状态编程(状态持久化和状态后端)
目录
状态编程
状态持久化和状态后端
1.检查点(Checkpoint)
2.状态后端(State Backends)
2.1. 状态后端的分类
2.2. 如何选择正确的状态后端
2.3. 状态后端的配置
状态编程
状态持久化和状态后端
在 Flink 的状态管理机制中,对状态进行持久化(persistence)保存是一个重要的功能,它允许系统在发生故障后进行重启恢复。为了实现这一功能,Flink 采用了一种特殊的机制来对分布式状态进行“快照”保存。
Flink 将当前所有分布式状态的快照保存到一个称为“检查点”(checkpoint)或“保存点”(savepoint)的外部存储系统中。这种机制确保了即使在系统发生故障或其他异常情况下,状态数据也不会丢失,并且可以在故障恢复后从最近的检查点或保存点恢复。
检查点和保存点是 Flink 状态管理中的重要概念。它们是系统状态的瞬时副本,用于在故障发生时提供数据恢复的机制。通过定期创建和保存检查点或保存点,Flink 可以在故障发生后重新构建系统的状态,并继续处理数据流。
为了实现检查点和保存点的持久化,Flink 使用分布式文件系统作为存储介质。分布式文件系统允许多个节点同时访问和写入数据,提供了高可用性和可扩展性。通过将状态数据写入分布式文件系统,Flink 可以确保在多个节点之间共享和持久化状态数据,从而在故障发生时能够快速恢复系统状态。
通过结合分布式文件系统和检查点或保存点的机制,Flink 提供了可靠的状态管理功能,能够在系统发生故障后快速恢复并继续处理数据流。这种机制对于保证流处理系统的可靠性和稳定性至关重要,特别是在处理大规模数据流的应用场景中。
1.检查点(Checkpoint)
在有状态流应用中,检查点(checkpoint)是一个非常重要的概念,它实际上是所有任务的状态在某个时间点的快照(即一份拷贝)。简单来说,检查点就像是一次“存盘”,确保我们不会丢失之前处理数据的进度。
在流应用程序运行时,Flink 会定期创建检查点,并记录每个算子的 ID 和状态。如果发生故障,Flink 会使用最近一次成功保存的检查点来恢复应用的状态,重新启动处理流程,就像“读档”一样。这样,即使在发生故障后,流处理也能够从上一次检查点的状态继续处理数据,确保数据的完整性和一致性。
然而,如果检查点保存之后又处理了一些数据,然后发生了故障,那么重启恢复状态之后这些数据带来的状态改变可能会丢失。为了确保最终处理结果正确,我们需要让源(Source)算子重新读取这些数据,再次处理一遍。这就需要流的数据源具有“数据重放”的能力。一个典型的例子就是 Kafka,我们可以通过保存消费数据的偏移量、故障重启后重新提交来实现数据的重放。
此外,Flink 还提供了“保存点”(savepoint)的功能。保存点和检查点在原理和形式上完全一样,也是状态持久化保存的一个快照。但是,与检查点不同的是,保存点是自定义的镜像保存,所以不会由 Flink 自动创建,而需要用户手动触发。这在有计划地停止、重启应用时非常有用。通过使用保存点,用户可以灵活地控制应用的启动和停止,并在需要时进行状态恢复。
需要注意的是,默认情况下,检查点是禁用的,需要在代码中手动开启。通过直接调用执行环境的 enableCheckpointing() 方法,就可以开启检查点功能。此外,关于检查点的详细配置,可以参考第 10 章的内容进行深入了解。
总之,检查点和保存点是 Flink 流处理中非常重要的功能,它们提供了数据可靠性和一致性的保障。通过定期创建检查点和保存点、使用数据重放机制以及自定义镜像保存等手段,Flink 确保了流处理在故障发生时能够快速恢复并继续处理数据流。这些功能对于构建健壮、可靠的流处理应用至关重要。
2.状态后端(State Backends)
检查点的保存确实离不开 JobManager、TaskManager 以及外部存储系统的协调工作。在应用进行检查点保存时,整个过程是分布式的,并需要各个组件之间的紧密配合。
首先,JobManager 会向所有 TaskManager 发出触发检查点的命令。TaskManager 收到命令后,会负责将当前任务的所有状态进行快照保存,并将这些状态持久化到远程的存储介质中。完成快照保存后,TaskManager 会向 JobManager 返回确认信息,表示检查点保存完成。
在整个过程中,JobManager 会持续监听来自 TaskManager 的确认信息。当 JobManager 收到所有 TaskManager 的返回信息后,就可以确认当前检查点成功保存。这个过程确保了检查点的完整性和可靠性,为后续的状态恢复提供了保障。
为了协调这一系列工作,需要一个“专职人员”来负责管理和协调各个组件之间的通信和操作。这个“专职人员”可以是一个独立的协调服务,也可以是 Flink 框架内部的一个组件,负责发送命令、收集确认信息以及管理检查点的生命周期。
通过这样的分布式协调机制,Flink 流处理应用能够确保状态数据的可靠性和一致性,即使在发生故障时也能够快速恢复并继续处理数据流。这对于构建健壮、可扩展和可靠的流处理应用至关重要。
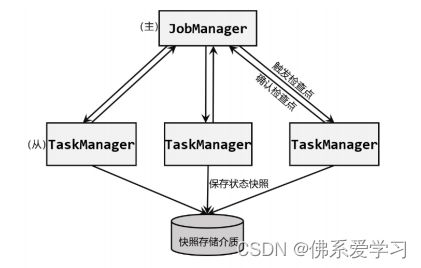
检查点的保存确实离不开 JobManager、TaskManager 以及外部存储系统的协调工作。在应用进行检查点保存时,整个过程是分布式的,并需要各个组件之间的紧密配合。
首先,JobManager 会向所有 TaskManager 发出触发检查点的命令。TaskManager 收到命令后,会负责将当前任务的所有状态进行快照保存,并将这些状态持久化到远程的存储介质中。完成快照保存后,TaskManager 会向 JobManager 返回确认信息,表示检查点保存完成。
在整个过程中,JobManager 会持续监听来自 TaskManager 的确认信息。当 JobManager 收到所有 TaskManager 的返回信息后,就可以确认当前检查点成功保存。这个过程确保了检查点的完整性和可靠性,为后续的状态恢复提供了保障。
为了协调这一系列工作,需要一个“专职人员”来负责管理和协调各个组件之间的通信和操作。这个“专职人员”可以是一个独立的协调服务,也可以是 Flink 框架内部的一个组件,负责发送命令、收集确认信息以及管理检查点的生命周期。
通过这样的分布式协调机制,Flink 流处理应用能够确保状态数据的可靠性和一致性,即使在发生故障时也能够快速恢复并继续处理数据流。这对于构建健壮、可扩展和可靠的流处理应用至关重要。
2.1. 状态后端的分类
状态后端是一个重要的组件,负责在Flink中管理状态的存储、访问和持久化。根据其工作方式和特点,可以将状态后端分为两类:哈希表状态后端和内嵌RocksDB状态后端。
哈希表状态后端(HashMapStateBackend):
- 哈希表状态后端将状态数据保存在内存中,提供快速的读写速度,使计算性能达到最佳。
- 它将状态数据以键值对的形式存储在哈希表中,因此也被称为哈希表状态后端。
- 默认情况下,检查点数据保存在持久化的分布式文件系统中,也可以通过配置来指定其他的存储位置。
- 哈希表状态后端适用于具有大状态、长窗口、大键值状态的作业,并且对高可用性设置有效。
内嵌RocksDB状态后端(EmbeddedRocksDBStateBackend):
- RocksDB是一种内嵌的键值存储介质,用于将数据持久化到本地硬盘。
- 当配置EmbeddedRocksDBStateBackend时,处理中的数据将全部存储在RocksDB数据库中,默认存储在TaskManager的本地数据目录里。
- 与哈希表状态后端不同,状态数据主要存储在RocksDB中,需要进行序列化和反序列化操作,因此状态的访问性能相对较差。
- 内嵌RocksDB状态后端支持异步快照,不会阻塞数据处理,并且提供增量式检查点的机制,提高保存效率。
- 在状态非常大、窗口非常长、键/值状态很大的应用场景中,内嵌RocksDB状态后端是一个好的选择,并且对高可用性设置同样有效。
综上所述,Flink中的状态后端提供了灵活的状态管理机制,可以根据应用的需求选择适合的状态后端。哈希表状态后端提供快速的读写性能,适用于计算密集型作业;而内嵌RocksDB状态后端则适合于需要持久化存储大量状态的场景,支持异步快照和增量式检查点。
2.2. 如何选择正确的状态后端
在选择状态后端时,需要根据业务需求在处理性能和应用的扩展性之间进行权衡。
HashMapStateBackend将状态数据保存在内存中,提供快速的读写速度,使计算性能达到最佳。然而,状态的大小受到可用内存的限制,如果应用的状态随着时间不断增长,可能会耗尽内存资源。
相比之下,RocksDBStateBackend将状态数据持久化到本地硬盘,可以根据可用磁盘空间进行扩展。它还支持增量检查点,非常适合存储超级海量状态。然而,由于每个状态的读写都需要进行序列化和反序列化,并且可能需要直接从磁盘读取数据,这会导致性能的降低,平均读写性能要比HashMapStateBackend慢一个数量级。
因此,选择哪种状态后端取决于具体的应用需求。如果需要处理大规模数据并要求高性能计算,HashMapStateBackend是一个更好的选择。如果应用的状态数据非常大且需要持久化存储,或者需要支持增量检查点,那么RocksDBStateBackend可能更适合。实际应用中需要在处理性能和应用的扩展性之间进行权衡和取舍。
2.3. 状态后端的配置
在Flink中,默认的状态后端配置是在集群的配置文件flink-conf.yaml中指定的。配置的键名称为state.backend。这个默认配置适用于集群上运行的所有作业。通过更改这个配置的值,可以改变默认的状态后端。
除了在集群级别进行配置外,我们还可以在代码中为单个作业单独配置状态后端。这种配置方式会覆盖掉集群配置文件的默认值。通过使用StreamExecutionEnvironment或ExecutionEnvironment的setStateBackend()方法,可以为作业指定特定的状态后端。