FlinkCdc--Debezium实现Kafka实时监控mysql binlog日志
不管是什么大数据组件大部分都分单机和集群模式,这次我配置的是kafka集群监控mysql binlog日志
一.Zookeeper和Kafka集群部署
我的服务器是三台节点 aliyun-bigdata-01 aliyun-bigdata-02 aliyun-bigdata-03
1.第一步实现kafka集群部署和zookeeper集群部署先启动zookeeper再启动kafka,涉及的相关组件如下图所示,去网盘下载
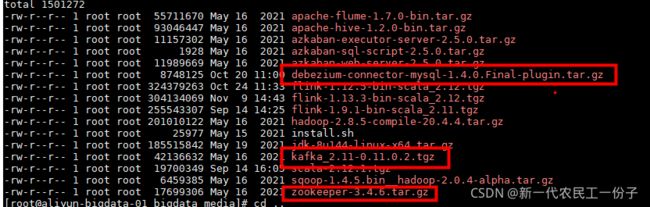
debezium-connector-mysql-1.4.0.Final-plugin.tar.gz
kafka_2.11-0.11.0.2.tgz
zookeeper-3.4.6.tar.gz
链接:https://pan.baidu.com/s/1WZ42cwp6iacBFnCw7Lh1mA
提取码:nb01
--------------------------------------------------------------------------------------------------
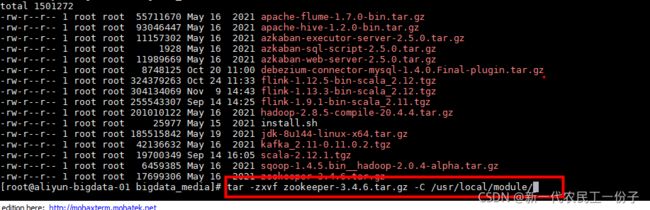
2.下一步先配置Zookeeper和Kafka集群,下载好的Zookeeper,KafkaJar包上传服务器解压
解压命令
-
tar
-zxvf zookeeper
-3.4
.6.tar.gz
-C
/usr
/
local
/
module
/
-
-
tar
-zxvf kafka_2
.11
-0.11
.0
.2.tgz
-C
/usr
/
local
/
module
/
相关的linux解压命令可以自己去了解
解压后创建个软连接或者直接修改名称
ln -s 解压后的zookeeper zookeeper 起个别名
ln -s 解压后的kafka kafka 起个别名

我这里直接修改zookeeper文件夹名称
mv 解压后的zookeeper zookeeper 起个别名
mv 解压后的kafka kafka 起个别名


之后分发到后两台节点 分发命令
-
scp -r zookeeper root
@aliyun-bigdata-
02
:/usr/local/module/
-
-
scp -r zookeeper root
@aliyun-bigdata-
03
:/usr/local/module/
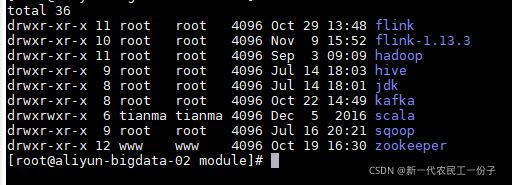

可以看到,zookeeper和kafka都已经分发到后两台节点了
3.下一步去配置组件的环境变量 vim /etc/profile

export 变量名称/ZK_HOME=/usr/local/module/zookeeper 解压后修改后的zookeeper文件夹
export 变量名称/KAFKA_HOME=/usr/local/module/kafka 解压后修改后的kafka文件夹
export PATH=$ZK_HOME/bin:$KAFKA_HOME/bin:$PATH 全局变量,可以在某个目录下直接运行组件启动命令
配置完成后分发后两台节点
-
scp -r /etc/profile root
@aliyun-bigdata-
02
:/etc/
-
-
scp -r /etc/profile root
@aliyun-bigdata-
03
:/etc/
可以查看一下后两台 /etc/profile文件里面是否跟第一台节点内容一样,如果一样还需要执行刷新环境,才生效 source /etc/profile
不管是什么组件都是一样的步骤进行部署,先解压再配置环境变量,刷新环境变量生效
4.下一步进行zookeeper组件集群配置
cd 进去 zookeeper/conf 目录里

原本是没有zoo.cfg文件的,需要把zoo_sample.cfg再copy一个zoo.cfg新文件
命令 cp zoo_sample.cfg zoo.cfg ,copy后编辑 vim zoo.cfg

重要的是绿框里面的配置参数
server.1=节点1的ip地址或主机名:2888:3888
server.2=节点2的ip地址或主机名:2888:3888
server.3=节点3的ip地址或主机名:2888:3888 确保2888和3888端口没有其他进程占用
查看是否被占用 lsof -i:端口号
配置完成后,shift+zz两下退出,是保存退出
然后分发zoo.cfg文件到后两台
-
scp -r zoo.cfg root
@aliyun-bigdata-
02
:/usr/local/module/zookeeper/conf/
-
-
scp -r zoo.cfg root
@aliyun-bigdata-
03
:/usr/local/module/zookeeper/conf/
检测看看三台节点的zoo.cfg是否都一致配置,然后每台节点直接启动zookeeper

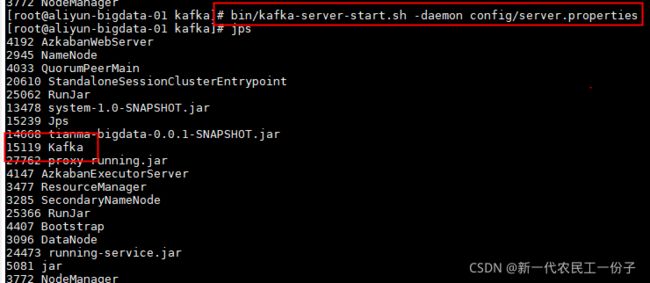
之前说了环境变量配置了全局变量直接启动命令,启动后jps看一下是否有QuorumPeerMain进程
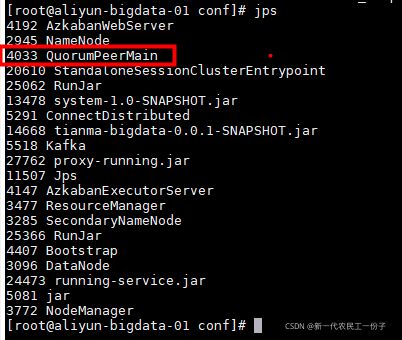
截止到这里集群zookeeper配置完成,zookeeper还是去多了解一下它的原理
5.下一步进行kafka组件集群配置
cd kafka/config 进入配置文件目录
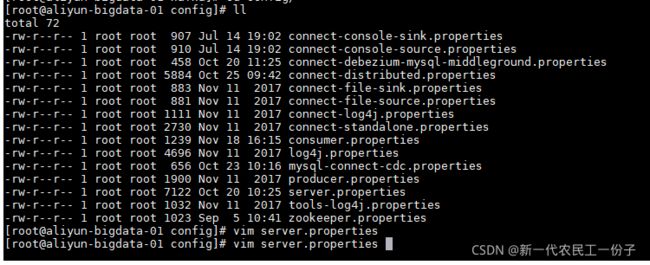
编辑 vim server.properties


kafka集群配置 重要的也就是这几个配置,分发后两台节点,监听配置分发后要改成当前节点ip
之后在kafka当前目录下启动命令
bin/kafka-server-start.sh -daemon config/server.properties -daemon 后台启动参数
 是否是集群模式,可以在第一节点去创建topic,在后两台是否能查看在第一节点创建的topic,
是否是集群模式,可以在第一节点去创建topic,在后两台是否能查看在第一节点创建的topic,
创建topic命令 bin/kafka-topics.sh --zookeeper 01节点:2181,02节点:2181,03节点:2181 --create --partitions 2 --replication-factor 1 --topic test 两个分区,一个备份
查看topic命令 bin/kafka-topics.sh --list --zookeeper 01节点:2181,02节点:2181,03节点:2181
如果可以看见那就是kafka集群配置成功,因为kafka元数据在zookeeper里面存储,之所以三台直接因为zookeeper集群的原因才会通,这就是zookeeper的作用
截止到这里进程在百分之50,下一步就要使用kafka实时监控mysql binlog日志
二.配置Debezium
1.先修改mysql binlog日志开启 vim /etc/my.cnf

log-bin=mysql-bin # 指定binlog日志存储位置
binlog_format=ROW # 这里一定是row格式
expire-logs-days = 10 # 日志保留时间
max-binlog-size = 500M # 日志滚动大小
server-id=15 我这里是15,你们默认是1
退出保存,重启mysql,systemctl restart mysqld,查看是否开启日志show variables like 'log_bin';

2.安装解压Debezium

解压到kafka/plugins目录里,解压后分发到后两台节点

进去 cd kafka/config目录里 编译 vim connect-distributed.properties,我们走的是集群模式
connect-distributed.properties是基于集群模式,connect-standalone.properties是单机模式

 这里面默认端口是8083,确保8083没有被占用,要不然启动会报错,404,500之类的信息
这里面默认端口是8083,确保8083没有被占用,要不然启动会报错,404,500之类的信息
如果要指定其他端口 #rest.host.name=主机名或ip地址 #rest.port=8089
配置好了保存退出,配置文件分发后两台节点,下一步就开始启动命令,跟启动kafka命令一样,只是启动sh脚本不一样,-daemon后台启动命令,config/指定刚才配置的connect-distributed.properties,三台节点都需要启动
启动命令:
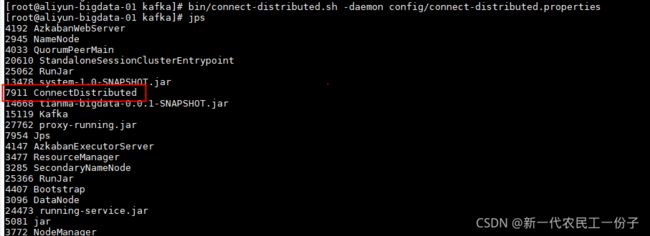
bin/connect-distributed.sh -daemon config/connect-distributed.properties
查看进程 jps ConnectDistributed进程
查看是否真正启动成功 curl -H "Accept:application/json" 主机名:8083/connectors/
三台节点都去尝试看看,如果查询出来是[] 这样的,Debezium就配置成功了
3.配置连接mysql binlog(连接数据库配置信息)
vim mysql-connect-cdc.json 创建一个新的json文件
-
{
-
"name"
:
"tmdonwms"
,
-
"config"
:
{
-
"connector.class"
:
"io.debezium.connector.mysql.MySqlConnector"
,
-
"database.hostname"
:
"192.168.1.1"
,
-
"database.port"
:
"3306"
,
-
"database.user"
:
"root"
,
-
"database.password"
:
"123456"
,
-
"database.server.id"
:
"15"
,
-
"database.server.name"
:
"tmdonwmsmysql"
,
-
"table.include.list"
:
"bigdata_realtime.r_shop_sale_info"
,
-
"database.history.kafka.bootstrap.servers"
:
"192.168.1.148:9092,192.168.1.151:9092,192.168.1.150:9092"
,
-
"database.history.kafka.topic"
:
"dwmson_kafka"
,
-
"include.schema.change"
:
"true"
,
-
"decimal.handling.mode"
:
"double"
-
}
-
}
name:是连接名,config{
connector.class是连接驱动类 debezium-connector-mysql-1.4.0.Final.jar这就是驱动jar包
database.hostname:mysql连接IP地址
database.port 端口
database.user 用户名
database.password 密码
database.server.id 之前在my.cnf里面设置的serverid 默认是1
database.server.name 数据库服务名称
table.include.list 指定监控哪个库里面的表
database.history.kafka.bootstrap.servers kafka集群连接信息
database.history.kafka.topic kafka历史日志topic
include.schema.change 这里开启的意思是,数据库有一条数据发生更改删除操作了,会重新监听,重新生成新的日志json数据进去topic里面
decimal.handling.mode 这里是decimal类型转换成double,flinksql映射kafka成一张表的时候ddl 指定decima类型会报错,之所以必须用double代替
}
配置完成后退出保存,下一步就实现连接:连接命令:curl -s -H "Content-Type: application/json" -X POST -d @mysql-connect-cdc.json http://主节点ip:8083/connectors/

启动后再查一下是否有刚才创建的连接,再查一下它的状态,sataus:running是正常的

然后再查看kafka topic是否被创建.

然后去消费刚才监控的那种表,去数据库插入一条数据会不会被消费到,如果有数据进入kafka,就创建成功,到此kafka实时监控mysql binlog日志结束
之后会更新flinksql 映射kafkatopic成表,实时消费kafka数据实时统计数据落库
say goodbay good lucky