【AAAI 2021】Document-Level RE with Adaptive Thresholding and Localized Context Pooling
【AAAI 2021】Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling

论文:https://ojs.aaai.org/index.php/AAAI/article/view/17717
代码: https://github.com/wzhouad/ATLOP
Abstract
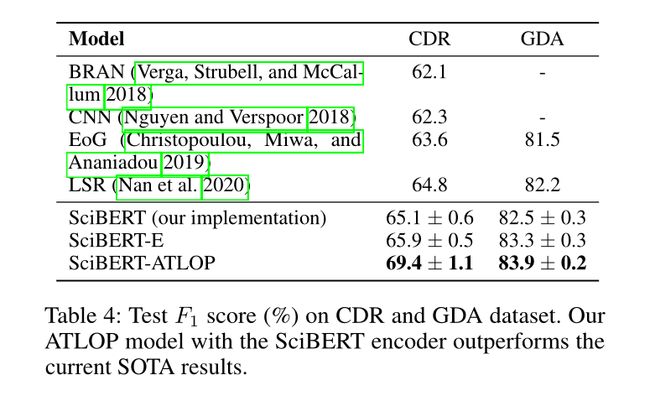
与句子级关系提取相比,文档级关系提取提出了新的挑战。一个文档通常包含多个实体对,并且一个实体对在与多个可能关系相关联的文档中多次出现。在本文中,我们提出了两种新的技术,自适应阈值和局部上下文池化,来解决多标签和多实体问题。自适应阈值化用可学习的实体相关阈值代替了先前工作中用于多标签分类的全局阈值。本地化的上下文池化直接将注意力从预先训练的语言模型转移到定位有助于确定关系的相关上下文。我们在三个文档级RE基准数据集上进行了实验:最近发布的大规模RE数据集DocRED,以及生物医学领域的两个数据集CDR和GDA。我们的ATLOP模型在DocRED的F1得分为63.4,在CDR和GDA方面也显著优于现有模型。
Introduction

文档级关系抽取和句子级关系抽取的对比:句子级关系抽取:一个句子仅包含一个实体对需要分类;文档级关系抽取:一个文档包含多个实体对,我们需要同时对它们之间的关系进行分类。它要求RE模型识别并关注具有特定实体对的相关上下文的文档部分。此外,一个实体对可以在与文档级别RE的不同关系相关联的文档中多次出现,与句子级别RE的每个实体对一个关系形成对比。文档级关系提取的这种多实体(要在文档中分类的多个实体对)和多标签(特定实体对的多个关系类型)特性使其比句子级的对应项更难提取。图1很好地展示了文档级关系抽取的困难。
然而,由于基于Transformer的模型可以隐式地对长距离依赖性进行建模,尚不清楚图结构是否仍有助于预训练的语言模型(如BERT)。也有一些方法可以在不引入图结构的情况下直接应用预训练的语言模型。他们简单地对实体标记的嵌入进行平均以获得实体嵌入,并将其输入分类器以获得关系标签。然而,每个实体在不同的实体对中都有相同的表示,这可能会带来来自无关上下文的噪声。
在本文中,我们提出了一种本地化的上下文池技术,而不是引入图结构。该技术解决了对所有实体对使用相同实体嵌入的问题。它通过与当前实体对相关的附加上下文来增强实体嵌入。我们没有从头开始训练新的上下文注意力层,而是直接从预训练的语言模型中转移注意力头来获得实体级的注意力。然后,对于一对中的两个实体,我们通过乘法将它们的注意力合并,以找到对它们都重要的上下文。
对于多标签问题,现有的方法将其简化为二分类问题。在训练之后,将全局阈值应用于类概率以获得关系标签。该方法涉及启发式阈值调整,并在来自验证数据的调整阈值可能不是所有实例的最优阈值时引入决策错误。
在本文中,我们提出了自适应阈值技术,用可学习的阈值类代替全局阈值。阈值类是用我们的自适应阈值损失来学习的,这是一种基于秩的损失,在模型训练中,它将正类的logits推到阈值之上,并将负类的logit拉到阈值之下。在测试时,我们返回logits高于阈值类的类作为预测标签,或者如果不存在此类,则返回NA。这种技术消除了对阈值调整的需要,并且还使阈值可针对不同的实体对进行调整,从而获得更好的结果。
本文的主要贡献:
- 我们提出了自适应阈值损失,这使得能够学习依赖于实体对的自适应阈值,并减少了使用全局阈值引起的决策误差。
- 我们提出了本地化的上下文池化技术,它将预训练的注意力转移到抓取实体对的相关上下文,以获得更好的实体表示。
- 我们在三个公共文档级别的关系提取数据集上进行了实验。实验结果证明了我们的TLOP模型的有效性,该模型在三个基准数据集上实现了最先进的性能。
Problem Formulation
给出一个文档 d d d和一系列的实体 { e i } i = 1 n \{ e_i \}_{i=1}^n {ei}i=1n,文档级关系抽取的任务是预测所有实体对 ( e s , e o ) s , o = 1 … n ; s ≠ o (e_s,e_o)_{s,o=1 \dots n;s \ne o} (es,eo)s,o=1…n;s=o存在的关系 R ∪ { N A } \mathcal{R} \cup \{ NA \} R∪{NA}。一个实体 e i e_i ei可能通过提及 { m j i } j = 1 N e i \{ m_j^i \}_{j=1}^{N_{e_i}} {mji}j=1Nei在文档中出现多次。如果实体对 ( e s , e o ) (e_s,e_o) (es,eo)之间的关系通过它们的任何一对提及来表达,那么它就存在。不表达任何关系的实体对被标记为NA。在测试时,模型需要预测文档 d d d中所有实体对 ( e s , e o ) s , o = 1 … n ; s ≠ o (e_s,e_o)_{s,o=1 \dots n;s \ne o} (es,eo)s,o=1…n;s=o。
Enhanced BERT Baseline
Encoder
给出一个文档 d = [ x t ] t = 1 l d=[x_t]_{t=1}^l d=[xt]t=1l,我们在所有实体提及的开始和末尾都加上*,然后将其输入到预训练语言模型中来获得去上下文嵌入:
H = [ h 1 , h 2 , … , h l ] = BERT ( [ x 1 , x 2 , … , x l ] ) H=[h_1,h_2,\dots,h_l]=\text{BERT}([x_1,x_2,\dots,x_l]) H=[h1,h2,…,hl]=BERT([x1,x2,…,xl])
根据之前的工作,文档由编码器编码一次,所有实体对的分类都基于相同的上下文嵌入。我们将“*”在提及开始处的嵌入作为提及嵌入。对于一个实体 e i e_i ei带有提及 { m j i } j = 1 N e i \{ m_j^i \} _{j=1}^{N_{e_i}} {mji}j=1Nei,我们使用logsumexp池化,一个最大池化的平滑版本,来获取实体的嵌入 h e i h_{e_i} hei:
h e i = log ∑ j = 1 N e i exp ( h m j i ) h_{e_i}=\log \sum_{j=1}^{N_{e_i}} \exp (h_{m_j^i}) hei=logj=1∑Neiexp(hmji)
Binary Classifier
我们将实体映射到具有线性层的隐藏状态 z z z,然后进行非线性激活,然后通过双线性函数和sigmoid激活计算关系 r r r的概率。此过程的公式为:
z s = tanh ( W s h e s ) , z o = tanh ( W o h e o ) , P ( r ∣ e s , e o ) = σ ( z s ⊤ W r z o + b r ) z_s=\tanh (W_s h_{e_s}),\\ z_o=\tanh(W_oh_{e_o}),\\ P(r|e_s,e_o)=\sigma(z_s^ {\top} W_r z_o +b_r) zs=tanh(Wshes),zo=tanh(Woheo),P(r∣es,eo)=σ(zs⊤Wrzo+br)
W , b W,b W,b是模型参数。一个实体的表示在不同的实体对之间是相同的。为了减少双线性分类器中的参数数量,我们使用群双线性,它将嵌入维度划分为 k k k个大小相等的群,并在群内应用双线性:
[ z s 1 ; … ; z s k ] = z s , [ z o 1 ; … ; z o k ] = z o , P ( r ∣ e s , e o ) = σ ( ∑ i = 1 k z s ⊤ W r i z o + b r ) [z_s^1;\dots;z_s^k]=z_s,\\ [z_o^1;\dots;z_o^k]=z_o,\\ P(r|e_s,e_o)=\sigma( \sum_{i=1}^k z_s^ {\top} W_r^i z_o +b_r) [zs1;…;zsk]=zs,[zo1;…;zok]=zo,P(r∣es,eo)=σ(i=1∑kzs⊤Wrizo+br)
P ( r ∣ e s , e o ) P(r|e_s,e_o) P(r∣es,eo)是关系 r r r与实体对 e s , e o e_s,e_o es,eo相关联的概率。通过这种方式,我们可以将参数的数量从d2减少到d2/k。我们使用二分类交叉熵损失进行训练。在推理过程中,我们调整全局阈值 θ θ θ,该阈值使开发集上的评估度量(RE的F1score)最大化,并且如果 P ( r ∣ e s , e o ) > θ P(r|e_s,e_o)>\theta P(r∣es,eo)>θ,则返回 r r r作为相关关系,如果不存在关系,则返回NA。
我们的增强基础模型在实验中实现了接近最先进的性能,显著优于现有的BERT基线。
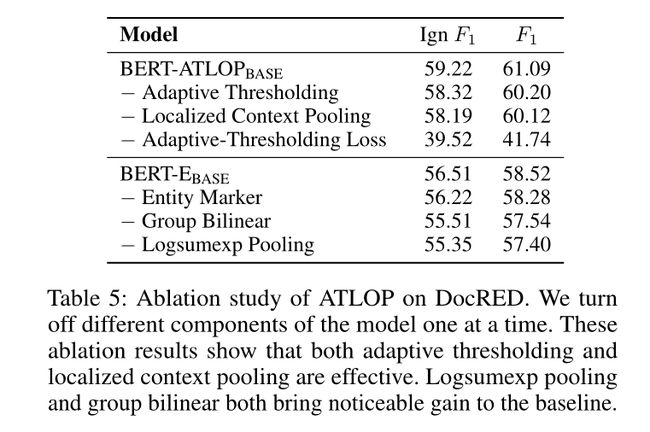
Adaptive Thresholding
RE分类器输出范围[0,1]内的概率 P ( r ∣ e s , e o ) P(r|e_s,e_o) P(r∣es,eo),其需要阈值化以转换为关系标签。由于阈值既没有闭合形式的解,也不可微,因此决定阈值的常见做法是枚举范围(0,1)中的几个值,并选择使评估度量最大的值(RE的F1分数)。然而,对于不同的实体对或类,模型可能具有不同的置信度,其中一个全局阈值是不够的。关系的数量不同(多标签问题),并且模型可能不会被全局校准,因此相同的概率并不意味着所有实体对都相同。这个问题促使我们用可学习的自适应阈值来代替全局阈值,这可以减少推理过程中的决策错误。
为了便于解释,我们将实体对 T = ( e s , e o ) T=(e_s,e_o) T=(es,eo)的标签划分为两个子集:正类 P T P_T PT和负类 N T N_T NT,定义如下:
- 正类 P T ∈ R P_T \in \mathcal{R} PT∈R是实体 T T T中存在的关系。如果 T T T不能展现出任何关系,那么 P T P_T PT就是空。
- 负类 N T ∈ R N_T \in R NT∈R是实体间不存在的关系,如果 T T T不能展示出嗯嗯和关系, N T = R N_T=\mathcal{R} NT=R。

如果实体对分类正确,则正类的logits应高于阈值,而负类的logit应低于阈值。在这里,我们引入了一个阈值类TH,它以与其他类相同的方式自动学习(见等式(5))。在测试时,我们将logits比TH类更高的类作为正类返回,或者如果不存在此类类,则返回NA。该阈值类学习实体相关的阈值。它是全局阈值的替代品,因此无需在验证集上调整阈值。
为了学习新模型,我们需要一个考虑TH类的特殊损失函数。我们在标准分类交叉熵损失的基础上设计了自适应阈值损失。损失函数分为两部分,如下所示:
L 1 = − ∑ r ∈ P T log ( exp ( logit r ) ∑ r ′ ∈ P T ∪ { T H } exp ( logit r ′ ) ) , L 2 = − log ( exp ( logit T H ) ∑ r ′ ∈ N T ∪ { T H } exp ( logit r ′ ) ) , L = L 1 + L 2 . \begin{aligned} \mathcal{L}_{1} & =-\sum_{r \in \mathcal{P}_{T}} \log \left(\frac{\exp \left(\operatorname{logit}_{r}\right)}{\sum_{r^{\prime} \in \mathcal{P}_{T} \cup\{\mathrm{TH}\}} \exp \left(\operatorname{logit}_{r^{\prime}}\right)}\right), \\ \mathcal{L}_{2} & =-\log \left(\frac{\exp \left(\operatorname{logit}_{\mathrm{TH}}\right)}{\sum_{r^{\prime} \in \mathcal{N}_{T} \cup\{\mathrm{TH}\}} \exp \left(\operatorname{logit}_{r^{\prime}}\right)}\right), \\ \mathcal{L} & =\mathcal{L}_{1}+\mathcal{L}_{2} . \end{aligned} L1L2L=−r∈PT∑log(∑r′∈PT∪{TH}exp(logitr′)exp(logitr)),=−log(∑r′∈NT∪{TH}exp(logitr′)exp(logitTH)),=L1+L2.
第一部分 L 1 L_1 L1涉及正类和TH类。由于可能存在多个正类,因此总损失计算为所有正类的分类交叉熵损失之和。 L 1 L_1 L1将所有正类的logits推至高于TH类。如果没有阳性标签,则不使用。第二部分 L 2 L_2 L2涉及负类和阈值类。它是以TH类为真标签的范畴交叉熵损失。它拉负类的logits低于TH类。将两部分简单地相加作为总损失。
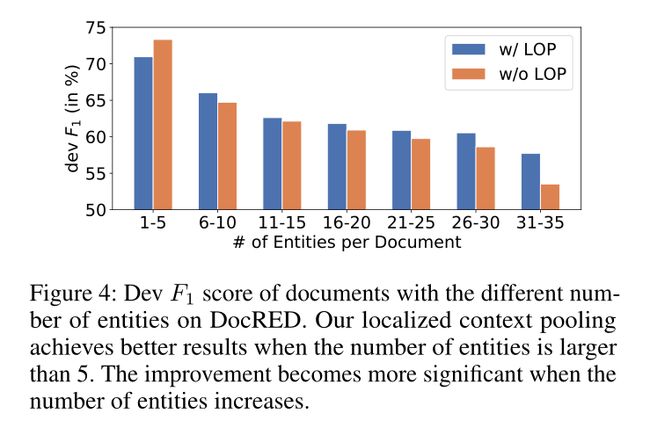
Localized Context Polling

然后,在所有实体对的分类中使用来自该文档级全局池化的实体嵌入。然而,对于实体对,实体的某些上下文可能不相关。例如,在图1中,第二次提到John Stanistreet及其上下文与实体对无关(John Stanisteet,Bendigo)。因此,最好有一个只关注文档中相关上下文的本地池化表示,这有助于决定此实体对的关系。
因此,我们提出了局部上下文池化,其中我们通过与两个实体相关的额外局部上下文嵌入来增强实体对的嵌入。在这项工作中,由于我们使用预训练的基于Transformer的模型作为编码器,该模型已经通过多头自注意学习了token级依赖性,我们考虑直接使用它们的注意头进行本地化上下文池化。这种方法从预训练的语言模型中迁移了学习良好的依赖关系,而无需从头开始学习新的注意力层。
具体来说,给定一个预训练的多头注意力矩阵 A ∈ R H × l × l A\in \mathbb{R}^{H\times l \times l} A∈RH×l×l,其中 A i j k A_{ijk} Aijk表示第 i i i个注意力头中从token j j j到token k k k的注意力,我们首先将“*”符号的注意力作为提及级别的注意力,然后对同一实体的提及上的注意力进行平均,得到实体级别的注意力 A i E ∈ R H × l A_i^E \in \mathbb{R}^{H \times l} AiE∈RH×l,其表示第 i i i个实体对所有token的关注。然后,给定一个实体对 ( e s , e o ) (e_s,e_o) (es,eo),我们通过乘以实体级注意力来定位对 e s e_s es和 e o e_o eo都重要的局部上下文,并通过以下公式获得局部上下文嵌入 c s , o c^{s,o} cs,o:
A ( s , o ) = A s E ⋅ A o E , q ( s , o ) = ∑ i = 1 H A i ( s , o ) , a ( s , o ) = q ( s , o ) / 1 ⊤ q ( s , o ) , c ( s , o ) = H ⊤ a ( s , o ) A^{(s,o)}=A_s^E \cdot A_o^E,\\ q^{(s,o)}=\sum_{i=1}^{H} A_{i}^{(s,o)},\\ a^{(s,o)}=q^{(s,o)}/1^{\top}q^{(s,o)},\\ c^{(s,o)}=H^{\top}a^{(s,o)} A(s,o)=AsE⋅AoE,q(s,o)=i=1∑HAi(s,o),a(s,o)=q(s,o)/1⊤q(s,o),c(s,o)=H⊤a(s,o)
H H H是上下文嵌入,然后将本地化的上下文嵌入融合到全局池化实体嵌入目的去获取实体表示,对于不同的实体对,通过修改原始线性层而有所不同。
z s ( s , o ) = tanh ( W s h e s + W c 1 c ( s , o ) ) z o ( s , o ) = tanh ( W o h e o + W c 2 c ( s , o ) ) \begin{array}{l} \boldsymbol{z}_{s}^{(s, o)}=\tanh \left(\boldsymbol{W}_{s} \boldsymbol{h}_{e_{s}}+\boldsymbol{W}_{c_{1}} \boldsymbol{c}^{(s, o)}\right) \\ \boldsymbol{z}_{o}^{(s, o)}=\tanh \left(\boldsymbol{W}_{o} \boldsymbol{h}_{e_{o}}+\boldsymbol{W}_{c_{2}} \boldsymbol{c}^{(s, o)}\right) \end{array} zs(s,o)=tanh(Wshes+Wc1c(s,o))zo(s,o)=tanh(Woheo+Wc2c(s,o))
Experiments



Conclusion
在这项工作中,我们提出了一种用于文档级关系提取的ATLOP模型,该模型具有两种新技术:自适应阈值和局部上下文池化。自适应阈值技术用一个可学习的阈值类来代替多标签分类中的全局阈值,该阈值类可以为每个实体对确定最佳阈值。本地化上下文池化利用预训练的注意力头来定位实体对的相关上下文,从而有助于缓解多实体问题。在三个公共文档级关系提取数据集上的实验表明,我们的ATLOP模型显著优于现有模型,并在所有数据集上产生了最先进的新结果。