Hadoop:学习HDFS,看完这篇就够了!
HDFS(Hadoop Distributed File System)是Apache Hadoop生态系统中的分布式文件系统,用于存储和处理大规模数据集。由于其具有高容错性、高可靠性和高吞吐量等特点,因此广泛应用于大数据处理和分析场景。

一 认识Hadoop
学习HDFS之前,让我们先来简单认识一下Hadoop是什么?
Hadoop 是 Apache 软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。Hadoop是基于Java语言开发的,具有很好的跨平台性,可以部署在廉价的计算机集群中。Hadoop具有如下特性:
- 高可靠性:采用冗余数据存储方式,即使一个副本发生故障,其他副本也可以保证正常对外服务;
- 高效性:作为并行分布式计算平台,Hadoop采用分布式存储和分布式处理两大核心技术,可以高效处理BP级数据;
- 高可扩展性:Hadoop可以高效稳定地运行在廉价的计算机集群上,可以扩展到数以千计的计算机节点上;
- 高容错性:采用冗余数据存储方式,自动保存数据的多个副本,并能自动将失败的任务进行重新分配;
- 成本低:Hadoop采用廉价的计算机集群,成本低,普通用户也很容易用自己的PC搭建Hadoop运行环境;
- 运行在Linux系统上:Hadoop是基于Java语言开发的 ,可以较好地运行在Linux平台上;
- 支持多种编程语言:Hadoop上的应用程序也可以用其 他语言编写,如C/C++,Python等。
Hadoop生态系统包括:
HDFS(分布式文件系统)、HBase(列式数据库)、MapReuduce(编程模型)、Hive(数据仓库)、Pig(数据流语言和编程环境)、Mahout(算法实现)、ZooKeeper(构建分布式应用)、Flume(日志采集管理)、Sqoop(数据交换)、Ambari(Hadoop集群安装、部署、配置、管理)
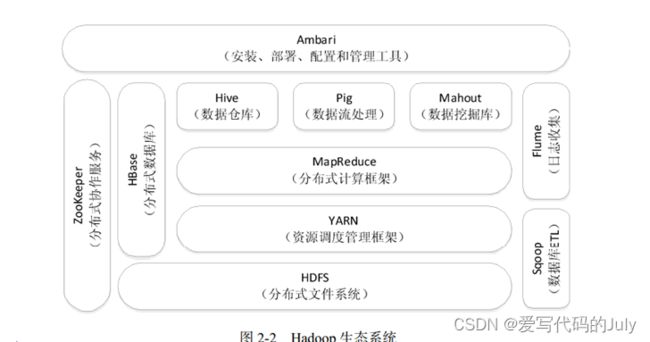
(参考资料来源于《大数据技术原理与应用》(林子雨)一书)
Hadoop的核心之一就是我们今天要学习的分布式文件系统HDFS了。
关于Hadoop的更多内容,这里就不一一说明了,Hadoop环境搭建也较为复杂,感兴趣的朋友可以自行查阅资料。如果是单纯学习的话,这里推荐章章鱼大数据 (ipieuvre.com)线上平台,这里可以满足我们学习云计算的各种需要,还有很多的课程及教程,省去了我们搭建环境的苦恼。(如果有朋友想在自己的电脑上搭建,需要安装包也可以找我获取~)
二 分布式文件系统HDFS
好了,接下来让我们进入正题,首先先来认识一下什么是“分布式文件系统”?简单来说,分布式文件系统就是把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群。 HDFS采用主/从(Mater/Slave)体系结构,由计算机集群中的多个节点构成,这些节点分为两类,一类叫“主节点”(Master Node)或者也被称为“名称结点”(NameNode), 另一类叫“从节点”(Slave Node)或者也被称为“数据节点”(DataNode)。顾名思义,主节点就是用来存储元数据的,负责管理分布式文件系统的命名空间,而从节点或者说数据节点就是用来存储和读取数据的。理论上讲,主节点有且只有一个(HDFS1.0即是如此),而从节点数量不定,可以有无限多个。但是随着数据量的增大,在名称节点运行期间,EditLog文件将会变得很大,导致名称节点启动操作非常慢,因此又衍生出了第二名称节点(SecondaryNameNode)。第二名称节点同样是HDFS架构中的一个组成部分,它用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间,一般单独运行在一台机器上。
HDFS同样采用了“块”的概念,以块为单位进行读写,默认一块为64MB。与我们平时所了解的“块”相同,其主要作用是为了分摊磁盘读写开销,不同的是其大小要比普通文件系统的块大很多。
HDFS是一个部署在集群上的分布式文件系统,因此,很多数据需要通过网络进行传输。所有的HDFS通信协议都是构建在TCP/IP协议基础之上的。 客户端通过一个可配置的端口向名称节点主动发起TCP连接,并使用客户端协议与名称节点进行交互。 名称节点和数据节点之间则使用数据节点协议进行交互。 客户端与数据节点的交互是通过RPC(Remote Procedure Call)来实现的。
简单介绍了HDFS的体系结构,接下来让我们分析一下这种结构有何优劣呢?由于整个体系结构中,只有一个名称节点,只有一个命名空间,因此其无法对不同的应用程序进行隔离,也就是隔离性较差,此外一旦该节点发生故障,那么整个集群就不可用了,即集群的可用性得不到保障。而名称节点又保存在内存中,因此其存储内容的量也会受到我们内存空间大小的限制。最后就是性能上的问题了,整个分布式文件系统的吞吐量,都受到名称节点吞吐量的限制,带来了性能瓶颈。
HDFS采用冗余数据存储策略(这个我们上面也有提到过),保证了系统的容错性和可用性,通常数据会以多副本的方式分布到不同的数据节点上,加快了数据传输速度,也容易检查出数据错误,更重要的是保证了数据的可靠性(比较多个副本同时出错的概率太低了)。
一般数据至少会被保存3份,分别存放在放置在上传文件的数据节点、与第一个副本不同的机架的节点、与第一个副本相同机架的其他节点上,保证了无论数据本身出现问题,换算数据所在机架出现问题,都不影响数据的可靠性。HDFS还提供了一个API,可以确定一个数据节点所属的机架ID,客户端也可以调用 API获取自己所属的机架ID。 当客户端读取数据时,从名称节点获得数据块不同副本的存放位置列表,列表中包含了副本所在的数据节点,可以调用API来确定客户端和这些数据节点所属的机架ID,当发现某个数据块副本对应的机架ID和客户端对应的机架ID相同时,就优先选择该副本读取数据,如果没有发现,就随机选择一个副本读取数据。
最后分享一个我之前看到过的漫画解读HDFS读写机制。

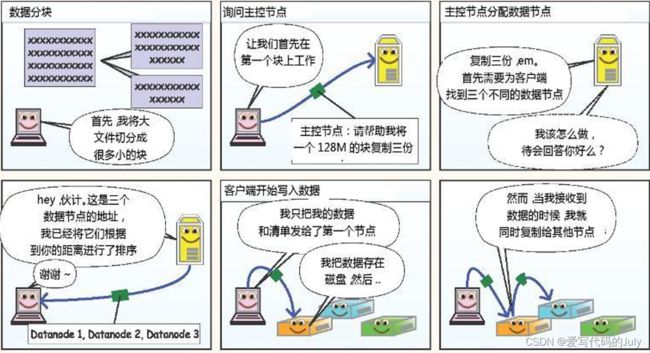
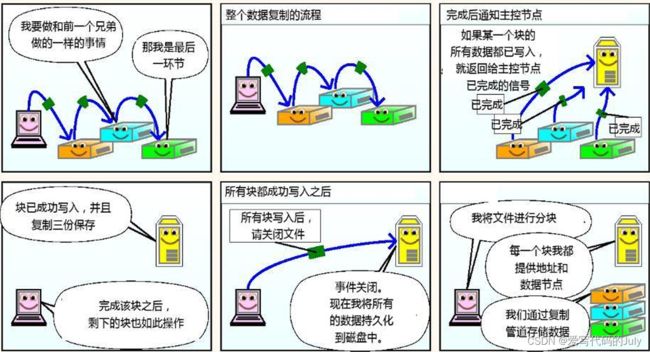

详细内容可以参考:Hadoop学习笔记(三)漫画解读HDFS读写原理_hdfs读写流程漫画中文翻译-CSDN博客
三 HDFS常用命令
HDFS shell的基本命令语法如下:
hdfs dfs -<命令> [选项] <参数>HDFS大多数命令都与Linux命令相同,只是加上了hdfs dfs或hadoop fs这个前缀。以下简单列举一些常用命令:
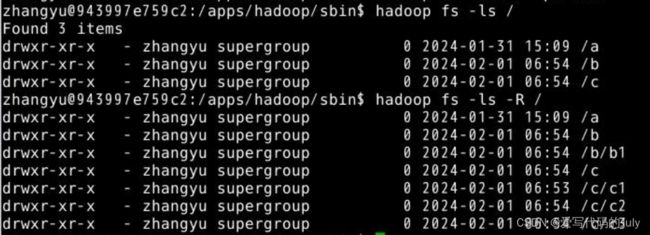
1.ls:查看当前目录下所有文件
参数 -R 表示递归查看该路径下的所有文件
如查看根目录下的所有文件:
如果使用的是上面提到过的章鱼大数据平台,那么也可以通过在浏览器中输入:localhost:50070 实现文件可视化
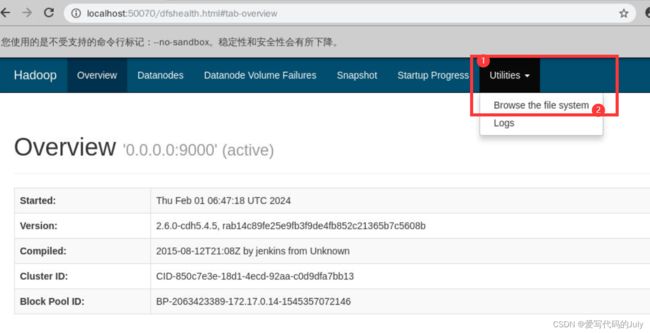
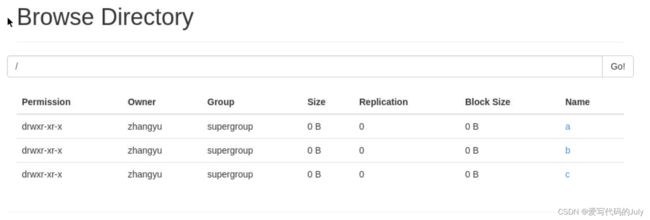
分别点击上图中的1、2位置,即可看到根目录下所有文件
2.mkdir:创建一个新的目录
参数 -p 表示创建连级目录
如在当前目录下创建文件夹test和test2,并在test2文件夹下创建联级文件夹t:
![]()
目录创建完成后不会有新的提示,可以通过ls命令查看结果
3.mv:移动文件或目录
如将刚刚创建的文件夹t移动到a文件夹下,并更名为t1:

4.rm:删除HDFS中的文件或目录
参数 -p 表示创建连级目录
如删除刚刚创建的test2文件夹:

5.put:将本地文件或目录上传到HDFS。
如果使用的是章鱼大数据平台,则需要先将文件从真机中上传到虚拟机。
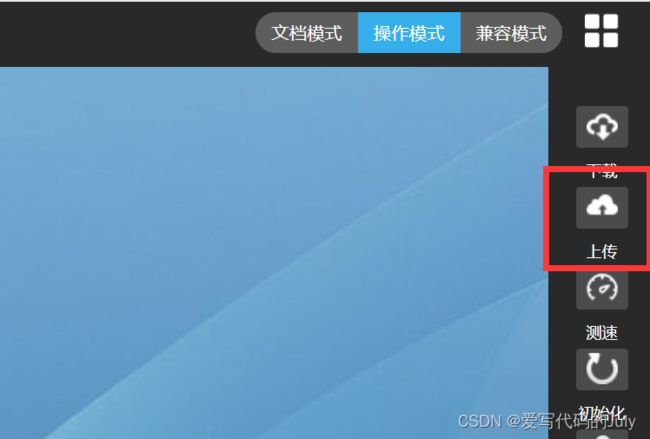
点击工具栏里的上传即可上传文件。文件会自动上传到/home/zhangyu路径下:

如将我们的test.txt文件上传到文件夹b下:

6.get:从HDFS下载文件或目录到本地文件系统
如将文件夹b下的b1目录下载到虚拟机中:

7.chmod:更改文件或目录的权限
chown:更改文件或目录的所有者
chgrp:更改文件或目录的所属组
如赋予test文件所有用户所有权限:

对比其之前的权限,可以看到权限已经更改成功。

8.cat:查看文件的内容

9.du:显示文件大小
参数 -s 表示显示当前目录或者文件夹的大小
![]()
10.copyFromLocal 复制本地文件到HDFS
copyToLocal 复制HDFS文件到本地系统
这两个命令和put/get命令类似,区别在于目标路径必须是本地文件
以上就是对HDFS的简单介绍了,接下来还会分享这部分的相关习题和练习,需要备战期末的同学们可以先收藏起来~当然如果要深入学习HDFS,仅仅了解这些是不够的,还需要进一步的学,这里推荐b站上的课程:
千锋好程序员大数据全新分布式存储HDFS精品课程_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1bG411A7qk/?spm_id_from=333.337.search-card.all.click&vd_source=209879771cd07d6dc85c0a82b27b2898这位老师的讲解深入浅出,从因到果,非常适合新手小白学习~
https://www.bilibili.com/video/BV1bG411A7qk/?spm_id_from=333.337.search-card.all.click&vd_source=209879771cd07d6dc85c0a82b27b2898这位老师的讲解深入浅出,从因到果,非常适合新手小白学习~