GPT2中文模型本地搭建(二)
GPT2中文模型本地搭建(二)
- 1、简单介绍
-
- 1.1 bert4keras是什么,与Keras有什么关系?
- 1.2 常用的预训练模型加载框架有几种?
- 1.3 预训练模型常见版本
- 2、GPT2-ML 开源中文模型本地搭建
-
- 2.1 开发环境准备
- 2.2 下载代码
- 2.3 下载模型
- 2.4 加载模型
-
- 1)先安装bert4keras
- 2)下载训练模型的代码,再补全下插件
- 3)修改代码模型地址
- 4)运行模型查看测试效果
- 2.5 测试效果
- 3、GPU运行
-
- 3.1 要检查计算机是否支持 NVIDIA 显卡,您可以执行以下步骤
- 3.2 集成显卡,不支持
- 3.3 独立显卡,支持
-
- NVIDIA 显卡驱动安装
- CUDA 工具包安装
- cuDNN 库安装
1、简单介绍
GPT2_ML项目是开源了一个中文版的GPT2,而且还是最大的15亿参数级别的模型。
OpenAI在GPT2的时期并没有帮忙训练中文,上篇文章的验证也可说明此问题,对应的模型直接上GitHub上下载即可。
本文主旨快速搭建本地模型,更全的攻略,大家也可以到GitHub中慢慢摸索。
本文是基于bert4keras来加载模型与运行,需要先了解下一些概念。
1.1 bert4keras是什么,与Keras有什么关系?
bert4keras是一个基于Keras的BERT预训练模型工具包。它提供了一组简单易用的API,可以轻松加载和使用预训练的BERT模型,以进行各种自然语言处理(NLP)任务,例如文本分类、命名实体识别(NER)、问答等。
虽然bert4keras是基于Keras框架开发的,但它与原始的Keras库有所不同。它在Keras的基础上做出了一些修改和扩展,以更好地支持BERT模型的训练和应用。例如,它提供了自定义的优化器、损失函数和评估指标,以及对BERT模型结构的修改和扩展。
总之,bert4keras是一个强大的NLP工具包,旨在使使用BERT模型变得更加容易和高效,并提供许多额外的功能和扩展。如果你正在进行NLP任务,并且需要使用BERT模型,那么bert4keras可能是一个很好的选择。
1.2 常用的预训练模型加载框架有几种?
-
TensorFlow Hub:TensorFlow 官方提供的加载和使用各种预训练模型的一种方式。
-
Hugging Face Transformers:一个基于 PyTorch 和 TensorFlow 的 NLP 框架,主要用于加载和使用各种预训练的 Transformer 模型,如 BERT、GPT-2 等等。
-
Keras Applications:Keras 官方提供的加载和使用各种预训练模型的库,包括 VGG、ResNet、Inception 等等。
-
MXNet Gluon:MXNet 官方提供的深度学习框架,内置了多种经典的预训练模型,可以通过一行代码加载和使用。
-
PyTorch Hub:类似于 TensorFlow Hub,是 PyTorch 官方提供的加载和使用各种预训练模型的库。
除此之外,还有一些第三方的加载预训练模型的库,如 keras-bert、bert4keras 等等,都可以方便地加载和使用各种预训练模型。
1.3 预训练模型常见版本
- BERT:Bidirectional Encoder Representations from Transformers (BERT) 是由 Google 提出的预训练模型,通过双向 Transformer 编码器训练来获得语言表示。BERT 取得了多个 NLP 任务的 SOTA 结果。
- ALBERT:A Lite BERT (ALBERT) 是一种轻量级的 BERT 模型,采用嵌套 LSTM 和跨层参数共享等技术来减少模型参数量和计算资源需求。
- RoBERTa:Robustly Optimized BERT Pretraining Approach (RoBERTa) 是 Facebook 提出的一种预训练语言模型,针对 BERT 中潜在的过拟合问题进行了优化。
- NEZHA:NEZHA 是由华为公司提出的 BERT 衍生模型,对训练策略和网络架构进行了改进,取得了与 BERT 相当的性能。
- GPT2:Generative Pre-trained Transformer 2 (GPT-2) 是 OpenAI提出的语言模型,通过单向 Transformer 解码器进行训练,能够生成高质量的自然语言文本。
- T5:Text-to-Text Transfer Transformer (T5) 是 Google 提出的一种基于Transformer 的通用语言模型,可以应用于各种 NLP 任务,如文本分类、问答系统等。
- bert4keras 支持上述多种预训练模型的加载和 fine-tuning,可以方便地应用于各种 NLP 任务中。 OpenAI GPT(Generative Pre-training Transformer):OpenAI 提出的基于 Transformer的语言模型,采用单向 Transformer 解码器进行训练。
- XLNet:由 CMU 和 Google 提出的预训练模型,采用从左到右和从右到左的两个方向来生成上下文表示。
- ELECTRA:Efficiently Learning an Encoder that Classifies Token Replacements Accurately (ELECTRA) 是谷歌提出的预训练模型,通过用一个 diskriminator来训练生成模型,可以大大提高模型的训练效率。
- DistilBERT:DistilBERT 是一种经过压缩的 BERT 模型,参数量约为原始 BERT 模型的一半,同时具有相似的性能。
- XLM:Cross-lingual Language Model (XLM) 是 Facebook 提出的预训练模型,旨在支持多语言NLP 任务。它采用了与 BERT 类似的多层双向 Transformer 编码器来获得语言表示。
这些预训练模型都是深度学习领域中的研究热点,它们在各种自然语言处理任务中都取得了很好的效果。同时,也有其他的预训练模型不属于 Transformer 类型的,如 ELMo、ULMFit 等,它们采用不同的网络结构和训练方式,也可以应用于各种 NLP 任务中。
其实说白了,这些模型都是一些大型企业基于他们的研发力量、资金,训练好的模型并开源出来。
2、GPT2-ML 开源中文模型本地搭建
2.1 开发环境准备
开发工具:PyCharm 2020.2.1 x64
使用虚拟环境搭建:Python3.7、bert4keras不低于0.6.0,这里直接安装最新版本了。
我本机虚拟环境的配置效果:
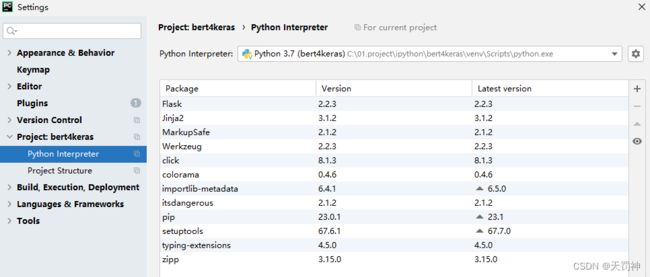
2.2 下载代码
bert4keras 下载到本地。
2.3 下载模型
两种方式:
百度网盘:
链接: https://pan.baidu.com/s/1OXBd16o82SpIzu57kwA8Mg 提取码: q79r
Google Drive,从训练模型的源码进入:
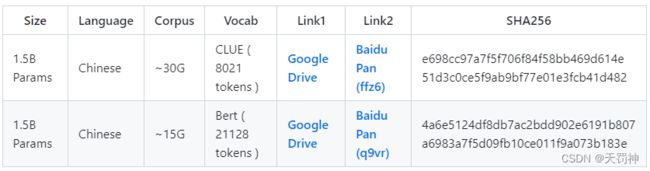
本文下载的百度网盘的模型:
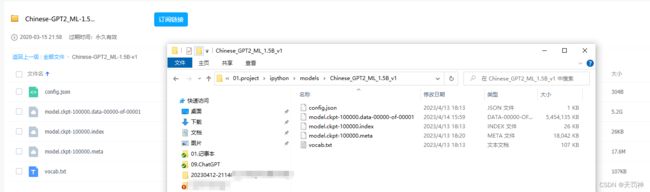
2.4 加载模型
导入项目后,继续以下操作:
1)先安装bert4keras
- 确认你已经安装了Python3和pip包管理器。
- 打开终端或命令行窗口,并运行以下命令来安装bert4keras:
pip install bert4keras -i https://mirrors.aliyun.com/pypi/simple/
3.安装完成后,可以使用以下命令检查版本:
import bert4keras
print(bert4keras.__version__)
如果输出了版本号,则表示成功安装了bert4keras。
安装过程示例:
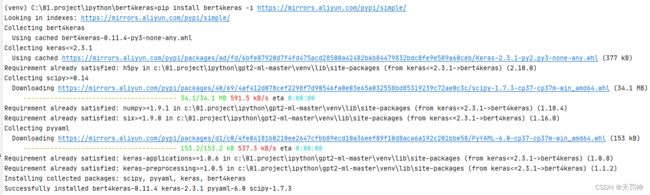
2)下载训练模型的代码,再补全下插件
训练模型的源码地址,运行项目内requirements-tpu.txt、requirements-gpu.txt的安装环境。
pip install -r requirements-tpu.txt -i https://mirrors.aliyun.com/pypi/simple/
pip install -r requirements-gpu.txt -i https://mirrors.aliyun.com/pypi/simple/

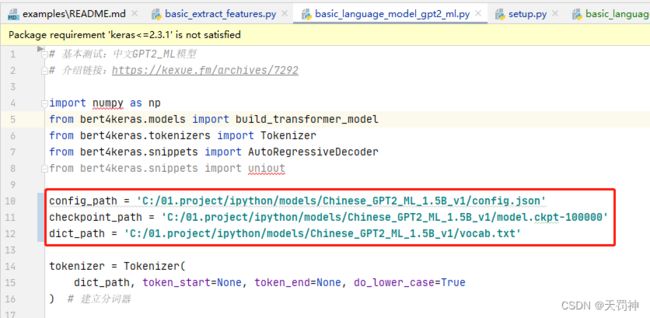
3)修改代码模型地址
basic_language_model_gpt2_ml.py
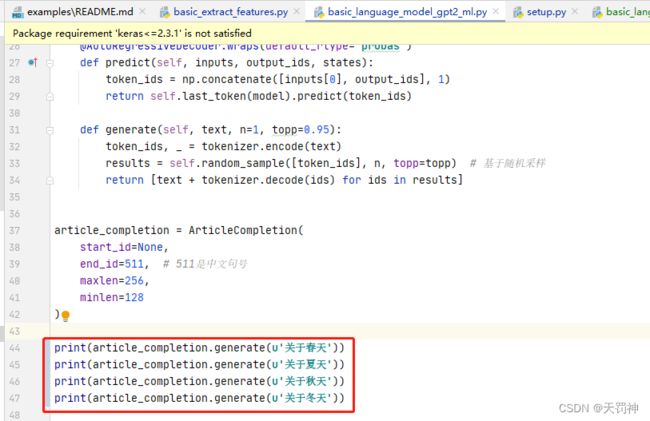
4)运行模型查看测试效果
修改文件basic_language_model_gpt2_ml.py
运行:py examples/basic_language_model_gpt2_ml.py
接下来就漫长的等待,大概半小时左右,将会输出你需要的信息。
如果运行过程中报错,比如缺少tensorflow插件,那么再安装下这个插件即可。
pip install tensorflow==1.15.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
查看已安装的 TensorFlow 版本:
pip list | grep tensorflow
pip freeze | grep tensorflow
2.5 测试效果
[‘关于春天到了,你有没有梦见各种各样的花开?你有没有见识过超美的花朵在前面出没?你有没有想象过春风里开得最美的花?春天到了,你有没有梦见各种各样的花开?你有没有想象过傍晚的花海中有着最美的花?你有没有想象过春天的阳光那么灿烂,粉色的桃花开得很妖艳!这一切的一切,只因为你看见了一朵朵如洁如玉的花。’]
[‘关于夏天到了,必然有很多性感美腻的凉鞋而且,爱美的女孩儿终于有个好选择了,在微博、微信、各大应用市场就可以找到众多美腻的凉鞋,不仅漂亮而且平价,大牌为什么是这么流行?在沙龙里也常能看到很多潮人穿着各种各样的凉鞋,看着就想买,一双好的凉鞋穿两三天,像穿个拖鞋一样!是什么成就了这一高端的品牌?和所有企业都一样,形
象企业的不少款式都和其自身品牌有关,看着就已经很眼熟。’]
[‘关于秋天的优衣库深深喜欢这款连帽上衣无袖连帽棒球服,棒球衫面料略带纯色还有里面是印花清新可人!半高领设计自然又耐看,下摆的大口袋和牛仔裤颜色很相配,半明度的色彩给秋天再添丝丝靓丽,又可以通过大片的纯棉面料体现端庄大方的型格,不同于传统套装的是融合的织法,在颜色上没有那么跳跃,显得特别有活力和少女心。’]
[‘关于冬天,每个女生都梦想成为汤唯,百分之百女神。然而别听我扯淡啦,温暖人心是汤唯,撩人心弦是吴彦祖,干净利落是陈冠希。没人不爱暖汤唯,这就是汤唯。汤唯还是《vogue》2016秋冬系列的主编,是时尚圈中少有的大美女。汤唯一直都在坚持个人风格,走的是女生独有的柔美路线,在神坛上无人可及。’]
3、GPU运行
3.1 要检查计算机是否支持 NVIDIA 显卡,您可以执行以下步骤
在 Windows 操作系统上,右键单击桌面并选择“NVIDIA 控制面板”选项,如果出现该选项,则表示您的计算机已安装 NVIDIA 显卡。
在 Linux 和 macOS 操作系统上,打开终端并输入以下命令:
lspci | grep -i nvidia
如果输出包含 NVIDIA 显卡相关信息,则表示您的计算机已安装 NVIDIA 显卡。
或者,您也可以执行以下命令以获取有关系统显卡的详细信息:
nvidia-smi
请注意,这些命令仅适用于已正确安装了 NVIDIA 显卡驱动程序的计算机。如果您的计算机没有安装 NVIDIA 显卡驱动程序,则这些命令将不起作用。
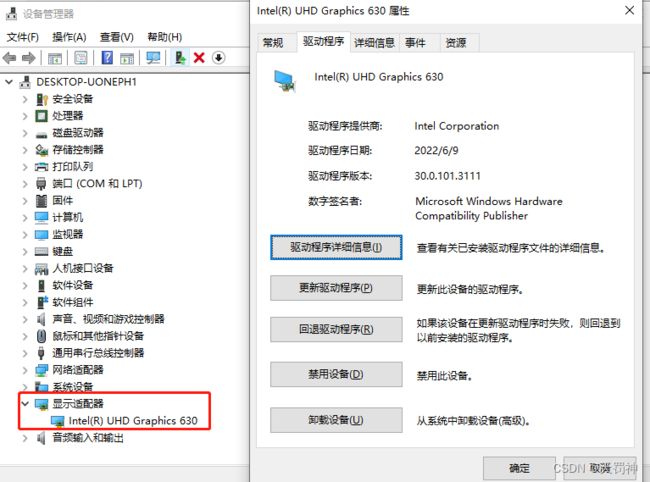
3.2 集成显卡,不支持
如果你的电脑是集成显卡,那么就不要操心了,GPU模式跑不了,这个程序可能需要使用 NVIDIA GPU 或相关的 CUDA 工具包进行 GPU 加速运算,而集成显卡无法提供足够的性能。因此,如果您尝试在只有集成显卡的计算机上运行该程序,并且提示未安装 NVIDIA GPU 或相关的 CUDA 工具包,则表示您的计算机无法满足该程序的 GPU 运行要求。如果您想在计算机上使用 GPU 运行该程序,您需要考虑购买一张适合深度学习的 NVIDIA 显卡并安装相关的驱动程序和 CUDA 工具包。或者,您也可以选择使用云服务提供商提供的云 GPU 实例来运行该程序。
3.3 独立显卡,支持
要安装 NVIDIA GPU 或相关的 CUDA 工具包,您需要执行以下步骤:
- 检查您的计算机是否支持 NVIDIA 显卡,并且显卡驱动程序已正确安装。您可以从 NVIDIA 官网下载显卡驱动程序。
- 检查您的计算机是否支持 CUDA 并且 CUDA 工具包已正确安装。您可以从 NVIDIA 开发者官网下载适用于您的操作系统和显卡类型的 CUDA 工具包。
- 还需要安装 cuDNN 库,它是一个用于深度学习的加速库,可与 CUDA 一起使用。您可以从 NVIDIA 开发者官网下载并安装适用于您的 CUDA 版本的 cuDNN 库。
请注意,安装 NVIDIA GPU、驱动程序、CUDA 工具包和 cuDNN 库可能会相当复杂,因此请务必按照 NVIDIA 的官方文档和说明进行操作。
NVIDIA 显卡驱动安装
可以在 NVIDIA 官网的“驱动程序下载”页面上下载显卡驱动程序:
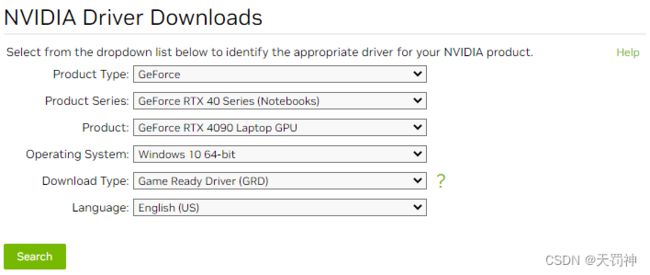
在该页面上,您可以选择您的显卡系列和型号、操作系统以及语言,然后单击“搜索”按钮。随后,您将看到可用于您的计算机的最新显卡驱动程序列表。请仔细查看并选择适合您的操作系统和硬件的驱动程序版本,并按照提示进行下载和安装。
CUDA 工具包安装
- 在 NVIDIA 开发者官网的 CUDA 下载页面(https://developer.nvidia.com/cuda-downloads)上选择适合您的操作系统和显卡型号的 CUDA 版本,并单击“下载”按钮。请注意,不同版本的 CUDA 对应不同的操作系统和显卡型号,因此请务必根据您的计算机配置选择正确的版本。
- 下载完成后,运行 CUDA 安装程序,并按照向导指示进行安装。在安装过程中,您需要接受许可协议、选择安装选项并等待一段时间。
- 完成安装后,您需要配置环境变量和路径,以便您的计算机可以正确找到 CUDA 库和工具。这些设置可能因操作系统而异,请参考 NVIDIA 的官方文档进行配置。
- 验证 CUDA 是否已成功安装。您可以打开终端或命令提示符窗口,并输入以下命令:
nvcc -V
如果输出显示了 CUDA 版本信息,则表示 CUDA 工具包已成功安装。
请注意,安装 CUDA 工具包可能需要一定的技术知识和经验。如果您遇到困难或问题,建议参考 NVIDIA 的官方文档和社区支持,在线查阅相关资源并寻求帮助。
cuDNN 库安装
- 访问 NVIDIA 开发者官网的 cuDNN 下载页面:https://developer.nvidia.com/cudnn
- 选择适合您的操作系统和 CUDA 版本的 cuDNN 库文件,并单击“下载”按钮。请注意,不同版本的 cuDNN 应与您计算机上已安装的 CUDA 版本兼容。
- 在下载页面上,您需要登录或注册 NVIDIA 开发者账户。如果您还没有账户,请根据提示进行注册。
- 将下载的 cuDNN 压缩文件解压到某个目录中。请将该目录添加到您的环境变量和路径中,以便您的计算机可以正确找到 cuDNN 库和头文件。这些设置可能因操作系统而异,请参考 NVIDIA 的官方文档进行配置。
- 验证 cuDNN 是否已成功安装。您可以打开终端或命令提示符窗口,并输入以下命令:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
如果输出显示了 cuDNN 版本信息,则表示 cuDNN 库已成功安装。
请注意,安装 cuDNN 库可能需要一定的技术知识和经验。如果您遇到困难或问题,建议参考 NVIDIA 的官方文档和社区支持,在线查阅相关资源并寻求帮助。