MySQL必会四大函数-窗口函数
在了解窗口函数之前,我们必须了解聚合函数。常见的聚合函数,包括 AVG、COUNT、MAX、MIN、SUM 以及 GROUP_CONCAT,常和GROUP BY 函数一起使用。聚合函数的作用就是对一组数据行进行汇总计算,并且返回单个分析结果。
窗口函数和聚合函数类似之处在于它也是对一组数据进行分析;但是,窗口函数不是将一组数据汇总为单个结果;而是针对查询中的每一行数据,基于和它相关的一组数据计算出一个结果。下图演示了聚合函数和窗口函数的区别:
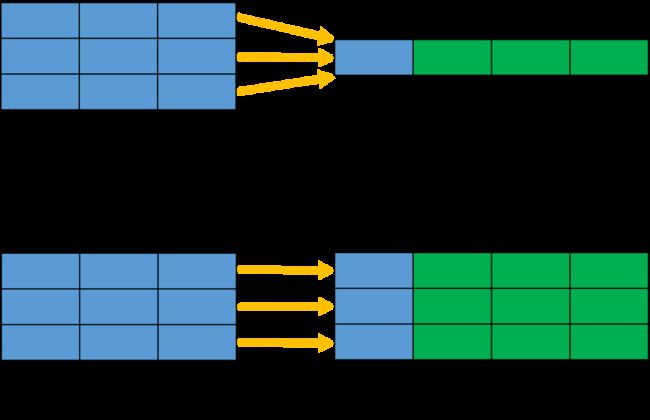
我们可以看到聚合函数都会减少查询返回的行数。
与带有
GROUP BY子句的聚合函数一样,窗口函数也对行的子集进行操作,但它们不会减少查询返回的行数。
接下来以实际的例子来直观感受下窗口函数
表account1: acct 字段为帐号,cus_no 字段为客户号,open_org字段为开户行,status字段为状态,bal为客户在该行的存款余额。

select open_org, sum(bal)
from acount1
group by open_org
select cust_no,open_org,bal, sum(bal) over(partition by open_org)
from acount1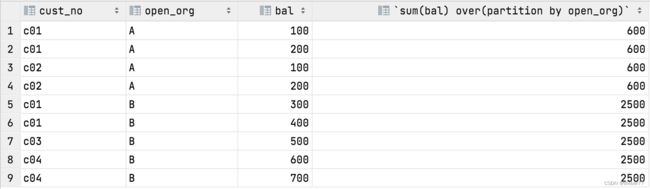
窗口函数的定义
window_function ( expr ) OVER (
PARTITION BY ...
ORDER BY ...
frame_clause
)其中,window_function 是窗口函数的名称;expr 是参数,有些函数不需要参数;
OVER子句包含三个选项:分区(PARTITION BY)、排序(ORDER BY)以及窗口大小(frame_clause)。
分区(PARTITION BY)
PARTITION BY选项用于将数据行拆分成多个分区(组),窗口函数基于每一行数据所在的组进行计算并返回结果,它的作用类似于GROUP BY分组。
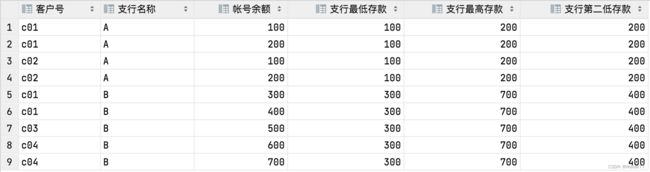
select cust_no as '客户号',open_org as '支行名称',
bal as '帐号余额', sum(bal) over(partition by open_org) as '支行总金额'
from acount1

支行A拥有存款 100+200+100+200 = 600,支行B拥有存款300+400+500+600+700 = 2500。
SQL 标准要求 PARTITION BY 之后只能使用字段名,不过 MySQL 允许指定表达式。另外,我们也可以在 PARTITION BY 之后指定多个分组字段,例如同时按照部门和性别进行分组分析。
排序(ORDER BY)
OVER 子句中的ORDER BY选项用于指定分区内的排序方式,与 ORDER BY 子句的作用类似,通常用于数据的排名分析。以下示例用于计算每个客户帐号在支行内的余额排名
select cust_no as '客户号',open_org as '支行名称',bal as '帐号余额',
rank() over(partition by open_org order by bal desc) as '帐号余额支行内排名'
from acount1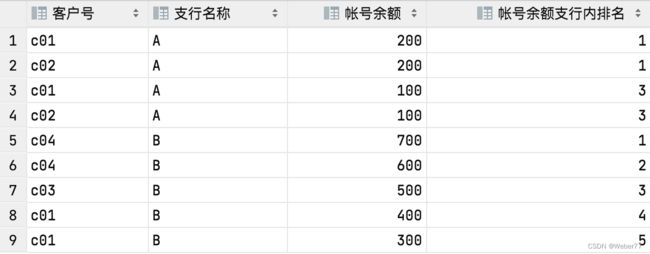
帐号1、客户c01在A支行内存款200 排名1;帐号2、客户c02在A支行内存款200 排名1...
帐号5、客户c04在B支行内存款700 排名1;帐号9、客户c01在B支行内存款100 排名5...
其中,PARTITION BY 选项表示按照部门进行分区;ORDER BY 选项指定在分区内按照月薪从高到低进行排序;RANK 函数用于计算名次,该函数将会在下文中进行介绍。
窗口大小(frame_clause)
frame_clause选项用于在当前分区内指定一个计算窗口,也就是一个与当前行相关的数据子集。指定了窗口之后,分析函数不再基于分区进行计算,而是基于窗口内的数据进行计算。窗口会随着当前处理的数据行而移动,例如:
- 定义一个从分区开始到当前数据行结束的窗口,可以计算截止到每一行的累计总值。
- 定义一个从当前行之前 N 行数据到当前行之后 N 行数据的窗口,可以计算移动平均值。
窗口函数常用参数
{ ROWS | RANGE } frame_start
{ ROWS | RANGE } BETWEEN frame_start AND frame_end其中,ROWS表示以行为单位指定窗口的偏移量,RANGE表示以数值为单位指定窗口的偏移量。frame_start 和 frame_end 分别表示窗口的开始行和结束行,它们的可能取值如下:
CURRENT ROW --对于 ROWS 方式,代表了当前行;对于 RANGE,代表了当前行的所有对等行。
UNBOUNDED PRECEDING --代表了分区中的第一行。
UNBOUNDED FOLLOWING --代表了分区中的最后一行。
expr PRECEDING --对于 ROWS 方式,代表了当前行之前的第 expr 行;对于 RANGE,代表了等于当前行的值减去 expr 的所有行;如果当前行的值为 NULL,代表了当前行的所有对等行。
expr FOLLOWING --对于 ROWS 方式,代表了当前行之后的第 expr 行;对于 RANGE,代表了等于当前行的值加上 expr 的所有行;如果当前行的值为 NULL,代表了当前行的所有对等行。如果只有 frame_start,默认以当前行作为窗口的结束。如果同时指定了两者,frame_start 不能晚于 frame_end,例如 BETWEEN 1 FOLLOWING AND 1 PRECEDING 就是一个无效的窗口。下图可以方便我们理解这些选项的含义

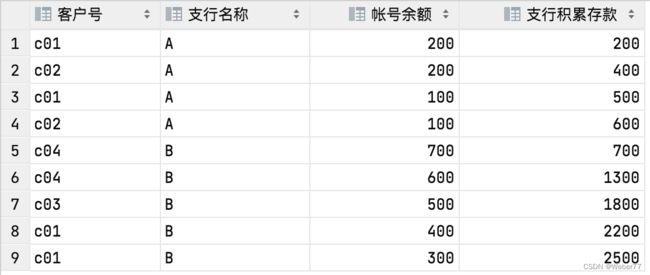
以下示例按照支行统计客户的累计存款值
select cust_no as '客户号',open_org as '支行名称',bal as '帐号余额',
sum(bal) over(partition by open_org order by bal desc rows unbounded preceding) as '支行积累存款'
from acount1
常见的窗口函数
聚合窗口函数
常用的聚合函数,例如 AVG、SUM、COUNT 等,也可以作为窗口函数使用。
这里不多举例,可以看上面的例子
排名窗口函数
排名窗口函数用于对数据进行分组排名。常见的排名窗口函数包括:
- ROW_NUMBER,为分区中的每行数据分配一个序列号,序列号从 1 开始分配。
- RANK,计算每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会产生跳跃。
- DENSE_RANK,计算每行数据在其分区中的名次;即使存在名次相同的数据,后续的排名也是连续的值。
- PERCENT_RANK,以百分比的形式显示每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会产生跳跃。
- CUME_DIST,计算每行数据在其分区内的累积分布,也就是该行数据及其之前的数据的比率;取值范围大于 0 并且小于等于 1。
- NTILE,将分区内的数据分为 N 等份,为每行数据计算其所在的位置。
select cust_no as '客户号',open_org as '支行名称',bal as '帐号余额',
ROW_NUMBER() OVER (PARTITION BY open_org ORDER BY bal DESC) AS "row_number",
RANK() OVER (PARTITION BY open_org ORDER BY bal DESC) AS "rank",
DENSE_RANK() OVER (PARTITION BY open_org ORDER BY bal DESC) AS "dense_rank",
PERCENT_RANK() OVER (PARTITION BY open_org ORDER BY bal DESC) AS "percent_rank"
from acount1;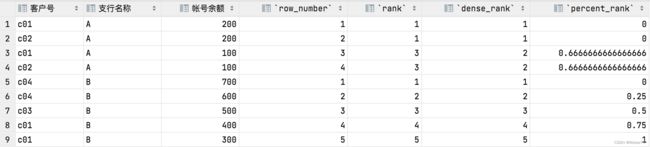
取值窗口函数
取值窗口函数用于返回指定位置上的数据。常见的取值窗口函数包括:
- FIRST_VALUE,返回窗口内第一行的数据。
- LAST_VALUE,返回窗口内最后一行的数据。
- NTH_VALUE,返回窗口内第 N 行的数据。
- LAG,返回分区中当前行之前的第 N 行的数据。
- LEAD,返回分区中当前行之后第 N 行的数据
select cust_no as '客户号',open_org as '支行名称',bal as '帐号余额',
first_value(bal) OVER(partition by open_org) "支行最低存款",
last_value(bal) OVER(partition by open_org) "支行最高存款",
nth_value(bal, 2) OVER(partition by open_org) "支行第二低存款"
from acount1;