Logstash-数据流引擎
Logstash-数据流引擎

作者 | WenasWei
Logstash是具有实时流水线功能的开源数据收集引擎。Logstash可以动态统一来自不同来源的数据,并将数据标准化到您选择的目标位置。清除所有数据并使其民主化,以用于各种高级下游分析和可视化用例。
1.1 Logstash简介
Logstash 是一个数据流引擎:
- 它是用于数据物流的开源流式 ETL(Extract-Transform-Load)引擎
- 在几分钟内建立数据流管道
- 具有水平可扩展及韧性且具有自适应缓冲
- 不可知的数据源
- 具有200多个集成和处理器的插件生态系统
- 使用 Elastic Stack 监视和管理部署
官方介绍:Logstash is an open source data collection engine with real-time pipelining capabilities。简单来说logstash就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
1.2 数据处理
Logstash 是一个功能强大的工具,可与各种部署集成。 它提供了大量插件,可帮助你解析,丰富,转换和缓冲来自各种来源的数据。 如果你的数据需要 Beats 中没有的其他处理,则需要将 Logstash 添加到部署中。
当下最为流行的数据源:
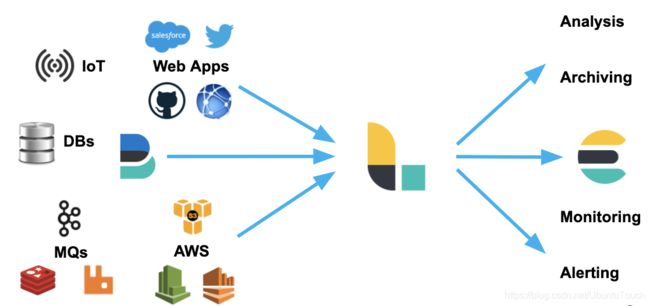
Logstash 可以摄入日志,文件,指标或者网路真实数据。经过 Logstash 的处理,变为可以使用的 Web
Apps 可以消耗的数据,也可以存储于数据中心,或变为其它的流式数据:
- Logstash 可以很方便地和 Beats一起合作,这也是被推荐的方法
- Logstash 也可以和那些著名的云厂商的服务一起合作处理它们的数据
- 它也可以和最为同样的信息消息队列,比如 redis 或 kafka 一起协作
- Logstash 也可以使用 JDBC 来访问 RDMS 数据
- 它也可以和 IoT 设备一起处理它们的数据
- Logstash 不仅仅可以把数据传送到 Elasticsearch,而且它还可以把数据发送至很多其它的目的地,并作为它们的输入源做进一步的处理
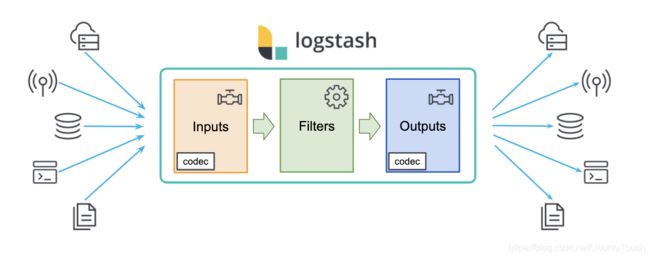
Logstash 包含3个主要部分: 输入(inputs),过滤器(filters)和输出(outputs)

Logstash的事件(logstash将数据流中等每一条数据称之为一个event)处理流水线有三个主要角色完成:inputs –> filters –> outputs:
- inpust:必须,负责产生事件(Inputs generate events),常用:File、syslog、redis、kakfa、beats(如:Filebeats)
- filters:可选,负责数据处理与转换(filters modify them),常用:grok、mutate、drop、clone、geoip
- outpus:必须,负责数据输出(outputs ship them elsewhere),常用:elasticsearch、file、graphite、kakfa、statsd
3.1 环境清单
- 操作系统:Linux #56-Ubuntu SMP Tue Jun 4 22:49:08 UTC 2019 x86_64
- Logstash版本:logstash-6.2.4
- Jdk版本:1.8.0_152
3.2 Linux安装JDK
3.2.1 解压缩并移动到指定目录(约定的目录:/usr/local)
(1)解压缩
tar -zxvf jdk-8u152-linux-x64.tar.gz
(2)创建目录
mkdir -p /usr/local/java
(3)移动安装包
mv jdk1.8.0_152/ /usr/local/java/
(4)设置所有者
chown -R root:root /usr/local/java/
3.2.2 配置环境变量
(1)配置系统环境变量
vi /etc/environment
(2)添加如下语句
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games"
export JAVA_HOME=/usr/local/java/jdk1.8.0_152
export JRE_HOME=/usr/local/java/jdk1.8.0_152/jre
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
(3)配置用户环境变量
nano /etc/profile
(4)添加如下语句(一定要放中间)
if [ "$PS1" ]; then
if [ "$BASH" ] && [ "$BASH" != "/bin/sh" ]; then
# The file bash.bashrc already sets the default PS1.
# PS1='\h:\w\$ '
if [ -f /etc/bash.bashrc ]; then
. /etc/bash.bashrc
fi
else
if [ "`id -u`" -eq 0 ]; then
PS1='# '
else
PS1='$ '
fi
fi
fi
export JAVA_HOME=/usr/local/java/jdk1.8.0_152
export JRE_HOME=/usr/local/java/jdk1.8.0_152/jre
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOME/bin
if [ -d /etc/profile.d ]; then
for i in /etc/profile.d/*.sh; do
if [ -r $i ]; then
. $i
fi
done
unset i
fi
(5)使用户环境变量生效
source /etc/profile
(6)测试是否安装成功
$ java -version
java version "1.8.0_152"
Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)
3.3 安装Logstash
3.3.1 创建安装目录
$ sudo mkdir /usr/local/logstash
3.3.2 下载Logstash安装文件
$ wget -P /usr/local/logstash https://artifacts.elastic.co/downloads/logstash/logstash-6.2.4.tar.gz
3.3.2 解压缩安装文件
$ cd /usr/local/logstash/
$ sudo tar -zxvf logstash-6.2.4.tar.gz
3.3.3 测试安装是否成功
测试: 快速启动,标准输入输出作为input和output,没有filter
$ cd logstash-6.2.4/
$ ./bin/logstash -e 'input { stdin {} } output { stdout {} }'
Sending Logstash's logs to /usr/local/logstash/logstash-6.2.4/logs which is now configured via log4j2.properties
[2021-05-27T00:22:28,729][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/usr/local/logstash/logstash-6.2.4/modules/fb_apache/configuration"}
[2021-05-27T00:22:28,804][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/usr/local/logstash/logstash-6.2.4/modules/netflow/configuration"}
[2021-05-27T00:22:29,827][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2021-05-27T00:22:30,979][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.2.4"}
[2021-05-27T00:22:31,821][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2021-05-27T00:22:36,463][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>1, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50}
[2021-05-27T00:22:36,690][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#"}
The stdin plugin is now waiting for input:
[2021-05-27T00:22:36,853][INFO ][logstash.agent ] Pipelines running {:count=>1, :pipelines=>["main"]}
## 此时命令窗口停留在等待输入状态,键盘键入任意字符 ##
hello world
## 下方是Logstash输出到效果 ##
{
"@timestamp" => 2021-05-26T16:22:52.527Z,
"host" => "*******",
"message" => "hello world",
"@version" => "1"
}
4.1 常用启动参数
| 参数 | 说明 | 举例 |
|---|---|---|
| -e | 立即执行,使用命令行里的配置参数启动实例 | ./bin/logstash -e ‘input {stdin {}} output {stdout {}}’ |
| -f | 指定启动实例的配置文件 | ./bin/logstash -f config/test.conf |
| -t | 测试配置文件的正确性 | ./bin/logstash-f config/test.conf -t |
| -l | 指定日志文件名称 | ./bin/logstash-f config/test.conf -l logs/test.log |
| -w | 指定filter线程数量,默认线程数是5 | ./bin/logstash-f config/test.conf -w 8 |
4.2 配置文件结构及语法
(1)区段
Logstash通过{}来定义区域,区域内可以定义插件,一个区域内可以定义多个插件,如下:
input {
stdin {
}
beats {
port => 5044
}
}
(2)数据类型
Logstash仅支持少量的数据类型:
- Boolean:ssl_enable => true
- Number:port => 33
- String:name => “Hello world”
- Commonts:# this is a comment
(3)字段引用
Logstash数据流中的数据被称之为Event对象,Event以JSON结构构成,Event的属性被称之为字段,如果你像在配置文件中引用这些字段,只需要把字段的名字写在中括号[]里就行了,如[type],对于嵌套字段每层字段名称都写在[]里就可以了,比如:[tags][type];除此之外,对于Logstash的arrag类型支持下标与倒序下表,如:[tags][type][0],[tags][type][-1]。
(4)条件判断
Logstash支持下面的操作符:
- equality:==, !=, <, >, <=, >=
- regexp:=~, !~
- inclusion:in, not in
- boolean:and, or, nand, xor
- unary:!
例如:
if EXPRESSION {
...
} else if EXPRESSION {
...
} else {
...
}
(5)环境变量引用
Logstash支持引用系统环境变量,环境变量不存在时可以设置默认值,例如:
export TCP_PORT=12345
input {
tcp {
port => "${TCP_PORT:54321}"
}
}
4.3 常用输入插件(Input plugin)
输入插件包含有以下多种,详情查看官网文档-常用输入插件:
- elasticsearch
- exec
- file
- github
- http
- jdbc
- jms
- jmx
- kafka
- log4j
- rabbitmq
- redis
- tcp
- udp
- unix
- websocket
4.3.1 File读取插件
文件读取插件主要用来抓取文件的变化信息,将变化信息封装成Event进程处理或者传递。
- 配置事例
input
file {
path => ["/var/log/*.log", "/var/log/message"]
type => "system"
start_position => "beginning"
}
}
- 常用参数
| 参数名称 | 类型 | 默认值 | 描述信息 |
|---|---|---|---|
| add_field | hash | {} | 用于向Event中添加字段 |
| close_older | number | 3600 | 设置文件多久秒内没有更新就关掉对文件的监听 |
| codec | string | “plain” | 输入数据之后对数据进行解码 |
| delimiter | string | “\n” | 文件内容的行分隔符,默认按照行进行Event封装 |
| discover_interval | number | 15 | 间隔多少秒查看一下path匹配对路径下是否有新文件产生 |
| enable_metric | boolean | true | |
| exclude | array | 无 | path匹配的文件中指定例外,如:path => “/var/log/“;exclude =>”.gz” |
| id | string | 无 | 区分两个相同类型的插件,比如两个filter,在使用Monitor API监控是可以区分,建议设置上ID |
| ignore_older | number | 无 | 忽略历史修改,如果设置3600秒,logstash只会发现一小时内被修改过的文件,一小时之前修改的文件的变化不会被读取,如果再次修改该文件,所有的变化都会被读取,默认被禁用 |
| max_open_files | number | 无 | logstash可以同时监控的文件个数(同时打开的file_handles个数),如果你需要处理多于这个数量多文件,可以使用“close_older”去关闭一些文件 |
| path | array | 无 | 必须设置项,用于匹配被监控的文件,如“/var/log/.log”或者“/var/log//.log”,必须使用绝对路径 |
| sincedb_path | string | 无 | 文件读取记录,必须指定一个文件而不是目录,文件中保存没个被监控的文件等当前inode和byteoffset,默认存放位置“$HOME/.sincedb*” |
| sincedb_write_interval | number | 15 | 间隔多少秒写一次sincedb文件 |
| start_position | “beginning”,“end” | ” end” | 从文件等开头还是结尾读取文件内容,默认是结尾,如果需要导入文件中的老数据,可以设置为“beginning”,该选项只在第一次启动logstash时有效,如果文件已经存在于sincedb的记录内,则此配置无效 |
| stat_interval | number | 1 | 间隔多少秒检查一下文件是否被修改,加大此参数将降低系统负载,但是增加了发现新日志的间隔时间 |
| tags | array | 无 | 可以在Event中增加标签,以便于在后续的处理流程中使用 |
| type | string | Event的type字段,如果采用elasticsearch做store,在默认情况下将作为elasticsearch的type |
4.3.2 TCP监听插件
TCP插件有两种工作模式,“Client”和“Server”,分别用于发送网络数据和监听网络数据。
- 配置事例
tcp {
port => 41414
}
- 常用参数(空 => 同上)
| 参数名称 | 类型 | 默认值 | 描述信息 |
|---|---|---|---|
| add_field | |||
| codec | |||
| enable_metric | |||
| host | |||
| id | |||
| mode | “server”、“client” | “server” | “server”监听“client”的连接请求,“client”连接“server” |
| port | number | 无 | 必须设置项,“server”模式时指定监听端口,“client”模式指定连接端口 |
| proxy_protocol | boolean | false | Proxyprotocol support, only v1 is supported at this time |
| ssl_cert | |||
| ssl_enable | |||
| ssl_extra_chain_certs | |||
| ssl_key | |||
| ssl_key_passphrase | |||
| ssl_verify | |||
| tags | |||
| type |
4.3.3 Redis读取插件
用于读取Redis中缓存的数据信息。
- 配置事例
input {
redis {
host => "127.0.0.1"
port => 6379
data_type => "list"
key => "logstash-list"
}
}
- 常用参数(空 => 同上)
| 参数名称 | 类型 | 默认值 | 描述信息 |
|---|---|---|---|
| add_field | |||
| batch_count | number | 125 | 使用redis的batch特性,需要redis2.6.0或者更新的版本 |
| codec | |||
| data_type | list,channel, pattern_channel | 无 | 必须设置项,根据设置不同,订阅redis使用不同的命令,依次是:BLPOP、SUBSCRIBE、PSUBSCRIBE |
| db | number | 0 | 指定使用的redis数据库 |
| enable_metric | |||
| host | string | 127.0.0.1 | redis服务地址 |
| id | |||
| key | string | 无 | 必须设置项,reidslist或者channel的key名称 |
| password | string | 无 | redis密码 |
| port | number | 6379 | redis连接端口号 |
| tags | |||
| threads | number | 1 | |
| timeout | number | 5 | redis服务连接超时时间,单位:秒 |
注意:
data_type 需要注意的是“channel”和“pattern_channel”是广播类型,相同的数据会同时发送给订阅了该channel的logstash,也就是说在logstash集群环境下会出现数据重复,集群中的每一个节点都将收到同样的数据,但是在单节点情况下,“pattern_channel”可以同时定于满足pattern的多个key
4.3.4 Kafka读取插件
用于读取Kafka中推送的主题数据信息。
- 配置事例
input {
kafka {
bootstrap_servers => "kafka-01:9092,kafka-02:9092,kafka-03:9092"
topics_pattern => "elk-.*"
consumer_threads => 5
decorate_events => true
codec => "json"
auto_offset_reset => "latest"
group_id => "logstash1"##logstash 集群需相同
}
}
- 常用参数:
| 参数名称 | 类型 | 默认值 | 描述信息 |
|---|---|---|---|
| bootstrap_servers | string | localhost:9092 | Kafka列表,用于建立与集群的初始连接 |
| topics_pattern | string | 要订阅的主题正则表达式模式。使用此配置时,主题配置将被忽略。 | |
| consumer_threads | number | 并发线程数,理想情况下,您应该拥有与分区数量一样多的线程 | |
| decorate_events | string | none | 可接受的值为:none/basic/extended/false |
| codec | codec | plain | 用于输入数据的编解码器 |
| auto_offset_reset | string | 当Kafka初始偏移量 | |
| group_id | String | logstash | 该消费者所属的组的标识符 |
注意:
- auto_offset_reset: earliest-将偏移量自动重置为最早的偏移量;latest-自动将偏移量重置为最新偏移量;none-如果未找到消费者组的先前偏移量,则向消费者抛出异常;anything else-向消费者抛出异常。
- decorate_events: none:未添加元数据,basic:添加了记录的属性,extended:记录的属性,添加标题,false:不建议使用的别名 none,true:不建议使用的别名 basic
4.4 常用过滤插件(Filter plugin)
丰富的过滤器插件的是 logstash威力如此强大的重要因素,过滤器插件主要处理流经当前Logstash的事件信息,可以添加字段、移除字段、转换字段类型,通过正则表达式切分数据等,也可以根据条件判断来进行不同的数据处理方式,详情查看官网文档-常用过滤插件
4.4.1 grok正则捕获
grok 是Logstash中将非结构化数据解析成结构化数据以便于查询的最好工具,非常适合解析syslog logs,apache log, mysql log,以及一些其他的web log
(1)预定义表达式调用:
- Logstash提供120个常用正则表达式可供安装使用,安装之后你可以通过名称调用它们,语法如下:%{SYNTAX:SEMANTIC}
- SYNTAX:表示已经安装的正则表达式的名称
- SEMANTIC:表示从Event中匹配到的内容的名称
例如:
Event的内容为“[debug] 127.0.0.1 - test log content”,匹配%{IP:client}将获得“client: 127.0.0.1”的结果,前提安装了IP表达式;如果你在捕获数据时想进行数据类型转换可以使用%{NUMBER:num:int}这种语法,默认情况下,所有的返回结果都是string类型,当前Logstash所支持的转换类型仅有“int”和“float”;
一个稍微完整一点的事例:
- 日志文件http.log内容:55.3.244.1 GET /index.html 15824 0.043
- 表达式:%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
- 配置文件内容:
input {
file {
path => "/var/log/http.log"
}
}
filter {
grok {
match => {"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"}
}
}
- 输出结果:
client: 55.3.244.1
method: GET
request: /index.html
bytes: 15824
duration: 0.043
(2)自定义表达式调用
语法:(?
举例:捕获10或11和长度的十六进制queue_id可以使用表达式(?
安装自定义表达式
与预定义表达式相同,你也可以将自定义的表达式配置到Logstash中,然后就可以像于定义的表达式一样使用;以下是操作步骤说明:
-
1、在Logstash根目录下创建文件夹“patterns”,在“patterns”文件夹中创建文件“extra”(文件名称无所谓,可自己选择有意义的文件名称);
-
2、在文件“extra”中添加表达式,格式:patternName regexp,名称与表达式之间用空格隔开即可,如下:
# contents of ./patterns/postfix:
POSTFIX_QUEUEID [0-9A-F]{10,11}
- 3、使用自定义的表达式时需要指定“patterns_dir”变量,变量内容指向表达式文件所在的目录,举例如下:
<1>日志内容
Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<[email protected]>
<2>Logstash配置
filter {
grok {
patterns_dir => ["./patterns"]
match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" }
}
}
<3>运行结果
timestamp: Jan 1 06:25:43
logsource: mailserver14
program: postfix/cleanup
pid: 21403
queue_id: BEF25A72965
(3)grok常用配置参数(空 => 同上)
| 参数名称 | 类型 | 默认值 | 描述信息 |
|---|---|---|---|
| add_field | |||
| add_tag | |||
| break_on_match | boolean | true | match字段存在多个pattern时,当第一个匹配成功后结束后面的匹配,如果想匹配所有的pattern,将此参数设置为false |
| enable_metric | |||
| id | |||
| keep_empty_captures | boolean | false | 如果为true,捕获失败的字段奖设置为空值 |
| match | array | {} | 设置pattern数组: match=> {“message” => [“Duration: %{NUMBER:duration}”,”Speed: %{NUMBER:speed}”]} |
| named_captures_only | boolean | true | If true, only store named captures from grok. |
| overwrite | array | [] | 覆盖字段内容: match=> { “message” => “%{SYSLOGBASE} %{DATA:message}” } overwrite=> [ “message” ] |
| patterns_dir | array | [] | 指定自定义的pattern文件存放目录,Logstash在启动时会读取文件夹内patterns_files_glob 匹配的所有文件内容 |
| patterns_files_glob | string | “*” | 用于匹配patterns_dir中的文件 |
| periodic_flush | boolean | false | 定期调用filter的flush方法 |
| remove_field | array | [] | 从Event中删除任意字段: remove_field=> [ “foo_%{somefield}” ] |
| remove_tag | array | [] | 删除“tags”中的值: remove_tag=> [ “foo_%{somefield}” ] |
| tag_on_failure | array | [“_grokparsefailure”] | 当没有匹配成功时,将此array添加到“tags”字段内 |
| tag_on_timeout | string | “_groktimeout” | 当匹配超时时,将此内容添加到“tags”字段内 |
| timeout_millis | number | 30000 | 设置单个match到超时时间,单位:毫秒,如果设置为0,则不启用超时设置 |
4.4.2 date时间处理插件
该插件用于时间字段的格式转换,比如将“Apr 17 09:32:01”(MMM dd HH:mm:ss)转换为“MM-dd HH:mm:ss”。而且通常情况下,Logstash会为自动给Event打上时间戳,但是这个时间戳是Event的处理时间(主要是input接收数据的时间),和日志记录时间会存在偏差(主要原因是buffer),我们可以使用此插件用日志发生时间替换掉默认是时间戳的值。
常用配置参数(空 => 同上)
| 参数名称 | 类型 | 默认值 | 描述信息 |
|---|---|---|---|
| add_field | |||
| add_tag | |||
| enable_metric | |||
| id | |||
| locale | |||
| match | array | [] | 时间字段匹配,可自定多种格式,直到匹配到或匹配结束 |
| periodic_flush | |||
| remove_field | |||
| remove_tag | |||
| tag_on_failure | |||
| target | string | “@timestamp” | 指定match匹配并且转换为date类型的存储位置(字段),默认覆盖到“@timestamp” |
| timezone | string | 无 | 指定时间格式化的时区 |
注意:
match的格式:时间字段匹配,可自定多种格式,直到匹配到或匹配结束,格式: [ field,formats…],如:match=>[ “logdate”,“MMM dd yyyy HH:mm:ss”,“MMM d yyyy HH:mm:ss”,“ISO8601”]
4.4.3 mutate数据修改插件
mutate 插件是 Logstash另一个重要插件。它提供了丰富的基础类型数据处理能力。可以重命名,删除,替换和修改事件中的字段。
常用配置参数(空 => 同上)
| 参数名称 | 类型 | 默认值 | 描述信息 |
|---|---|---|---|
| add_field | |||
| add_tag | |||
| convert | hash | 无 | 将指定字段转换为指定类型,字段内容是数组,则转换所有数组元素,如果字段内容是hash,则不做任何处理,目前支持的转换类型包括:integer,float, string, and boolean.例如: convert=> { “fieldname” => “integer” } |
| enable_metric | |||
| gsub | array | 无 | 类似replace方法,使用指定内容替换掉目标字符串的现有内容,前提是目标字段必须是字符串,否则不做任何处理,例如:[ “fieldname”, “/”, ““, “fieldname2”, “[\?#-]”, “.”],解释:使用“”替换掉“fieldname”中的所有“/”,使用“.”替换掉“fieldname2”中的所有“\”“?”、“#”和“-” |
| id | |||
| join | hash | 无 | 使用指定的符号将array字段的每个元素连接起来,对非array字段无效。例如: 使用“,”将array字段“fieldname”的每一个元素连接成一个字符串: join=> { “fieldname” => “,” } |
| lowercase | array | 无 | 将自定的字段值转换为小写 |
| merge | hash | 无 | 合并两个array或者hash,如果是字符串,将自动转换为一个单元素数组;将一个array和一个hash合并。例如: 将”added_field”合并到”dest_field”: merge=> { “dest_field” => “added_field” } |
| periodic_flush | |||
| remove_field | |||
| remove_tag | |||
| rename | hash | 无 | 修改一个或者多个字段的名称。例如: 将”HOSTORIP”改名为”client_ip”: rename=> { “HOSTORIP” => “client_ip” } |
| replace | hash | 无 | 使用新值完整的替换掉指定字段的原内容,支持变量引用。例如: 使用字段“source_host”的内容拼接上字符串“: My new message”之后的结果替换“message”的值: replace=> { “message” => “%{source_host}: My new message” } |
| split | hash | 无 | 按照自定的分隔符将字符串字段拆分成array字段,只能作用于string类型的字段。例如: 将“fieldname”的内容按照“,”拆分成数组: split=> { “fieldname” => “,” } |
| strip | array | 无 | 去掉字段内容两头的空白字符。例如: 去掉“field1”和“field2”两头的空格: strip=> [“field1”, “field2”] |
| update | hash | 无 | 更新现有字段的内容,例如: 将“sample”字段的内容更新为“Mynew message”: update=> { “sample” => “My new message” } |
| uppercase | array | 无 | 将字符串转换为大写 |
4.4.4 JSON插件
JSON插件用于解码JSON格式的字符串,一般是一堆日志信息中,部分是JSON格式,部分不是的情况下
(1)配置事例
json {
source => ...
}
- 事例配置,message是JSON格式的字符串:
"{\"uid\":3081609001,\"type\":\"signal\"}"
filter {
json {
source => "message"
target => "jsoncontent"
}
}
- 输出结果:
{
"@version": "1",
"@timestamp": "2014-11-18T08:11:33.000Z",
"host": "web121.mweibo.tc.sinanode.com",
"message": "{\"uid\":3081609001,\"type\":\"signal\"}",
"jsoncontent": {
"uid": 3081609001,
"type": "signal"
}
}
- 如果从事例配置中删除
target,输出结果如下:
{
"@version": "1",
"@timestamp": "2014-11-18T08:11:33.000Z",
"host": "web121.mweibo.tc.sinanode.com",
"message": "{\"uid\":3081609001,\"type\":\"signal\"}",
"uid": 3081609001,
"type": "signal"
}
(2)常用配置参数(空 => 同上)
| 参数名称 | 类型 | 默认值 | 描述信息 |
|---|---|---|---|
| add_field | |||
| add_tag | |||
| enable_metric | |||
| id | |||
| periodic_flush | |||
| remove_field | |||
| remove_tag | |||
| skip_on_invalid_json | boolean | false | 是否跳过验证不通过的JSON |
| source | string | 无 | 必须设置项,指定需要解码的JSON字符串字段 |
| tag_on_failure | |||
| target | string | 无 | 解析之后的JSON对象所在的字段名称,如果没有,JSON对象的所有字段将挂在根节点下 |
4.4.5 elasticsearch查询过滤插件
用于查询Elasticsearch中的事件,可将查询结果应用于当前事件中
常用配置参数(空 => 同上)
| 参数名称 | 类型 | 默认值 | 描述信息 |
|---|---|---|---|
| add_field | |||
| add_tag | |||
| ca_file | string | 无 | SSL Certificate Authority file path |
| enable_sort | boolean | true | 是否对结果进行排序 |
| fields | array | {} | 从老事件中复制字段到新事件中,老事件来源于elasticsearch(用于查询更新) |
| hosts | array | [“localhost:9200”] | elasticsearch服务列表 |
| index | string | “” | 用逗号分隔的elasticsearch索引列表,如果要操作所有所有使用“_all”或者“”,保存数据到elasticsearch时,如果索引不存在会自动以此创建 |
| password | string | 无 | 密码 |
| periodic_flush | |||
| query | string | 无 | 查询elasticsearch的查询字符串 |
| remove_field | |||
| remove_tag | |||
| result_size | number | 1 | 查询elasticsearch时,返回结果的数量 |
| sort | string | “@timestamp:desc” | 逗号分隔的“:”列表,用于查询结果排序 |
| ssl | boolean | false | SSL |
| tag_on_failure | |||
| user | string | 无 | 用户名 |
4.5 常用输出插件(Output plugin)
4.5.1 ElasticSearch输出插件
用于将事件信息写入到Elasticsearch中,官方推荐插件,ELK必备插件
(1)配置事例
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "filebeat-%{type}-%{+yyyy.MM.dd}"
template_overwrite => true
}
}
(2)常用配置参数(空 => 同上)
| 参数名称 | 类型 | 默认值 | 描述信息 |
|---|---|---|---|
| absolute_healthcheck_path | boolean | false | 当配置了“healthcheck_path”时,决定elasticsearch健康检查URL是否按照绝对路径配置。例如: elasticsearch访问路径为:”http://localhost:9200/es“,“healthcheck_path”为”/health”, 当前参数为true时的访问路径为:”http://localhost:9200/es/health“, 当前参数为false时的访问路径为:”http://localhost:9200/health” |
| absolute_sniffing_path | boolean | false | 当配置了“sniffing_path”时,决定elasticsearch的sniffing访问路径配置。例如: elasticsearch访问路径为:“http://localhost:9200/es”,“sniffing_path”为“/_sniffing”, 当前参数为true时的访问路径为:“http://localhost:9200/es/_sniffing”, 当前参数为false时的访问路径为:“http://localhost:9200/_sniffing” |
| action | string | “index” | 对elasticsearch的操作类型,可用的操作类型: index:索引Logstash事件数据到elasticsearch; delete:根据id删除文档,id必须指定; delete:根据id删除文档,id必须指定; update:根据id更新文档 |
| cacert | string | 无 | .cer或者.pem证书文件路径,使用证书进行elasticsearch认证 |
| codec | |||
| doc_as_upsert | boolean | false | 使update启用upsert模式,即文档不存在时创建新文档 |
| document_id | string | 无 | elasticsearch中的文档id,用来覆盖已经保存到elasticsearch中的文档 |
| document_type | string | 无 | 指定存入elasticsearch中的文档的type,没有指定的情况下会使用Event信息中的“type”字段的值作为elasticsearch的type |
| enable_metric | |||
| failure_type_logging_whitelist | array | [] | elasricsearch报错白名单,白名单的异常信息不会被记入logstash的log中,比如你想忽略掉所有的“document_already_exists_exception”异常 |
| flush_size | |||
| healthcheck_path | string | “/” | elasricsearch检查状态检查路径 |
| hosts | string | [//127.0.0.1] | elasticsearch服务地址列表,如果配置多个将启用负载均衡 |
| id | |||
| idle_flush_time | number | 1 | 间隔多长时间将数据输出到elasticsearch中一次,主要用于较慢的事件 |
| index | string | “logstash-%{+YYYY.MM.dd}” | 指定elasticsearch存储数据时的所有名称,支持变量引用,比如你可以按天创建索引,方便删除历史数据或者查询制定范围内的数据 |
| keystore | string | 无 | 用于指定密钥库路径,可以是.jks或者.p12 |
| keystore_password | string | 无 | 密钥库密码 |
| manage_template | boolean | true | 是否启用elasticsearch模版,Logstash自带一个模版,但是只有名称匹配“logstash-*”的索引才会应用该默版 |
| parameters | hash | 无 | 添加到elasticsearch URL后面的参数键值对 |
| parent | string | “nil” | 为文档子节点指定父节点的id |
| password | string | 无 | elasticsearch集群访问密码 |
| path | string | 无 | 当设置了elasticsearch代理时用此参数从定向HTTP API,如果“hosts”中已经包含此路径,则不需要设置 |
| pipeline | string | “nil” | 设置Event管道 |
| pool_max | number | 1000 | elasticsearch最大连接数 |
| pool_max_per_route | number | 100 | 每个“endpoint”的最大连接数 |
| proxy | string | 无 | 代理URL |
| resurrect_delay | number | 5 | 检查挂掉的“endpoint”是否恢复正常的频率 |
| retry_initial_interval | number | 2 | 设置批量重试的时间间隔,重试到 “retry_max_interval”次 |
| retry_max_interval | number | 64 | Setmax interval in seconds between bulk retries. |
| retry_on_conflict | number | 1 | Thenumber of times Elasticsearch should internally retry an update/upserteddocument |
| routing | string | 无 | 指定Event路由 |
| script | string | “” | 设置“scriptedupdate”模式下的脚本名称 |
| script_lang | string | “painless” | 设置脚本语言 |
| script_type | “inline”、“indexed”、 “file” | [“inline”] | Definethe type of script referenced by “script” variable inline :”script” contains inline script indexed : “script” containsthe name of script directly indexed in elasticsearch file : “script”contains the name of script stored in elasticseach’s config directory |
| script_var_name | string | “event” | Setvariable name passed to script (scripted update) |
| scripted_upsert | boolean | false | ifenabled, script is in charge of creating non-existent document (scriptedupdate) |
| sniffing | |||
| sniffing_delay | |||
| sniffing_path | |||
| ssl | |||
| ssl_certificate_verification | |||
| template | string | 无 | 设置自定义的默版存放路径 |
| template_name | string | “logstash” | 设置使用的默版名称 |
| template_overwrite | boolean | false | 是否始终覆盖现有模版 |
| timeout | number | 60 | 网络超时时间 |
| truststore | string | 无 | “:truststore”或者“:cacert”证书库路径 |
| truststore_password | string | 无 | 证书库密码 |
| upsert | string | “” | Setupsert content for update mode.s Create a new document with this parameter asjson string if document_id doesn’texists |
| user | string | “” | elasticsearch用户名 |
| validate_after_inactivity | number | 10000 | 间隔多长时间保持连接可用 |
| version | string | 无 | 存入elasticsearch的文档的版本号 |
| version_type | “internal”、“external”、 “external_gt”、 “external_gte”、“force” | 无 | |
| workers | string | 1 | whenwe no longer support the :legacy type This is hacky, but it can only be herne |
4.5.2 Redis输出插件
用于将Event写入Redis中进行缓存,通常情况下Logstash的Filter处理比较吃系统资源,复杂的Filter处理会非常耗时,如果Event产生速度比较快,可以使用Redis作为buffer使用
(1)配置事例
output {
redis {
host => "127.0.0.1"
port => 6379
data_type => "list"
key => "logstash-list"
}
}
(2)常用配置参数(空 => 同上)
| 参数名称 | 类型 | 默认值 | 描述信息 |
|---|---|---|---|
| batch | boolean | false | 是否启用redis的batch模式,仅在data_type=”list”时有效 |
| batch_events | number | 50 | batch大小,batch达到此大小时执行“RPUSH” |
| batch_timeout | number | 5 | batch超时时间,超过这个时间执行“RPUSH” |
| codec | |||
| congestion_interval | number | 1 | 间隔多长时间检查阻塞,如果设置为0,则没个Event检查一次 |
| congestion_threshold | number | 0 | |
| data_type | “list”、“channel” | 无 | 存储在redis中的数据类型,如果使用“list”,将采用“RPUSH”操作,如果是“channel”,将采用“PUBLISH”操作 |
| db | number | 0 | 使用的redis数据库编号 |
| enable_metric | |||
| host | array | [“127.0.0.1”] | redis服务列表,如果配置多个,将随机选择一个,如果当前的redis服务不可用,将选择下一个 |
| id | |||
| key | string | 无 | Thename of a Redis list or channel. Dynamic names are valid here, forexample logstash-%{type}. |
| password | string | 无 | redis服务密码 |
| port | number | 6379 | redis服务监听端口 |
| reconnect_interval | number | 1 | 连接失败时的重连间隔 |
| shuffle_hosts | boolean | true | Shufflethe host list during Logstash startup. |
| timeout | number | 5 | redis连接超时时间 |
| workers | number | 1 | whenwe no longer support the :legacy type This is hacky, but it can only be herne |
4.5.3 File输出插件
用于将Event输出到文件内
(1)配置事例
output {
file {
path => ...
codec => line { format => "custom format: %{message}"}
}
}
(2)常用配置参数(空 => 同上)
| 参数名称 | 类型 | 默认值 | 描述信息 |
|---|---|---|---|
| codec | |||
| create_if_deleted | boolean | true | 如果目标文件被删除,则在写入事件时创建新文件 |
| dir_mode | number | -1 | 设置目录的访问权限,如果为“-1”,使用操作系统默认的访问权限 |
| enable_metric | |||
| file_mode | number | -1 | 设置文件的访问权限,如果为“-1”,使用操作系统默认的访问权限 |
| filename_failure | string | “_filepath_failures” | 如果指定的文件路径无效,这会在目录内创建这个文件并记录数据 |
| flush_interval | number | 2 | flush间隔 |
| gzip | boolean | false | 是否启用gzip压缩 |
| id | |||
| path | string | 无 | 必须设置项,文件输出路径,如:path =>”./test-%{+YYYY-MM-dd}.txt” |
| workers | string | 1 | whenwe no longer support the :legacy type This is hacky, but it can only be herne |
4.5.4 Kafka输出插件
用于将Event输出到Kafka指定的Topic中,官网Kafka详情配置
(1)配置事例
output {
kafka {
bootstrap_servers => "localhost:9092"
topic_id => "test"
compression_type => "gzip"
}
}
(2)常用配置参数(空 => 同上)
| 参数名称 | 类型 | 默认值 | 描述信息 |
|---|---|---|---|
| bootstrap_servers | string | Kafka集群信息,格式为 host1:port1,host2:port2 | |
| topic_id | string | 产生消息的主题 | |
| compression_type | String | none | 生产者生成的所有数据的压缩类型。默认为无(即无压缩)。有效值为 none、gzip、snappy 或 lz4。 |
| batch_size | number | 16384 | 配置以字节为单位控制默认批处理大小 |
| buffer_memory | number | 33554432(32MB) | 生产者可用于缓冲等待发送到服务器的记录的总内存字节数 |
| max_request_size | number | 1048576(1MB) | 请求的最大大小 |
| flush_interval | number | 2 | flush间隔 |
| gzip | boolean | false | 是否启用gzip压缩 |
| id | |||
| path | string | 无 | 必须设置项,文件输出路径,如:path =>”./test-%{+YYYY-MM-dd}.txt” |
| workers | string | 1 | whenwe no longer support the :legacy type This is hacky, but it can only be herne |
4.6 常用编码插件(Codec plugin)
4.6.1 JSON编码插件
直接输入预定义好的 JSON 数据,这样就可以省略掉 filter/grok 配置
- 配置事例
json {
}
- 常用配置参数
| 参数名称 | 类型 | 默认值 | 描述信息 |
| ------------- | ------ | ------- | -------- |
| charset | string | “UTF-8” | 字符集 |
| enable_metric | | | |
| id | | | |
5.1 接收Filebeat事件,输出到Redis
input {
beats {
port => 5044
}
}
output {
redis {
host => "127.0.0.1"
port => 6379
data_type => "list"
key => "logstash-list"
}
}
5.2 读取Redis数据,根据“type”判断,分别处理,输出到ES
input {
redis {
host => "127.0.0.1"
port => 6379
data_type => "list"
key => "logstash-list"
}
}
filter {
if [type] == "application" {
grok {
match => ["message", "(?m)-(?.+?):(?(?>\d\d){1,2}-(?:0?[1-9]|1[0-2])-(?:(?:0[1-9])|(?:[12][0-9])|(?:3[01])|[1-9]) (?:2[0123]|[01]?[0-9]):(?:[0-5][0-9]):(?:(?:[0-5][0-9]|60)(?:[:.,][0-9]+)?)) \[(?(\b\w+\b)) *\] (?(\b\w+\b)) \((?.*?)\) - (?.*)"]
}
date {
match => ["logTime", "yyyy-MM-dd HH:mm:ss,SSS"]
}
json {
source => "message"
}
date {
match => ["timestamp", "yyyy-MM-dd HH:mm:ss,SSS"]
}
}
if [type] == "application_bizz" {
json {
source => "message"
}
date {
match => ["timestamp", "yyyy-MM-dd HH:mm:ss,SSS"]
}
}
mutate {
remove_field => ["@version", "beat", "logTime"]
}
}
output {
stdout{
}
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "filebeat-%{type}-%{+yyyy.MM.dd}"
document_type => "%{documentType}"
template_overwrite => true
}
}
6.1 以logstash作为日志搜索器
架构:logstash采集、处理、转发到elasticsearch存储,在kibana进行展示
特点:这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
6.2 消息模式
消息模式:Beats 还不支持输出到消息队列(新版本除外:5.0版本及以上),所以在消息队列前后两端只能是 Logstash 实例。logstash从各个数据源搜集数据,不经过任何处理转换仅转发出到消息队列(kafka、redis、rabbitMQ等),后logstash从消息队列取数据进行转换分析过滤,输出到elasticsearch,并在kibana进行图形化展示
架构(Logstash进行日志解析所在服务器性能各方面必须要足够好):
模式特点:这种架构适合于日志规模比较庞大的情况。但由于 Logstash 日志解析节点和 Elasticsearch 的负荷比较重,可将他们配置为集群模式,以分担负荷。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,但依然存在 Logstash 占用系统资源过多的问题
工作流程:Filebeat采集—> logstash转发到kafka—> logstash处理从kafka缓存的数据进行分析—> 输出到es—> 显示在kibana
6.3 logstash(非filebeat)进行文件采集,输出到kafka缓存,读取kafka数据并处理输出到文件或es
6.4 logstash同步mysql数据库数据到es(logstash5版本以上已集成jdbc插件,无需下载安装,直接使用)
首先从结构对比,我们会惊人的发现,两者是多么的相似!Logstash的Shipper、Broker、Indexer分别和Flume的Source、Channel、Sink各自对应!只不过是Logstash集成了,Broker可以不需要,而Flume需要单独配置,且缺一不可,但这再一次说明了计算机的设计思想都是通用的!只是实现方式会不同而已。
从程序员的角度来说,上文也提到过了,Flume是真的很繁琐,你需要分别作source、channel、sink的手工配置,而且涉及到复杂的数据采集环境,你可能还要做多个配置,这在上面提过了,反过来说Logstash的配置就非常简洁清晰,三个部分的属性都定义好了,程序员自己去选择就行,就算没有,也可以自行开发插件,非常方便。当然了,Flume的插件也很多,但Channel就只有内存和文件这两种(其实现在不止了,但常用的也就两种)。读者可以看得出来,两者其实配置都是非常灵活的,只不过看场景取舍罢了。
其实从作者和历史背景来看,两者最初的设计目的就不太一样。Flume本身最初设计的目的是为了把数据传入HDFS中(并不是为了采集日志而设计,这和Logstash有根本的区别),所以理所应当侧重于数据的传输,程序员要非常清楚整个数据的路由,并且比Logstash还多了一个可靠性策略,上文中的channel就是用于持久化目的,数据除非确认传输到下一位置了,否则不会删除,这一步是通过事务来控制的,这样的设计使得可靠性非常好。相反,Logstash则明显侧重对数据的预处理,因为日志的字段需要大量的预处理,为解析做铺垫。
回过来看我当初为什么先讲Logstash然后讲Flume?这里面有几个考虑
-
其一:Logstash其实更有点像通用的模型,所以对新人来说理解起来更简单,而Flume这样轻量级的线程,可能有一定的计算机编程基础理解起来更好;
-
其二:目前大部分的情况下,Logstash用的更加多,这个数据我自己没有统计过,但是根据经验判断,Logstash可以和ELK其他组件配合使用,开发、应用都会简单很多,技术成熟,使用场景广泛。相反Flume组件就需要和其他很多工具配合使用,场景的针对性会比较强,更不用提Flume的配置过于繁琐复杂了。
最后总结下来,我们可以这么理解他们的区别:
Logstash就像是买来的台式机,主板、电源、硬盘,机箱(Logstash)把里面的东西全部装好了,你可以直接用,当然也可以自己组装修改;
Flume就像提供给你一套完整的主板,电源、硬盘,Flume没有打包,只是像说明书一样指导你如何组装,才能运行的起来。
参考文档:
- [1] 迷途的攻城狮.CSDN: https://blog.csdn.net/chenleiking/article/details/73563930 , 2017-06-22.
- [2] Logstash 官网: https://www.elastic.co/cn/logstash