RAG Fusion简明教程
随着 NLP 和生成 AI 领域的最新进展,RAG(检索增强生成)的引入有望通过结合基于检索的模型和序列到序列的强大功能,对 BERT Chat GPT 等现有技术进行改进。 架构。 RAG 是一个人工智能框架,旨在通过建立外部知识源模型来提供 LLM 的内部信息表示,从而提高 LLM 生成的响应的质量。
然而,由于 RAG 的一些缺点,它需要升级以实现其潜在的增强功能,这就是 RAG Fusion 的用武之地。让我们了解 RAG 和 RAG Fusion,它们都围绕着使用矢量搜索和生成式 AI 来彻底改变搜索和信息检索,以提供 基于真实数据的直接答案。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包
1、了解检索增强生成
检索增强生成(RAG)是一种将超大型预训练语言模型的功能与外部检索或搜索机制相结合的方法。 RAG 背后的想法是通过允许生成人工智能模型在生成过程中从大量文档中提取信息来增强生成人工智能模型的能力。
要了解 RAG 如何提高LLM即时响应生成的可信度,其工作原理如下:
- 检索步骤——当用户输入提示或向生成式 AI 模型提出问题时,RAG 模型会从大型语料库中检索一组相关文档或段落。 它是通过通常基于文档和查询的密集向量表示的检索机制来实现的。
- 生成步骤——检索到相关段落后,将其提供给生成式 AI 模型以及原始提示或查询。 该模型利用其预先训练的知识和从段落中检索到的信息来生成响应。
- 训练 - 在此阶段,检索和生成组件都在下游任务上进行端到端微调,并且模型可以根据生成的响应质量学习改进和增强其检索选择。

来源:AWS
上图阐明了 RAG 模型的机制,需要注意的是,增强提示的外部数据可以来自多个数据源,例如文档存储库、数据库或 API。 然而,关键的步骤是将文档转换为兼容的格式以执行相关性搜索。
使用嵌入语言模型将文档集合或知识库以及用户提交的查询转换为数字表示,以使格式兼容。 嵌入是在向量空间中为文本提供数字表示的过程。 RAG 模型架构比较用户查询在知识库向量中的嵌入,并提取具有相似上下文的文档。 下图代表了最原始的检索增强生成模型架构。
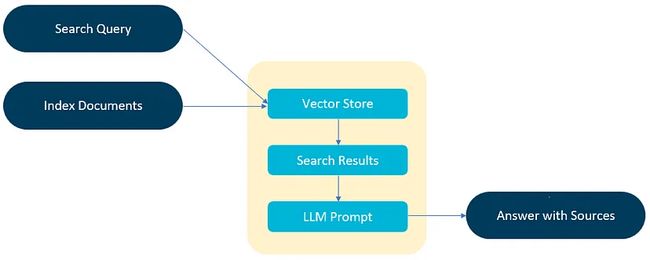
RAG架构
与单独工作的大型语言模型相比,RAG 具有显着的优势,可以生成最佳的即时响应。 以下是检索增强生成的一些好处:
- 使用最新的最新信息进行高质量响应。
- 更少的计算和存储
- 减少幻觉
尽管有很多优点,但 RAG 还存在一些需要解决的挑战,以确保答案符合道德事实和正确性:
- RAG 依赖于外部知识,并且可能由于不正确的信息而产生不准确的结果。
- 从外部资源获取数据可能会引发敏感数据的隐私和安全问题; 但是,使用文档级访问可以限制对特定文档的访问。
- 现有的搜索技术,如基于检索的词汇搜索技术和向量搜索技术,对RAG 模型造成了限制。
- 毫无疑问,人类在将所需内容写入搜索引擎时效率不高,拼写错误、模糊查询和有限词汇会导致错过顶级结果之外的大量信息。
- 线性范式缺乏深入了解人类查询本质的效率。 线性方法无法捕获复杂的用户查询,导致搜索结果效率低下。
2、RAG Fusion简介
RAG Fusion (Raudaschl, 2023) 提供了解决 RAG 模型局限性的最佳解决方案。 不同的限制,例如人工搜索效率低下和搜索过于简单化,会导致相关性较低的结果; 然而,借助 RAG Fusion,人们可以轻松克服这些限制。 它通过生成多个用户查询并使用倒数排名融合等策略对结果进行排名来克服挑战。 这种临时技术弥合了用户查询与其预期含义之间的差距。
RAG Fusion 技术使用编程语言、向量搜索数据库、具有查询生成功能的LLM以及结果重新排名步骤。 倒数排名融合 (RRF) 是一种数据重新排名技术,用于无缝组合不同查询的结果。 其目的是将搜索结果组织成统一的排名,提高相关信息的准确性。
为什么选择 RAG 融合?
开发 RAG 更新模型(即 RAG Fusion)背后的核心概念是理解复杂人类查询的细微差别,而不需要更高级的LLM。 RAG Fusion 通过生成多个查询并对结果重新排名,轻松解决 RAG 固有的约束。 此外,它还利用 RRF 和自定义向量评分加权来获得全面且准确的搜索结果。
它渴望弥合用户明确提出的问题和他们打算做的事情之间的差距,向揭示隐藏的变革性知识又近了一步。
RAG Fusions 使用与 RAG 相同的技术:Python 语言、矢量搜索数据库(如 Elasticsearch 或 Pinecone)以及大型语言模型(如 ChatGPT)。 RAG Fusion的工作方法与RAG相同; 但是,还有一些额外的步骤(例如查询生成和结果重新排名)可以改善响应质量。
它的工作原理如下:
- 通过LLM将用户的查询翻译成相似但不同的查询来执行查询重复
- 初始化原始查询及其生成的相似查询的向量搜索,多个查询生成。
- 使用RRF 合并并细化所有查询结果。
- 选择新查询的所有热门结果,为LLM提供足够的材料,以根据所有查询和重新排序的结果列表创建输出响应。
3、RAG Fusion 背后的复杂性 — RRF
RRF(即倒数排名融合)是一种围绕组合多个搜索结果以产生单个统一排名的技术。 单个查询无法涵盖用户查询的所有方面,并且可能过于狭窄而无法提供全面的结果; 这就是为什么多个查询生成必须考虑所有不同的元素并提供精心策划的答案。
RRF 的工作原理是结合不同搜索查询的排名,并增加所有相关文档出现在最终结果中的机会。 此外,它不依赖于搜索引擎分配的绝对分数,而是依赖于相对排名,因此将具有不同尺度或分数分布的结果组合起来变得实用。
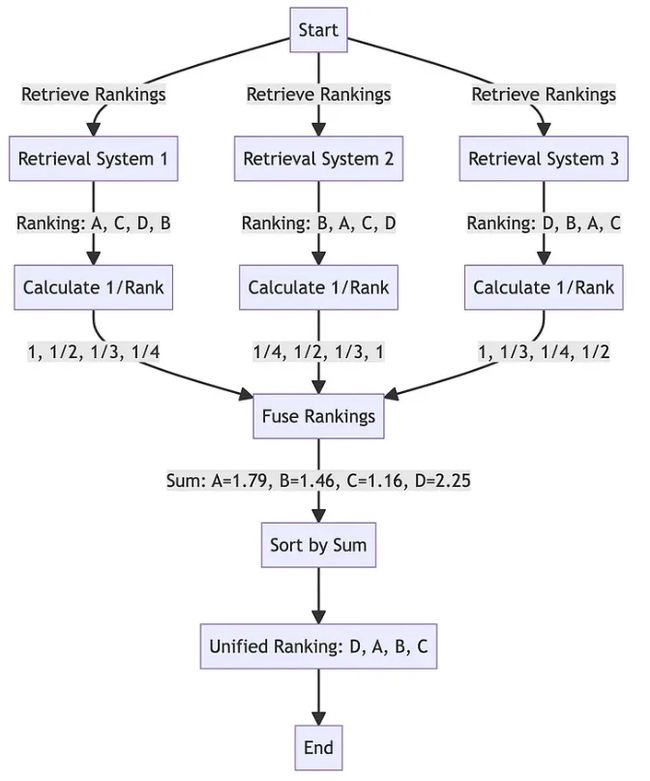
来源:: Adrian H. Raudaschl
上图由 Raudaschl,2023 年拍摄,代表了倒数排名融合位置重排名系统算法。 如图所示,函数 reciprocal_rank_fusion 接受一个搜索结果字典,其中每个键都是一个查询。 该键对应的值是一个文档 ID 列表,按其与查询的相似度进行排序。 RRF 算法根据每个文档在不同列表中的排名计算新分数,并对它们进行排序以创建最终的重新排名结果。
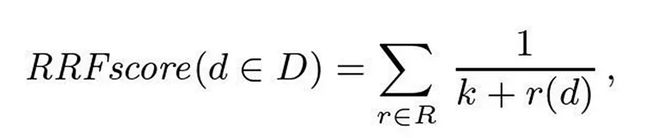
来源:Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods
RRF 根据简单的评分公式对文档进行排序。 上式中,集合D代表给定的待排序文档和一组排序R,每个排序都是1..|D|上的排列,k设置为60。
计算融合分数后,该函数根据分数对文档进行降序排序,并返回最终的重新排名列表。
为了确保多个查询不会偏离用户的意图,模型被指示在提示工程中给予原始查询比后续多个查询更多的权重。 重新排序的文档和查询将提供给 LLM,其工作原理与 RAG 类似,通过要求响应或摘要来生成生成输出。
4、RAG Fusion 的优缺点
与 RAG 模型相比,RAG Fusion 具有以下优势:
- 随着搜索深度的扩大,源材料的质量也会提高。
- 它提供与用户的输入查询产生共鸣的整体输出,以响应其信息需求的多方面表示。
- 它通过从不同文档中提取信息来创建组织良好且富有洞察力的答案。
- 它执行隐式拼写和语法检查并细化搜索查询以提供准确的搜索结果。
- 该系统充当语言催化剂,将复杂的查询分解为易于矢量搜索管理的小块。
- 它增加了发现用户无意的信息的可能性,但它很有帮助。
每一个强大的事物或算法都伴随着一系列限制,RAG Fusion 也不例外。 缺点只有两个:
- RAG Fusion 模型通过生成多个查询来达到查询深度的能力可以提供详细的答案,更像是一个过度解释的答案。
- 多查询输入和多样化的文档集会给语言模型的上下文窗口带来压力,导致输出不太连贯。
5、结束语
将 RAG Fusion 模型与 LLM(大语言模型)集成是一种创新方法,可以通过可靠的引用即兴做出即时反应。 RAG Fusion 轻松克服 RAG 模型的局限性并提高其性能。 Adrian H. Raudaschl 提出的 RAG Fusion 想法仍处于实验阶段,旨在使搜索更加智能和上下文感知,帮助获取手动或使用传统LLM无法找到的更丰富、更深入的信息层。 此外,一些道德问题与 RAG Fusion 相关,因为操纵用户的原始查询来改善结果可能就像步入道德灰色地带。 这就是为什么必须保持人工智能模型的透明性,并控制投入人工智能的数量和成本。
原文链接:RAG Fusion简明教程 - BimAnt