标。
第二十章: 用dup指令设置重复的内存空间
功能:dup用来和db,dw,dd等数据定义的伪指令配合使用,用来进行数据的重复设置
示例:

案例1:用dup定义一个容量为200字节的栈段


案例2:

第二十一章:流程转移与子程序
1.流程转移
一般情况下,指令是顺序的逐条执行的,但是我们也经常需要改变指令的执行顺序。
转移指令:就是用来控制CPU执行内存中指定的指令,而跳过本来应该执行的指令。本质上它是修改了IP寄存器中的值,或同时修改了CS,IP中的值。
转移指令分类:
====== 按转移行为分:
段内转移:只修改ip的值,如jmp ax,就是把ax中的值作为偏移地址,仍然以ds作为段地址
段间转移:同时修改cs和ip,如jmp 1000:0,或jmp 1000:[ax]
====== 按指令对IP修改的范围不同分:
段内短转移:IP修改范围为-128~127 1个字节
段内近转移:IP修改范围为-32768~32767 1个字
====== 按转移指令分:
无条件转移指令:jmp
条件转移指令:jcxz,根据寄存器cx的值是否为0进行转移
循环指令:loop
过程:
中断:
2.如何判断一个指令是多少字节:
汇编指令长度与寻址方式有关,规律或原则如下:
一、没有操作数的指令,指令长度为1个字节
二、操作数只涉及寄存器的的指令,指令长度为2个字节
如:mov bx,ax
三、操作数涉及内存地址的指令,指令长度为3个字节
如:mov ax,ds:[bx+si+idata]
四、操作数涉及立即数的指令,指令长度为:寄存器类型+1
8位寄存器,寄存器类型=1,如:mov al,8;指令长度为2个字节
16位寄存器,寄存器类型=2,如:mov ax,8;指令长度为3个字节
五、跳转指令,分为2种情况:
1、段内跳转(指令长度为2个字节或3个字节)
jmp指令本身占1个字节
段内短转移,8位位移量占一个字节,加上jmp指令一个字节,整条指令占2个字节
如:jmp short opr
段内近转移,16位位移量占两个字节,加上jmp指令一个字节,整条指令占3个字节
如:jmp near ptr opr
2、段间跳转,指令长度为5个字节
如:jmp dword ptr table[bx][di]
或 jmp far ptr opr
或 jmp dword ptr opr
注意:形如“jmp 1234:5678”的汇编指令,是在Debug中使用的汇编指令,汇编编译器并不认识,如果在源程序中使用,那么在编译时便会报错。
3.offset
格式:offset + 标号
举例:

第一个offset跟的标号是start,由于start这一句是codesegment中的第一句话,所以start这个标号的值就是0,所以offset start = 0,那么mov ax,offset start 就相当于是mov ax,0。
第二个offset后面跟的标号是s,mov ax,offset start指令总共占3个字节,那么标号s的值就是3,所以mov ax,offset s就相当于mov ax,3。
练习:对下面的代码添加两条指令,使程序在运行中将标号s处的指令复制到标号s0处

答案:

第二十二章:jmp指令
