numpy 创建加一行_python语法:机器学习必备Numpy库

Numpy内部解除了Python的PIL(全局解释器锁),运算效率极好,是大量机器学习框架的基础库!
NumPy是Python语言的一个扩充程序库。支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
总而言之,包含:
- 一个强大的N维数组对象 ndarray
- 广播功能函数
- 整合 C/C++/Fortran 代码的工具
- 线性代数、傅里叶变换、随机数生成等功能
今天全部是干货,都是numpy的一些实操,希望能帮助到大家。
Numpy简单创建数组
import numpy as np
# 创建简单的列表
a = [1, 2, 3, 4]
# 将列表转换为数组
b = np.array(b)Numpy查看数组属性
数组元素个数
b.size数组形状
b.shape数组维度
b.ndim数组元素类型
b.dtype快速创建N维数组的api函数
- 创建10行10列的数值为浮点1的矩阵
array_one = np.ones([10, 10])- 创建10行10列的数值为浮点0的矩阵
array_zero = np.zeros([10, 10])- 从现有的数据创建数组
- array(深拷贝)
- asarray(浅拷贝)
Numpy创建随机数组np.random
- 均匀分布
- np.random.rand(10, 10)创建指定形状(示例为10行10列)的数组(范围在0至1之间)
- np.random.uniform(0, 100)创建指定范围内的一个数
- np.random.randint(0, 100) 创建指定范围内的一个整数
- 正态分布
给定均值/标准差/维度的正态分布np.random.normal(1.75, 0.1, (2, 3))
- 数组的索引, 切片
# 正态生成4行5列的二维数组
arr = np.random.normal(1.75, 0.1, (4, 5))
print(arr)
# 截取第1至2行的第2至3列(从第0行算起)
after_arr = arr[1:3, 2:4]
print(after_arr)
数组索引
- 改变数组形状(要求前后元素个数匹配)

改变数组形状
print("reshape函数的使用!")
one_20 = np.ones([20])
print("-->1行20列<--")
print (one_20)
one_4_5 = one_20.reshape([4, 5])
print("-->4行5列<--")
print (one_4_5)Numpy计算(重要)
条件运算

import numpy as np
stus_score = np.array([[80, 88], [82, 81], [84, 75], [86, 83], [75, 81]])
stus_score > 80
import numpy as np
stus_score = np.array([[80, 88], [82, 81], [84, 75], [86, 83], [75, 81]])
np.where(stus_score < 80, 0, 90)统计运算
- 指定轴最大值amax(参数1: 数组; 参数2: axis=0/1; 0表示列1表示行)

stus_score = np.array([[80, 88], [82, 81], [84, 75], [86, 83], [75, 81]])
# 求每一列的最大值(0表示列)
print("每一列的最大值为:")
result = np.amax(stus_score, axis=0)
print(result)
print("每一行的最大值为:")
result = np.amax(stus_score, axis=1)
print(result)- 指定轴最小值amin

stus_score = np.array([[80, 88], [82, 81], [84, 75], [86, 83], [75, 81]])
# 求每一行的最小值(0表示列)
print("每一列的最小值为:")
result = np.amin(stus_score, axis=0)
print(result)
# 求每一行的最小值(1表示行)
print("每一行的最小值为:")
result = np.amin(stus_score, axis=1)
print(result)
- 指定轴平均值mean
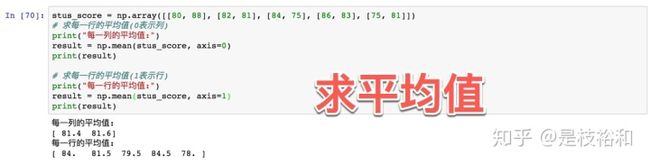
stus_score = np.array([[80, 88], [82, 81], [84, 75], [86, 83], [75, 81]])
# 求每一行的平均值(0表示列)
print("每一列的平均值:")
result = np.mean(stus_score, axis=0)
print(result)
# 求每一行的平均值(1表示行)
print("每一行的平均值:")
result = np.mean(stus_score, axis=1)
print(result)- 方差std

stus_score = np.array([[80, 88], [82, 81], [84, 75], [86, 83], [75, 81]])
# 求每一行的方差(0表示列)
print("每一列的方差:")
result = np.std(stus_score, axis=0)
print(result)
# 求每一行的方差(1表示行)
print("每一行的方差:")
result = np.std(stus_score, axis=1)
print(result)数组运算
- 数组与数的运算

stus_score = np.array([[80, 88], [82, 81], [84, 75], [86, 83], [75, 81]])
print("加分前:")
print(stus_score)
# 为所有平时成绩都加5分
stus_score[:, 0] = stus_score[:, 0]+5
print("加分后:")
print(stus_score)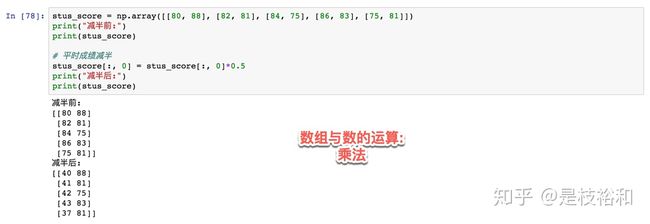
stus_score = np.array([[80, 88], [82, 81], [84, 75], [86, 83], [75, 81]])
print("减半前:")
print(stus_score)
# 平时成绩减半
stus_score[:, 0] = stus_score[:, 0]*0.5
print("减半后:")
print(stus_score)矩阵运算np.dot()(非常重要)

计算规则
(M行, N列) * (N行, Z列) = (M行, Z列)
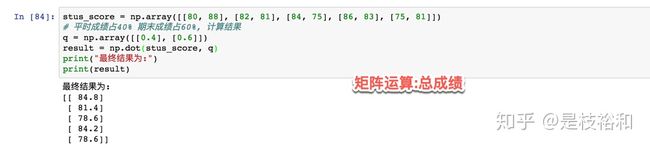
stus_score = np.array([[80, 88], [82, 81], [84, 75], [86, 83], [75, 81]])
# 平时成绩占40% 期末成绩占60%, 计算结果
q = np.array([[0.4], [0.6]])
result = np.dot(stus_score, q)
print("最终结果为:")
print(result)- 矩阵拼接
- 矩阵垂直拼接

print("v1为:")
v1 = [[0, 1, 2, 3, 4, 5],
[6, 7, 8, 9, 10, 11]]
print(v1)
print("v2为:")
v2 = [[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]]
print(v2)
# 垂直拼接
result = np.vstack((v1, v2))
print("v1和v2垂直拼接的结果为")
print(result)- 矩阵水平拼接

print("v1为:")
v1 = [[0, 1, 2, 3, 4, 5],
[6, 7, 8, 9, 10, 11]]
print(v1)
print("v2为:")
v2 = [[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]]
print(v2)
# 垂直拼接
result = np.hstack((v1, v2))
print("v1和v2水平拼接的结果为")
print(result)Numpy读取数据np.genfromtxt


如果数值据有无法识别的值出现,会以nan显示,nan相当于np.nan,为float类型.