【论文解读】V2VNet: Vehicle-to-Vehicle Communication for Joint Perception and Prediction
V2VNet
- 摘要
- 引言
- 方法
-
- Which Information should be Transmitted
- Leveraging Multiple Vehicles
- 实验
- 结论
摘要
在本文中,我们探索了使用车对车(V2V)通信来提高自动驾驶车辆的感知和运动预测性能。通过智能聚合来自附近多辆车辆的信息,我们可以从不同的角度观察同一个场景。这使我们能够透过遮挡物,并在远距离探测到物体,而在远距离观察到的物体非常稀疏或根本不存在。我们还证明了我们发送压缩深度特征图激活的方法在满足通信带宽要求的同时达到了很高的精度。
引言
在本文中,我们考虑了车对车(V2V)通信设置,其中每辆车都可以向附近车辆(半径70米以内)广播和接收信息。注意,基于现有的通信协议,该广播范围是真实的[21]。我们表明,为了在满足现有硬件传输带宽能力的同时达到具有强感知和运动预测性能的最佳折衷,我们应该发送压缩的P&P神经网络的中间表示。因此,我们推导了一种新的P&P模型,称为V2VNet,它利用空间感知图神经网络(GNN)来聚合从附近所有sdv接收的信息,使我们能够智能地组合来自场景中不同时间点和视点的信息
【SDV】self-driving vehicles
方法
在本文中,我们设计了一种新颖的感知和运动预测模型,使自动驾驶汽车能够利用多个sdv可能存在于同一地理区域的事实。在联合感知和预测算法3,5,30,31取得成功之后,我们将方法设计为执行这两项任务的联合架构,并对其进行了增强,以纳入从其他车辆接收到的信息。具体来说,我们希望设计我们的P&P模型来完成以下工作:
给定传感器数据,SDV应该
- (1)处理这些数据,
- (2)广播这些数据,
- (3)结合从附近其他SDV接收到的信息,
- (4)生成所有交通参与者在3D空间中的最终估计位置及其预测的未来轨迹。
V2V设置中出现了两个关键问题:
- (i)每辆车应该广播什么信息来保留所有重要信息,同时最大限度地减少所需的传输带宽?
- (ii)每辆车应如何整合从其他车辆收到的信息,以提高其感知和运动预测输出的准确性?
在本节中,我们将讨论这两个问题。
Which Information should be Transmitted
SDV可以选择广播三种类型的信息:
- (i)原始传感器数据,
- (ii)其P&P系统的中间表示,
- (iii)输出检测和运动预测轨迹。
在本文中,我们认为发送P&P网络的中间表示实现了两全其美。首先,每辆车都处理自己的传感器数据,并计算其中间特征表示。这被压缩并广播到附近的SDV。然后,使用从其他SDV接收的消息来更新每个SDV的中间表示。这通过附加的网络层被进一步处理,以产生最终的感知和运动预测输出。这种方法有两个优点:
- (1)深度网络中的中间表示可以很容易地压缩,同时为下游任务保留重要信息。
- (2) 它的计算开销很低,因为来自其他车辆的传感器数据已经过预处理。
Leveraging Multiple Vehicles
V2VNet有三个主要阶段:
- (1)卷积网络块,其处理原始传感器数据并创建可压缩的中间表示;
- (2)跨车辆聚合阶段,其将从多个车辆接收的信息与车辆的内部状态(根据其自身的传感器数据计算)聚合,以计算更新的中间表示,
- (3)计算最终P&P输出的输出网络。
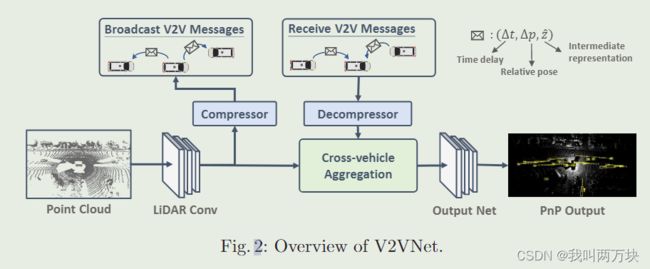
- LiDAR Conv :使用的是PIXOR
- conpressor:采用Balĺe等人的变分图像压缩算法[2]来压缩我们的中间表示
- Cross-vechicle Aggregation:GNN和ConvGRU
【2】Ball ́e, J., Minnen, D., Singh, S., Hwang, S.J., Johnston, N.: Variational image compression with a scale hyperprior. In: International Conference on Learning Representations (2018)
【变分图像压缩算法】变分图像压缩算法是一种用于图像压缩的方法,它基于变分自编码器(Variational Autoencoders, VAE)进行图像编码和解码。在这种方法中,图像被编码成一个更低维度的潜在表示,然后通过一个解码器重建为压缩后的图像。这种压缩方法可以在保持图像质量的同时显著降低数据量,从而减少存储和传输的开销。变分图像压缩算法在计算机视觉、自动驾驶和其他领域的应用中具有广泛的潜力。
【变分自编码器】变分自编码器(Variational Autoencoder,VAE)是一种生成模型,结合了自编码器和概率图模型的思想。它通过学习数据的潜在分布来生成新的样本。VAE的输入是原始数据,如图像或文本,它将输入数据编码为低维的潜在空间中的向量表示。这个潜在空间是一个随机变量,其分布通常假设为高斯分布。VAE通过最大化对数似然函数来学习数据的潜在分布,其中包括最大化观测数据的条件概率和最小化潜在变量的先验分布之间的差异。VAE的解码器将潜在变量映射回原始数据空间,并生成新的样本。通过在训练过程中引入随机性,VAE能够生成多样化的样本。因此,VAE不仅可以用于数据的重建和压缩,还可以用于生成新的样本。
我们的聚合模块必须处理这样一个事实,即由于激光雷达传感器的滚动快门和传感器的每辆车的不同触发,不同的SDV位于不同的空间位置,并在不同的时间戳看到参与者。这一点很重要,因为中间特征表示是空间感知的。
为了实现这一目标,每辆车都使用全连接图神经网络(GNN)作为聚合模块,其中GNN中的每个节点都是场景中SDV的状态表示,包括它自己(见图3)。
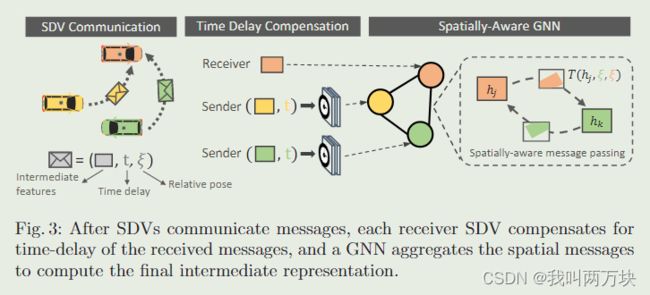
每个SDV保持其自己的局部图,基于该局部图SDV在范围内(即70m)。GNN是一个自然的选择,因为它们处理在V2V设置中出现的动态图拓扑。GNN是为图形结构化数据量身定制的深度学习模型:每个节点都保持一个状态表示,在固定次数的迭代中,在节点之间发送消息,并使用神经网络基于聚合的接收信息更新节点状态。注意,GNN消息与SDV发送/接收的消息不同:GNN计算由SDV本地完成。我们设计我们的GNN来在时间上扭曲和空间上将接收到的消息转换到接收器的坐标系。我们现在描述接收车辆执行的聚合过程,如下伪代码:

- line3:我们首先补偿车辆之间的时间延迟,为图中的每个节点创建初始状态。具体而言,对于每个节点,我们应用卷积神经网络(CNN),该网络以接收到的中间表示(zi)、接收和发送sdv之间的相对6DoF位姿(∆pi)以及相对于接收车辆传感器时间的时间延迟∆ti→k作为输入。注意,对于表示接收车辆的节点,zi直接是它的中间表示。时间延迟计算为每辆车扫描启动时间之间的时间差,基于通用GPS时间。然后,我们采用延迟补偿表示,并与零连接,以增加节点状态的容量,以聚合传播后从其他车辆接收到的信息。
- Line7:接下来我们执行GNN消息传递。关键的观点是,由于其他sdv位于相同的局部区域,节点表示将具有重叠的视图域,如果我们智能地转换表示并在视场重叠的节点之间共享信息,可以增强SDV对场景的理解和产生更好的输出P&P。图3直观地描述了我们的空间聚合模块。我们首先应用相对空间变换ξi→k来扭曲第i个节点的中间状态,从而向第k个节点发送GNN消息。然后,我们使用CNN对两个节点的空间对齐特征图进行联合推理。最终修改后的消息计算如第7行所示,其中T通过双线性插值对特征状态进行空间变换和重采样,Mi→k掩掉视场之间的非重叠区域。请注意,通过这种设计,我们的信息保持了空间意识。
- Line8:接下来,我们通过掩码感知置换不变函数φM在每个节点上聚合接收到的消息,并使用卷积门控循环单元(ConvGRU)(第8行)更新节点状态,其中j∈N (i)是节点i在网络中的相邻节点,φM是均值算子。
- Line11:节点更新中的门控机制可以根据接收SDV的当前信念对累积的接收消息进行信息选择。在最后的迭代之后,多层感知器输出更新的中间表示
【掩码感知置换不变函数】这个是一个用于处理图神经网络(GNN)中节点信息的函数,它具有以下特点:
- 掩码感知(mask-aware):该函数考虑了节点之间的掩码(mask)信息,以便仅在节点视野重叠的区域进行信息聚合。
- 排列不变(permutation-invariant):该函数对于节点顺序的变化是不敏感的,这意味着它可以处理任意排列的节点信息。(其实就是mean、sum、max这些与节点顺序无关的函数,此处使用的是均值算子也就是mean)
【ConvGRU】ConvGRU(Convolutional Gated Recurrent Unit)是一种结合了卷积神经网络(Convolutional Neural Network, CNN)和门控循环单元(Gated Recurrent Unit, GRU)的深度学习模型。ConvGRU主要应用于处理时序数据,如图像序列或视频。在ConvGRU中,输入数据首先通过卷积层进行特征提取,然后通过门控循环单元进行序列建模。这种结构允许模型在时间上捕捉到局部依赖关系,同时利用卷积神经网络的强大表达能力。(用RNN的方式思考一下,也就是把GRU当成神经元,只不过是利用卷积输入数据)
输出:在执行消息传递后,我们应用一组四个类似inception[42]的卷积块来有效地捕获多尺度上下文,这对预测很重要。最后,我们利用特征映射和两个网络分支分别输出检测和运动预测估计。检测输出为(x, y, w, h, θ),表示每个物体的位置、大小和方向。运动预测分支的输出参数化为(xt, yt),它表示物体在未来时间步长t的位置。
【Inception】Inception是一种深度学习网络结构,它主要用于图像分类和目标检测。Inception网络通过使用多尺度的卷积核来提取不同尺度的特征,从而提高模型的性能。
实验
数据集:V2V-Sim
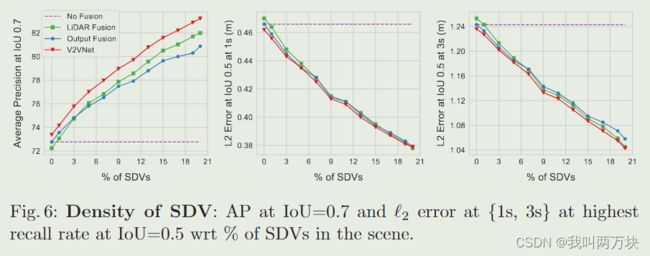

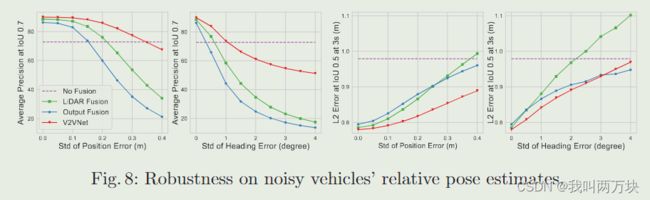
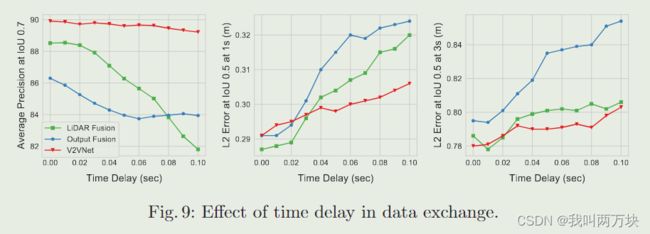

结论
在本文中,我们提出了一种用于感知和预测的V2V方法,该方法传输P&P神经网络的压缩中间表示,在精度提高和带宽要求之间实现了最佳折衷。为了证明我们方法的有效性,我们创建了一个新的V2V-Sim数据集,真实地模拟了sdv无处不在的世界。我们希望我们的发现能够启发未来在V2V感知和运动预测策略方面的工作,以实现更安全的自动驾驶汽车。