深度学习之循环神经网络 (基础)
循环神经网络简称为RNN,(之前讲到的卷积神经网络简称为CNN)。
以前我们在使用全链接网络的时候,我们将这种网络叫做Dense 或者是Deep。
Dense链接指的是全链接的。
我们输入的数据是数据样本的不同特征:x1,x2,x3....。
对于气象报道,如果我们知道当前的温度和气压来预测现在有没有雨是没有意义的,因为我们要提前报道,拿到现在的数据来推理得到现在的结果是不能够的。
所以我们要拿到之前若干天的数据,来预测后面是否会下雨。
卷积层的大小,也就是权重的个数只与通道,卷积核的个数,卷积核的大小有关,但是全连接层要和我们变换之后的数据大小有关。看上去我们卷积运算是比较复杂的,但是其实我们的权重并不多,而如果我们 使用全连接层的话,显然要使用更多的权重。所以我们在构建网络的过程中,全连接层占权重的比例是占大头的。因为我们在进行卷积的过程中,整个输入使用的卷积核是共享的,所以我们使用的权重就少。
我们将来在稠密层,如果使用全连接层进行处理,那么要进行的运算是天文数字,很难达到预期的效果,我们进行序列化数据的处理,一般使用RNN。我们需要用到共享的概念,权重共享来减少权重的数量。
我们仍然以天气情况作为我们的例子。我们将x1,x2,x3看成是一个序列,我们不仅要考虑x1,x2,x3之间的链接关系,我们还要考虑他们三者之间的前序和后序的时间顺序。换句话说,x2的数值会依赖于x1,x3的数值会依赖于x2和x1,即下一天的天气状况要部分依赖于前一天的天气状况。显然,我们一般的天气变化都是比较缓和的,很少有断崖式的变化。所以我们在预测天气的时候,大多数情况下,我们会根据前一天的情况,做出相应的判断。
RNN主要用于处理具有序列链接的输入数据,我们除了用于处理天气,股市,金融方面的数据之外。经常处理的还有我们的自然语言,自然语言是具有序列关系的,例如:我爱北京天安门,显然自然语言里面,我们用词来分割:我 爱 北京 天安门。这是有序列关系的,如果我们打乱他的顺序,是很难理解其中的意思的,例如:天安门 爱 北京 我。我们就难以理解。所以我们可以使用RNN来处理具有自然语言。
我们接下来说什么叫做RNN:
首先我们来了解一下什么叫做RNN Cell。

xt表示时刻t的数据,当然xt也是具有维度的,例如对于天气来说xt是一个三维的向量(气压,温度,地形)。经过RNN Cell转变之后,得到另外一个维度的向量,例如得到一个五维的向量,那么就说明,我们的RNN Cell是一个线性层。将输入的向量映射到另外一个向量里面。
这个线性层和我们平常用到的线性层有什么区别呢?这个线性层是共享的。
我们的输入是对应天数的特征,输入完之后送入我们的RNN里面,做线性变换,得到输出,我们将输出hn叫做hidden,就是隐层,在这里面我们要注意,它和之前线性层的区别是什么呢?我们每个输入的x,也就是序列里面的每一项,我们都送到RNN Cell里面。我们序列中每一项都和前面一项存在关系。即我们的h2里面,不仅要包含x2的信息,还要包含x1的信息。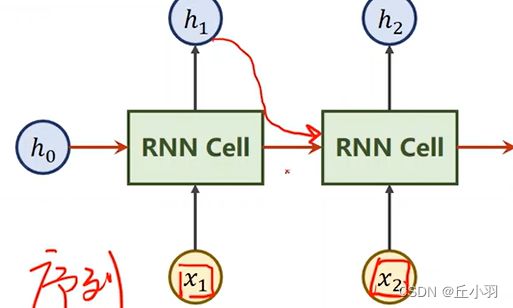
我们在得到h1之后,不仅将h1输出了,而且我们还顺手将它送进下一个输入。
如果我们有先验知识,我们就可以将其作为h0输入给RNN。
例如我们想通过图像来生成文本:那我们就可以通过CNN+FC(卷积神经网络)的输出作为h0,这样我们就把卷积神经网络和循环神经网络就接上了。
如果我们没有先验,我们就将h0设为和h1,h2大小一样的全0的元素。
显然,我们进行处理的RNN Cell是同一个线性层。
如果我们的RNN Cell是一个linear层的话:具体实现如下:
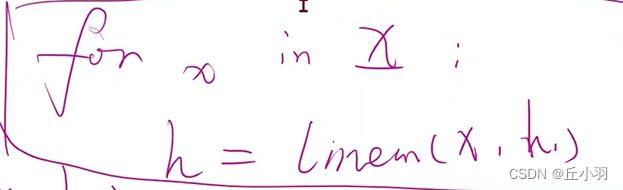
x的维度是Input_size*1,所以Wih的维度是hidden*Input_size这样我们才能得到一个hiddensize*1这样的向量。然后再加上一个偏置,而对于我们输入的hidden来说,由上一层的结果得到,结果的大小是hidden_size*1,所以我们要乘以的矩阵是hidden_size*hidden_size。向量相加,达到信息融合的效果。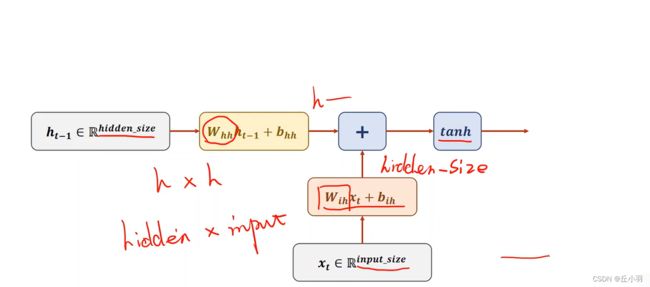
融合之后,做一个激活,在循环神经网络里面,我们喜欢使用tanh函数,为什么使用tanh函数而不是用sigmoid呢?因为tanh的输出是-1到+1,它被认为是效果比较好的激活函数。
显然我们做的运算就是这样的形式:
那么我们将我们的序列依次送进去RNN Cell里面,依次算出隐层的过程叫做循环神经网络:
如果我们要构造RNN:
有两种方法:一种是我们自己去构造RNN序列,自己写循环,另一种就是我们直接使用已经构造好的循环:
那么如果我们要构建RNN Cell的话,我们参数要设定我们输入的维度和我们隐层的维度。因为我们如果有这两个值,我们就能将权重和偏置量确定出来。
然而,我们使用的时候传入的参数是input和hidden,这里的input是batch*input_size。
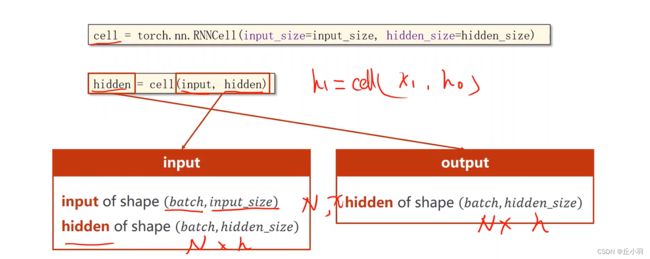

代码实现如下:
当然我们的RNN可以选择多层,但是尽量往小的选,因为RNN的计算是比较耗时的。
我们经过RNN层的输出是两个,一个是从h1到hn的序列,即每一次的输出,一个是hn就,即最后的输出。
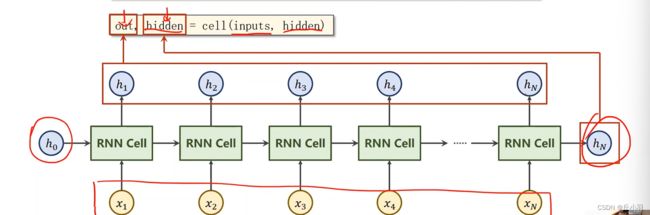
但是,难道hidden就是output的最后一个元素吗?当然不是:
下面是多层的RNN:(三层)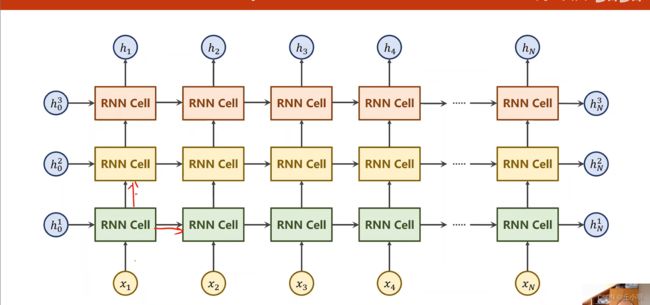

接下来我们讲一个小例子:
我们有一个seq到seq的任务(序列到序列):在这个任务里面,我们的输入是hello,我们要将hello转化为ohlol,我们想要训练循环网络来学习这个序列变换的规律。
首先我们看使用RNN Cell来实现这个功能,我们的输入是h e l l o我们隐层的输出是o h l o l。
但是这里面我们遇到的问题是,我们输入并不是向量,我们使用的是char而不是int。所以我们首先要将这些字符向量化,首先我们要将hello进行转换:
一般来说,在进行字符处理的时候,我们首先对字符构建一个词典。给每个词分配一个索引,当然可以是字母表顺序,也可以是随机的。然后我们就可以用向量表示出来: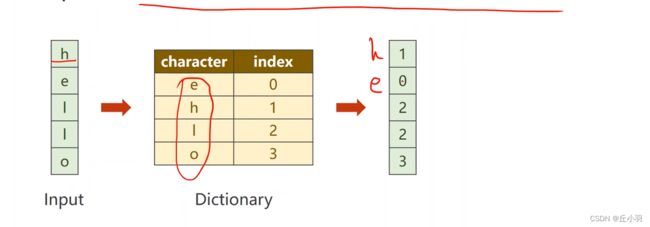
再进行转化:(将向量转化为独热向量 One-Hot Vectors)
我们将独热向量送到RNN里面作为我们的输入。
所以我们的input_size=4。显然我们输入的是独热向量,那我们对应的就是多分类问题。
我们要输出的是类别。
训练过程如下:
显然,我们进行自然语言处理的时候传入的是独热向量,每一行,也就是对应一个字符的属性,作为xi输入。我们的每个输出hi表示每一个位置输出的字符。
具体的实现代码如下:
我们在处理自然语言的时候,刚刚我们使用的是独热向量,但是独热向量是有一些缺点的,下面是列出来的一些缺点:
首先呢,独热向量的维度太高。如果是对应字符还好,但是如果是对应单词,就需要上万个维度,显然是很难进行处理的。几万维的话会面对维度诅咒。
其次呢,我们的向量是比较稀疏的。
第三,它是硬编码的,每个次或字符是对应某个向量,而不是学习出来的。
于是我们就要思考,有没有这样一种方法,能达到低纬度,稠密,而且是学习到的,这是我们的需求。我们已经发现这样的方法:EMBEDDING
就是将高维度映射到低纬度,也就是数据的降维。可以类似为我们数据结构中的稀疏矩阵转化为三元组的方式。

当然我们可以进行查询,比如说我们要查询的是第二个元素,我们就在表中找到第二行。
所以呢我们可以这样改进我们之前的过程: