图像复原的天花板在哪里?SUPIR:开创性结合文本引导先验和模型规模扩大

SUPIR(Scaling-UP Image Restoration),这是一种开创性的图像复原方法,利用生成先验和模型扩大规模的力量。通过利用多模态技术和先进的生成先验,SUPIR在智能和逼真的图像复原方面取得了重大进展。作为SUPIR中的关键催化剂,模型的扩大规模显著增强了其能力,并展示了图像复原的新潜力。我们收集了包含2000万高分辨率、高质量图像的数据集用于模型训练,每个图像都附带有描述性文本注释。SUPIR具有通过文本提示引导图像复原的能力,扩展了其应用范围和潜力。此外,本文引入了负质量提示来进一步提高感知质量。此外还开发了一种基于恢复的采样方法,以抑制生成式恢复中遇到的保真度问题。实验证明了SUPIR在恢复效果上的卓越表现,以及通过文本提示操控恢复的新颖能力。
介绍
随着图像复原(IR)的发展,人们对IR结果的感知效果和智能性有了显著提升的期望。基于生成先验的IR方法利用强大的预训练生成模型引入高质量的生成和先验知识到IR中,在这些方面取得了显著的进展。持续增强生成先验的能力是实现更智能IR结果的关键,而模型扩大规模是一个重要且有效的方法。许多任务通过扩大规模已经取得了惊人的改进,例如SAM和大语言模型。这进一步激发了构建大规模、智能的IR模型的努力,该模型能够生成超高质量的图像。然而,由于工程约束,如计算资源、模型架构、训练数据以及生成模型和IR的协同作用,扩大IR模型的规模具有挑战性。
本文引入了SUPIR(Scaling-UP IR),这是有史以来最大的IR方法,旨在探索在视觉效果和智能方面的更大潜力。具体而言,SUPIR采用了StableDiffusion-XL(SDXL)作为强大的生成先验,其包含26亿参数。为了有效应用这个模型,本文设计并训练了一个包含超过6亿参数的适配器。此外,作者收集了超过2000万高质量、高分辨率的图像,充分发挥了模型扩大规模所带来的潜力。每个图像都附有详细的描述性文本,使得可以通过文本提示来控制恢复过程。还利用一个包含130亿参数的多模态语言模型,提供图像内容提示,极大地提高了方法的准确性和智能性。所提出的SUPIR模型在各种IR任务中表现出色,实现了最佳的视觉质量,特别是在复杂和具有挑战性的现实场景中。此外,该模型通过文本提示提供了对恢复过程的灵活控制,极大地拓宽了IR的可能性。下图1展示了模型的效果,展示了其卓越的性能。
本文的工作远不仅仅是简单的扩大规模。在追求模型规模增加的同时,面临着一系列复杂的挑战。首先,在应用SDXL进行IR时,现有的适配器设计要么过于简单无法满足IR的复杂需求,要么太大无法与SDXL一起训练。为了解决这个问题,修剪了ControlNet并设计了一个称为ZeroSFT的新连接器,以与预训练的SDXL一起高效实现IR任务,同时降低计算成本。为了增强模型准确解释低质量图像内容的能力,对图像编码器进行微调,提高其对图像降解变化的鲁棒性。这些措施使得模型的扩大规模变得可行和有效,并极大地提高了其稳定性。其次,收集了2000万张高质量、高分辨率的图像,附有详细的文本注释,为模型的训练提供了坚实的基础。采用了一种直观的策略,将质量较差的、负样本纳入训练中。通过这种方式,可以使用负质量提示来进一步提高视觉效果。结果显示,与仅使用高质量正样本相比,这种策略显著提高了图像质量。最后,强大的生成先验是一把双刃剑。不受控制的生成可能降低恢复的保真度,使得IR不再忠实于输入图像。为了缓解这个低保真度问题,提出了一种新颖的恢复引导采样方法。所有这些策略,再加上高效的工程实现,是使SUPIR扩大规模的关键,推动先进IR的边界。这种全面的方法,从模型架构到数据收集,将SUPIR置于图像复原技术的前沿,为未来的进步设定了新的基准。
相关工作
图像复原。IR的目标是将降级的图像转换为高质量且无降级的版本。在早期阶段,研究人员独立探索了不同类型的图像降级,如超分辨率(SR),降噪和去模糊。然而,这些方法通常基于特定的降级假设,因此缺乏对其他降级的泛化能力。随着时间的推移,对不基于特定降级假设的盲恢复方法的需求增长了。在这一趋势中,一些方法通过更复杂的降级模型来近似合成真实世界的降级,以处理单个模型的多个降级而闻名。最近的研究,如DiffBIR ,将不同的恢复问题统一到一个单一模型中。本文采用类似于DiffBIR的设置,使用单一模型来有效处理各种严重的降级。
生成先验。生成先验擅长捕捉图像的固有结构,使得可以生成遵循自然图像分布的图像。GANs的出现强调了生成先验在IR中的重要性。各种方法使用这些先验,包括GAN反演,GAN编码器,或将GAN作为IR的核心模块使用。除了GANs,其他生成模型也可以作为先验。本工作主要关注来自扩散模型的生成先验,这些模型在可控生成和模型扩大规模方面表现出色。扩散模型还已成功地用作IR中的生成先验。然而,这些基于扩散的IR方法的性能受制于所使用生成模型的规模,进一步提高其有效性面临挑战。
模型扩大规模是进一步提升深度学习模型能力的重要手段。最典型的例子包括语言模型的扩大规模,文本到图像生成模型的扩大规模和图像分割模型的扩大规模。这些模型的规模和复杂性大幅增加,拥有数十亿甚至上百亿的参数,但这些参数也带来了非凡的性能提升,展示了模型扩大规模的潜力。然而,扩大规模是一个系统性问题,涉及模型设计、数据收集、计算资源等多方面的限制。许多其他任务尚未能够享受到扩大规模带来的显著性能提升,图像复原就是其中之一。
方法
下图2展示了所提出的SUPIR方法的概览。将从三个方面介绍此方法:介绍本文的网络设计和训练方法;介绍训练数据的收集和文本模态的引入;介绍图像复原的扩散采样方法。

模型扩大规模
生成先验。在大规模生成模型的选择方面并没有太多选择。唯一可考虑的是Imagen、IF和SDXL。为什么选择SDXL?Imagen和IF优先考虑文本到图像的生成,并依赖于分层方法。它们首先生成小分辨率图像,然后分层上采样。SDXL直接生成高分辨率图像,没有分层设计,更符合我们的目标,因为它有效地利用其参数来提高图像质量而不是进行文本解释。此外,SDXL采用了一种基本-精炼策略。在基础模型中,生成多样但质量较低的图像。随后,精炼模型提高这些图像的感知质量。与基础模型相比,精炼模型使用质量更高但多样性较差的训练图像。考虑到我们使用大量高质量图像数据集进行训练的策略,SDXL的两阶段设计对我们的需求来说变得多余。选择基础模型,它有更多的参数,是生成先验的理想骨干。
降级鲁棒编码器。在SDXL中,扩散生成过程是在潜在空间中进行的。图像首先通过预训练的编码器映射到潜在空间。为了有效利用预训练的SDXL,低质量(LQ)图像也应映射到相同的潜在空间。然而,由于原始编码器未在低质量图像上进行训练,使用它进行编码会影响模型对低质量图像内容的判断,然后将伪影误认为图像内容。为此,微调编码器使其对降级具有鲁棒性,通过最小化:,其中是要微调的降级鲁棒编码器,D是固定的解码器,是真值。
大规模适配器设计。考虑到SDXL模型是我们选择的先验,需要一个适配器,可以引导它根据提供的低质输入来恢复图像。适配器需要识别LQ图像中的内容,并在像素级别精细控制生成。LoRA、T2I适配器和ControlNet是现有的扩散模型适应方法,但它们都不符合我们的要求:LoRA限制了生成,但在LQ图像控制方面存在问题;T2I缺乏有效的LQ图像内容识别能力;而ControlNet的直接复制对SDXL模型规模来说是具有挑战性的。为解决这个问题,我们设计了一个具有两个关键特性的新适配器,如下图3(a)所示。
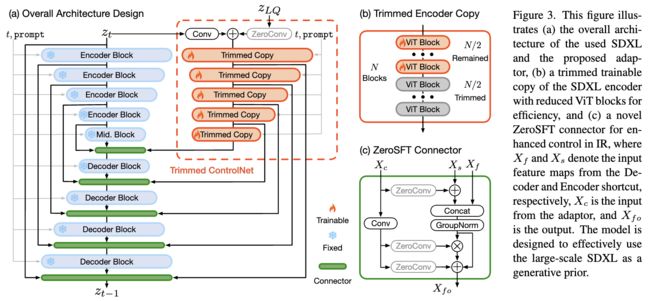
首先,保留ControlNet的高级设计,但采用网络裁剪来直接修剪可训练副本内的一些块,实现了一种可行的工程实现。SDXL的编码器模块内的每个块主要由几个Vision Transformer(ViT)块组成。确定了两个关键因素对ControlNet有效性的贡献:大型网络容量和可训练副本的高效初始化。值得注意的是,即使在可训练副本的块部分修剪的情况下,适配器仍保留这些关键特性。因此,简单地从每个编码器块中修剪一半的ViT块,如前面图3(b)所示。其次,重新设计连接器,将适配器连接到SDXL。虽然SDXL的生成能力提供了出色的视觉效果,但也使像素级的精确控制变得困难。ControlNet采用零卷积进行生成引导,但仅依赖残差对IR所需的控制来说是不足够的。为了放大LQ引导的影响,引入了一个ZeroSFT模块,如图3(c)所示。基于零卷积构建的ZeroSFT包括一个额外的空间特征传递(SFT)操作和组归一化。
数据规模的提升
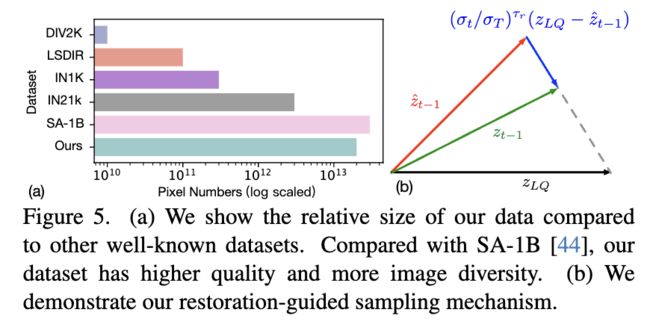
图像收集。模型的扩展需要相应扩展的训练数据。但是目前尚无大规模高质量的图像数据集可用于图像复原。尽管DIV2K和LSDIR提供了高质量的图像,但数量有限。像ImageNet(IN)、LAION-5B和SA-1B这样的更大数据集包含更多图像,但其图像质量不符合我们的高标准。为此,收集了一个新的大规模高分辨率图像数据集,其中包括2000万张1024×1024的高质量、纹理丰富且内容清晰的图像。图3显示了收集的数据集和现有数据集的规模比较。还从FFHQ-raw数据集中包含了额外的7万张不对齐的高分辨率人脸图像,以提高模型的人脸恢复性能。下图5(a)中显示了我们的数据相对于其他知名数据集的规模大小。
多模态语言引导。扩散模型以根据文本提示生成图像而闻名。我们认为文本提示也可以在图像复原中发挥重要作用,原因如下:
-
理解图像内容对图像复原至关重要。现有框架通常忽视或隐式处理这种理解。通过引入文本提示,明确地传达了对图像内容的理解,从而促进有针对性地恢复丢失的信息。
-
在严重降级的情况下,即使最好的图像复原模型也可能难以完全恢复丢失的信息。在这种情况下,文本提示可以作为一种控制机制,根据用户的喜好有针对性地完成缺失的信息。
-
还可以通过文本描述所需的图像质量,从而进一步提高输出的感知质量。有关一些示例,请参见图1(b)。
为此,我们进行了两个主要修改。首先,修改了整体框架,将LLaVA多模态大语言模型纳入pipeline,如图2所示。LLaVA以降级鲁棒处理的低质图像为输入,并明确了图像中的内容,以文本描述的形式输出。然后使用这些描述作为提示来引导恢复。这个过程在测试期间可以自动完成,无需手动干预。其次,遵循PixART 的方法,还为所有训练图像收集了文本注释,以加强文本控制在模型训练期间的作用。这两个变化赋予了SUPIR理解图像内容并根据文本提示恢复图像的能力。
负质量样本和提示。无分类器引导(CFG)通过使用负提示来指定模型的不希望的内容,提供了另一种控制方式。我们可以使用这个功能来指定模型不要生成低质量的图像。具体来说,在扩散的每个步骤中,将使用正提示pos和负提示neg进行两次预测,并将这两个结果的融合作为最终输出:
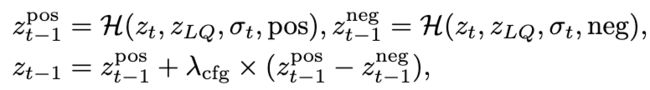
在这里,H(·)表示带有适配器的扩散模型,是时间步骤t的噪声方差,是一个超参数。在我们的框架中,pos可以是具有图像质量积极词汇的图像描述,而neg是具有负面词汇的图像描述,例如“油画,卡通,模糊,脏,凌乱,低质量,变形,低分辨率,过度平滑”。对于CFG技术,准确预测正和负对于其很关键。然而,在我们的训练数据中缺少负面质量的样本和提示可能导致SUPIR在理解负面提示方面失败。因此,在采样过程中使用负面质量的提示可能会引入伪影,参见下图4的示例。为解决这个问题,使用SDXL生成了与负面质量提示相对应的10万张图像。以反直觉的方式将这些低质量图像添加到训练数据中,以确保SUPIR模型能够学习负面质量的概念。

强大的生成先验是一把双刃剑,因为过多的生成能力反过来会影响恢复图像的保真度。这突显了图像复原任务和生成任务之间的根本区别。需要一种方法来限制生成,以确保图像复原忠实于低质量(LQ)图像。修改了EDM采样方法,提出了一种以恢复为导向的采样方法来解决这个问题。我们希望在每个扩散步骤中有选择地引导预测结果接近LQ图像。具体的算法如Algorithm 1所示,其中T是总步数,是T步的噪声方差,c是附加的文本提示条件。 是五个超参数,但只有与恢复引导有关,其他参数与原始的EDM方法相比保持不变。为了更好地理解,图5(b)中显示了一个简单的图表。在预测输出和LQ潜在之间执行加权插值,作为恢复引导输出。由于图像的低频信息主要是在扩散预测的早期阶段生成的(此时t和相对较大,权重也较大),因此预测结果更接近以增强保真度。在扩散预测的后期阶段,主要生成高频细节。此时不应有太多的约束,以确保可以充分生成细节和纹理。此时,t和相对较小,权重k也较小。因此,预测结果不会受到很大的影响。通过这种方法,可以在扩散采样过程中控制生成,以确保保真度。
实验
模型训练和采样设置
在训练过程中,整体训练数据包括2000万张高质量图像,带有文本描述,7万张人脸图像以及10万个负质量样本和相应的负提示。为了使用更大的批量大小,在训练过程中将它们裁剪成512×512的patch。我们使用合成降级模型进行模型训练,遵循Real-ESRGAN的设置,唯一的区别是我们将生成的低质量(LQ)图像调整大小为512×512进行训练。使用AdamW优化器,学习率为0.00001。训练过程历时10天,使用64个Nvidia A6000 GPU,并使用256的批量大小。在测试过程中,超参数设置为T=100,=7.5,=4。方法能够处理尺寸为1024×1024的图像。将输入图像的短边调整为1024,并在测试时裁剪出1024×1024的子图像,然后在恢复后将其调整回原始大小。除非另有说明,否则不会手动提供提示-处理将完全自动进行。
与现有方法的比较
我们的方法能够处理各种降级,并与具有相同能力的最先进方法进行比较,包括BSRGAN、Real-ESRGAN、StableSR、DiffBIR和PASD。其中一些受限于生成512×512大小的图像。在比较中,我们裁剪测试图像以满足此要求,并将我们的结果降采样以便进行公平比较。
合成数据。为了为测试合成LQ图像,遵循以前的工作[45, 97],在几种代表性的降级上展示我们的效果,包括单一降级和复杂混合降级。具体细节可以在表1中找到。选择了以下指标进行量化比较:全参考指标PSNR、SSIM、LPIPS和非参考指标ManIQA、ClipIQA、MUSIQ。可以看到,我们的方法在所有非参考指标上都取得了最佳结果,这反映了我们结果的卓越图像质量。同时,也注意到我们的方法在全参考指标上的劣势。我们进行了一个简单的实验,突显了这些全参考指标的局限性,见图7。可以看到我们的结果在视觉效果上更好,但在这些指标上并没有优势。这种现象在许多研究中也被注意到[6, 26, 28]。我们认为随着IR质量的提高,有必要重新考虑现有指标的参考值,并提出更有效的方法来评估先进的IR方法。我们还在图6中展示了一些定性比较结果。即使在严重降级的情况下,我们的方法始终产生高度合理且高质量的图像,忠实地表现了LQ图像的内容。
真实图像修复。还在真实世界的低质量(LQ)图像上测试了我们的方法。从RealSR、DRealSR、Real47以及在线来源中总共收集了60张真实世界的LQ图像,包含了各种内容,包括动物、植物、人脸、建筑和风景。在下图10中展示了定性结果,定量结果显示在下表2a中。
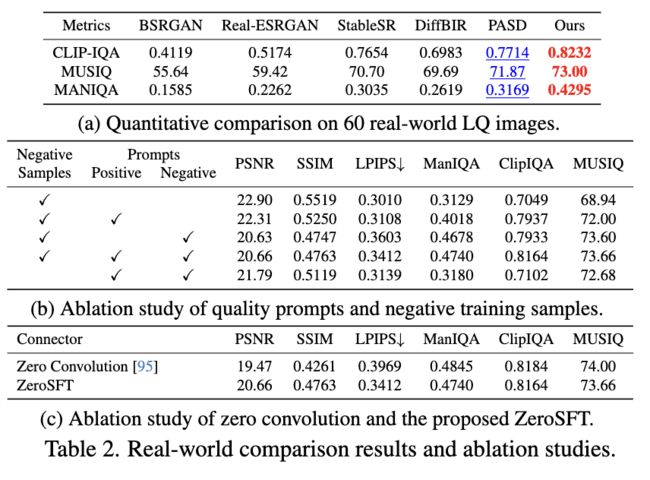
这些结果表明,我们的方法生成的图像在感知质量上表现最佳。还进行了一个用户研究,比较了我们的方法在真实世界LQ图像上的效果,共有20名参与者。对于每组比较图像,我们要求参与者选择这些测试方法中感知质量最高的修复结果。结果显示在图8中,表明我们的方法在感知质量上明显优于最先进的方法。
通过在大量图像-文本对的数据集上进行训练,并利用扩散模型的特性,我们的方法可以根据人类提示有选择性地进行图像修复。前面图1(b)展示了一些示例。在第一种情况下,没有提示的情况下,自行车的修复是具有挑战性的,但在接收到提示后,模型可以准确地重建它。在第二种情况下,可以通过提示调整帽子的材质纹理。在第三种情况下,即使是高级语义提示也可以操控面部属性。除了提示图像内容,还可以通过负面质量提示来提示模型生成更高质量的图像。下图11(a)展示了两个示例。

可以看出,负面提示在提高输出图像的整体质量方面非常有效。还观察到,在我们的方法中,提示并不总是有效的。当提供的提示与LQ图像不符合时,提示会变得无效,参见上面图11(b)。对于一个IR方法而言,保持对提供的LQ图像的忠实是合理的。这反映了与文本到图像生成模型的显著区别,并强调了我们方法的鲁棒性。
消融研究
连接器。 将提出的ZeroSFT连接器与零卷积进行比较。定量结果显示在表2c中。与ZeroSFT相比,零卷积在非参考度量上表现相当,但在全参考性能上要低得多。在图9中,发现非参考指标的下降是由生成低保真内容引起的。因此,对于IR任务,ZeroSFT确保了保真度而不丧失感知效果。
训练数据扩展。在两个较小的IR数据集DIV2K和LSDIR上训练了我们的大型模型。定性结果显示在下图12中,清楚地展示了在大规模高质量数据上进行训练的重要性和必要性。

负质量样本和提示。前面表2b显示了在不同设置下的一些定量结果。在这里,使用描述图像质量的积极词语作为“正面提示”,并使用负面质量词语以及前面描述的CFG方法作为负面提示。可以看出,单独使用积极提示或负面提示可以提高图像的感知质量。同时使用它们可以产生最佳感知结果。如果在训练中没有包含负样本,这两个提示将无法提高感知质量。前面图4和图11(a)展示了使用负面提示带来的图像质量改善。
修复引导抽样方法。所提出的修复引导抽样方法主要由超参数控制。越大,每个步骤对生成的更正越少。越小,将迫使更多的生成内容更接近LQ图像。请参考下图13进行定性比较。

当 = 0.5时,图像因其输出受到LQ图像的限制而模糊,并且无法生成纹理和细节。当 = 6时,在生成过程中几乎没有指导。模型生成了很多在LQ图像中不存在的纹理,特别是在平坦区域。下图8(a)说明了根据变量 的定量恢复结果。如图8(a)所示,将 从6减小到4不会导致视觉质量显著下降,而保真性能得到改善。
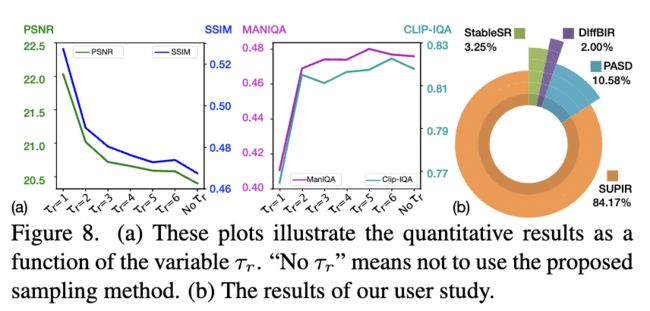
随着修复引导的不断加强,尽管PSNR不断提高,图像逐渐变得模糊,失去了细节,如前面图13所示。因此,选择 = 4作为默认参数,因为它在有效增强保真度的同时并不显著影响图像质量。
结论
本文提出了SUPIR作为一种开创性的图像复原方法,通过模型扩展、数据集丰富和先进的设计特性,拓展了图像复原的视野,提高了感知质量并控制了文本提示。
效果展示








参考文献
[1] Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild
文献链接:https://arxiv.org/pdf/2401.13627
项目链接:https://supir.xpixel.group/
更多精彩内容,请关注公众号:AI生成未来
