数据质量和治理论
数据质量和数据治理,这个概念很大不是一两个人可以处理的问题,但是又不得不做,往往需要整个团队或者跨团队协作尽量去处理好这个事情
以下是一些方法论
数据质量
数据质量会带来什么问题:
- 报表数据出错,无人发现
- 数据出现问题,导致推荐等使用数据不准确
- 发现数据问题,但是数据问题源头排查耗时长,导致数据长时间不可用
哪些情况会有数据质量问题
1. 业务源系统变更
- 数据同步或清洗时业务源表结构变化,导致失败
- 同步或清洗时业务源表源表数据业务变化,比如枚举类型修改等,导致数据不准确
- 加服务器或者迁移服务器,但是忘了迁移日志传输任务
- 数据格式异常,埋点有不符合格式的数据,约定的 IP 格式是 166.111.4.129,结果出现了 166.111.4.null等
2. 数据开发任务变更
- 任务上线未测试,导致任务失败
- 依赖关系配置错误
- 没有对错误的数据格式清洗,导致的异常等开发原因
3. 资源或者集群基建等不稳定
- 资源不够导致任务延时或失败
- 比如元数据中心打爆了,版本升级导致任务失败
怎么保证数据质量,核心是早发现,早恢复
1. 通过稽核校验任务
在数据产出任务运行结束后,启动稽核校验任务对数据结果进行扫描计算
-
完整性规则。主要目的是确保数据记录是完整的,不丢失。常见的稽核规则有表数据量的绝对值监控和波动率的监控(比如表波动超过 20%,就认为是异常)。还有主键唯一性的监控,它是判断数据是否有重复记录的监控规则,比较基础。除了表级别的监控,还有字段级别的监控(比如字段为 0、为 NULL 的记录)。
-
一致性规则。主要解决相关数据在不同模型中一致性的问题。商品购买率是通过商品购买用户数除以商品访问 uv 计算而来的,如果在不同的模型中,商品购买用户数是 1W、商品访问 uv10W,商品购买率 20%,那这三个指标就存在不一致。
-
准确性规则。主要解决数据记录正确性的问题。常见的稽核规则有,一个商品只能归属在一个类目,数据格式是不是正确的 IP 格式,订单的下单日期是还没有发生的日期等等。
2 全链路监控
基于数据血缘关系,建立全链路数据质量监控,可以直观的看到上下游每一个任务的执行情况,快速定位问题源头以及造成的影响
3 自动告警
失败告警,以及部分任务在某一个时间点未完成进行告警,快速发现并解决问题
4. 数仓规范
制定通用规则,数据波动监控,核心表还要特殊对待,比如字段非null,非0,主键检查等
指标规范
主要是为了解决指标混乱现状:
- 相同指标名称,口径定义不同
- 相同口径,指标名称不一样
- 不同限定词,描述相同事实过程的两个指标,相同事实部分口径不一致
- 指标口径描述不清晰或者描述错误
- 指标命名不规范,难于理解
- 指标数据来源和计算逻辑不清晰
如何规范化定义指标
- 面向主题域管理
按照业务线、主题域和业务过程三级目录方式管理指标,主题域跟数仓保持一致即可
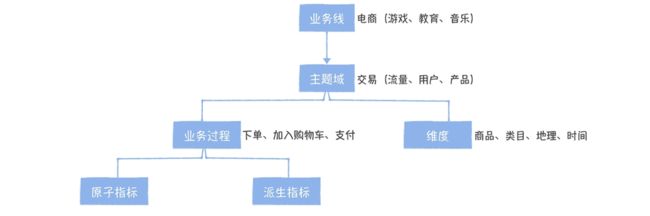
- 拆分原子指标和派生指标
时间:30天 + 维度:商品 + 业务线:是否会员 + 指标:商品购买数量,那么有这样一层关系
30 天内,商品维度的黑卡会员购买用户数和 30 天内商品维度的非会员购买用户数就作为两个派生指标存在,但是他们继承自同一个原子指标

- 统一指标命名规范
做到一看指标名就知道指标是怎么统计的,一般原子指标:动作 + 度量 ,派生指标:时间周期 + 统计粒度 + 修饰词 + 原子指标
- 关联的应用和可分析维度
指标要可以通过不同维度分析,另外指标被哪些应用使用应当有记录可查询,可以有一个全局的指标字典来管理
当然有能力最好还是建立指标平台,统一管理指标
可以分等级管理,因为除了中台的指标,每个部门肯定有自己的派生指标,过多且不统一的指标都放到中台还是有较大开发压力的
- 一级指标:数据中台直接产出,核心指标(提供给公司高层看的)、原子指标以及跨部门的派生指标。
中台负责
- 二级指标:基于中台提供的原子指标,业务部门创建的派生指标。
允许业务方自己创建
元数据中心
元数据划为三类:
- 数据字典,主要是数据的结构信息,比如表名、注释,字段,字段注释和类型,产出任务
- 数据血缘,上下游依赖关系,也就是一个表直接通过哪些表加工而来的,主要用来做表异常对下游影响分析和上游表故障溯源
- 数据特征,主要是数据的属性信息,表的存储空间、访问次数、主题域、数仓分层
元数据中心至关重要,表是否下线,是否有依赖,任务错了怎么判断影响等等都可以发挥很大的作用
数据安全
1 数据备份与恢复
HDFS 的数据备份,和冷备集群
其实,Hadoop 在 3.x 就正式引入了 EC 存储,它是一种基于纠删码实现的数据容错机制,通过将数据进行分块,然后基于一定的算法计算一些冗余的校验块,当其中一部分数据块丢失的时候,可以通过这些冗余的校验块和剩余的数据块,恢复出丢失的数据块
2 垃圾回收箱设计
HDFS 本身提供了垃圾回收站的功能,和电脑的垃圾回收一样,删除的文件在回收站可以恢复,到过期时间才会真的删除,通过在 Core-site.xml 中添加如下配置就可以开启了,默认是关闭状态。
问题:但是只针对hdfs命令才有效,对于hdfs api和hive 的drop语句还是直接删除
对 HDFS 的 Client 进行修改,对 Delete API 通过配置项控制,改成跟 rm 相同的语义。也就是说,把文件移到 trash 目录。对于 Hive 上的 HDFS Client 进行替换,这样可以确保用户通过 drop table 删除表和数据时,数据文件能够正常进入 HDFS trash 目录
新问题:但 HDFS 回收站不宜保留时间过长,因为回收站中的数据还是三副本配置,会占用过多的存储空间
解决方案是,回收站保留 24 小时内的数据。这样解决的是数据还没来得及被同步到冷备集群,误删除的情况。对于一天以上的数据恢复,建议采取基于冷备集群的数据备份来恢复
3 精细化的权限管理
不能谁都可以操作,随便来一个人,直接上去就删数据,我们要加上登录认证,然后看你的权限可以做什么,一般人查询即可
Ranger 提供了细粒度的权限控制(Hive 列级别),基于策略的访问控制机制,支持丰富的组件以及与 Kerberos 认证的良好集成。权限管理的本质,可以抽象成一个模型:“用户 - 资源 - 权限”
4 操作审计机制
知道用户的操作,比如谁误删文件,数据外泄,我们要知道谁操作了这些
5 开发和生产集群物理隔离
有条件的话最好还是吧环境隔离,直接在线上操作是有风险的