「微服务网关实战三」详细理解 SCG 路由、断言与过滤器
又来给大家更文了。
本篇带给大家的是 SpringCloudGateway (下文简称 SCG)的各种断言与过滤器的讲解,由于在上一篇文章中我们已经使用过了断言与过滤器,但是一直没有对其进行大篇幅叙述,这可能会导致部分读者并不知道网关都具有哪些内置功能,所以本篇就是为了带大家全面的认识一下各种各样的断言以及过滤器,让大家在使用 SCG 做项目的时候更加明白:哪些功能需要自己做,哪些功能框架已经自带,避免重复造轮子,减少开发成本。
先赞后看,养成习惯,相信我的文章一定会让大家有所收获,废话不多说,开始了~
1. 路由
在使用 SCG 时,你要记住它的基本使用单位是路由,不是断言,也不是过滤器,断言和过滤器都只是路由的组成部分,所有的请求都是进入到路由中,然后根据路由的规则进行处理的。
在第一篇的时候,我曾经用过 SCG 官网的一张架构图,你可以用它再来做一个理解:
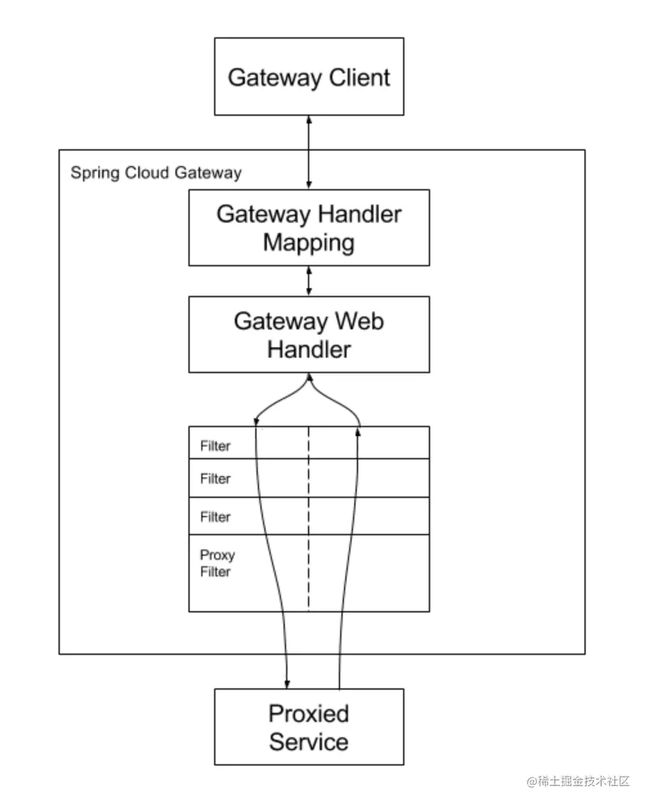
你可以将这张图看作 SCG 的一个路由,根据路由的断言它可以找到要请求的服务,然后在请求这个服务之前会先经过这个路由上的一堆过滤器,最终才是到达目标服务。
然而一个 SCG 肯定会有多个路由,而且很多情况下这些路由断言是有可能重复的,比如 /a 和 /** 这两个断言其实是重复的,这个时候我们还需要一个东西来标识谁在前,谁在后,那么路由里面除了断言和过滤器之外肯定还会有一个权重的概念,用它来处理断言重复情况下的优先级问题。
扯了这么多,我们已经知道一个路由必备的几个东西:断言、过滤器、代理服务、权重,那么接下来我们就看看 SCG 对于路由这个模型定义的数据结构 - RouteDefinition 吧:
/**
* @author Spencer Gibb
*/
@Validated
public class RouteDefinition {
// 唯一id
private String id;
@NotEmpty
@Valid
// 断言
private List predicates = new ArrayList<>();
@Valid
// 过滤器
private List filters = new ArrayList<>();
@NotNull
// 代理服务
private URI uri;
// 元数据
private Map metadata = new HashMap<>();
// 权重
private int order = 0;
}
复制代码 基本上和我们列举的分毫不差,就是多了一个用于区分路由的id,毕竟路由信息也是存储在内存中的一个 Map,如果没有一个唯一标识那是不行的,而且还多了一个 metadata,用于标识路由元数据,这个东西我们一般用不到,所以也不必关心。
我们在配置路由的时候其实就是配置这些数据,我们来看一下上篇文章中的一个例子:
@Bean
public RouteLocator routeLocator(RouteLocatorBuilder builder) {
return builder.routes()
.route((r) -> r.path("/user/**").uri("lb://user-api"))
.route((r) -> r.path("/order/**").uri("lb://order-api"))
.build();
}
复制代码很明显这个配置 Bean 使用了建造者模式,这里的每一个 router 方法的参数里面装着的都是一个路由,但是可以发现我们在使用的时候并没有配置 id、过滤器和权重,这是因为在你不填的情况下它会默认帮你生成一个 UUID,而权重则默认是0,至于过滤器是真的非必填项,你通过上面的 RouteDefinition 也可以看出,过滤器上面并没有标识 NotEmpty,所以它其实是可有可无的。
所以在使用 SCG 的时候,路由到底是什么样的一定要做到心中有数。
路由就像摆在请求面前的多条路,一个请求只能选择一个路由,而且选择之后就不可避免的要受到过滤器(如果有的话)的处理,才能抵达目标服务,目标服务进行响应之后该请求会顺着原路返回,而且也会不可避免的再经过一遍原来的过滤器,再受到过滤器的一遍处理,最终才能返回给请求端,所以在上面的 SCG 图例中,请求在回来的时候也画出了会经过过滤器。
不过 SCG 的内置过滤器在设计的时候一般只会处理一个方向,也就是这个过滤器要么处理进来的请求,要么处理响应的请求。
2. 断言
断言是一个路由的必填项,它指导了什么样的请求会经过这个路由。
在之前的处理中,我只使用了一个 Path 断言,实际上在 SCG 有太多好用的内置断言,截止到目前的 3.1.3 版本,SCG 内置了 14 种断言方式(官网文档只列出了 12 种),它们分别是:
After:根据请求时间进行断言,接收一个时间参数,只有此时间之后的请求可以通过。Before:根据请求时间进行断言,接收一个时间参数,只有此时间之前的请求可以通过。Between:根据请求时间进行断言,接收两个时间参数,只有在这两个时间段之内的请求可以通过。Cookie:根据 Cookie 数据进行断言,接收两个参数 name 和 reg,name 代表 Cookie 中的一个键值对的key,reg 则代表对其值的匹配,当一个请求的 name 属性中的值符合 reg 参数的正则表达式时,该请求会被通过。Header:根据请求头数据进行断言,接收两个参数 header 和 reg,header 代表请求头集合中的某个请求头,reg 则代表对其值的匹配,当一个请求头中的 header 中的值符合 reg 参数的正则表达式时,该请求会被通过。Host:根据请求中的 Host 属性进行匹配,接收一个 Ant 风格的匹配参数列表,当请求中的 Host 属性符合任一规则时,该请求会被通过。Method:根据请求 method 进行匹配,接收一个 method 枚举数组,当请求的 Method 在此数组列表中时,该请求会被通过。Path:根据请求的 url 进行匹配,接收两个参数 patterns 和 matchTrailingSlash,patterns 代表请求的匹配规则(数组),matchTrailingSlash 则代表是否兼容反斜杠,默认是兼容的,比如 /a 和 /a/,当请求的 url 符合 patterns 规则时,该请求会被通过。Query:根据请求的查询参数进行匹配,接收两个参数 param 和 reg,param 代表参数的名字,reg 则代表对此参数值的匹配,当一个请求携带 param 参数,且其值符合 reg 参数的正则表达式时,该请求会被通过。RemoteAddr:根据请求的远程地址进行匹配,接收一个CIDR表示法的参数,当请求的远程地址符合这个规则时,该请求会被通过。Weight:根据路由设置的权重进行分发,一般此断言需要两个及以上的路由搭配进行使用,它有两个参数 group 和 weight,两个路由都使用 Weight 断言,设置一样的 group,然后设置不同的权重,进行将流量根据权重分发到不同的路由中。XForwardedRemoteAddr:根据请求的 X-forward 列表进行匹配,接收一个CIDR表示法的字符串列表,当请求的远程地址符合任意一个规则时,该请求会被通过。ReadBodyRoute(官网未列出):根据请求的 body 参数进行匹配,接收两个参数 inClass 和 predicate,inClass 代表 body 数据类型,predicate 则是自定义 Predicate 的 Bean 名字,没错这个断言需要你自定义一个 Predicate(Java 8 四大函数式接口之一),SCG 帮你所做的就是把请求的 body 参数取出来,然后你使用自定义断言去匹配,匹配通过该请求就会被通过。CloudFoundryRouteServiceRoute(官网未列出):这个是支持 cloudfoundry 平台的一个扩展,实现比较简单,在 Header 断言的基础上添加了三个请求头规则,不必深究。
SCG 的断言都有一个共同的抽象类——AbstractRoutePredicateFactory,如果你的 SCG 版本比我的更高,想要了解有哪些新的断言类,可以直接去看它有哪些实现类,如果你打算自定义一个断言,也可以直接去查看上文中的任意一个断言类的源码进行仿写。
3. 过滤器概览
过滤器是一个路由的非必填项,它指导了请求经过路由时会经过哪些处理。
在 SCG 中,过滤器在概念上可以分为:网关过滤器、默认过滤器和全局过滤器。
网关过滤器是 GatewayFilter 接口的实现类,而默认过滤器则是一个配置,它可以将配置的网关过滤器添加到所有路由上去,比如你在网关上配置了如下配置:
spring:
cloud:
gateway:
default-filters:
- PrefixPath=/httpbin
复制代码同时你具有路由1、路由2 和路由3 这三个路由,他们各自配置了1、2、3个过滤器,这时网关启动之后就会把路由1、路由2、路由3 也添加上 PrefixPath 这个过滤器,那么这三个路由实际上存在的过滤器就是2、3、4个。
全局过滤器是 GlobalFilter 接口的实现类,它和网关过滤器接口 GatewayFilter 的方法签名是一模一样的,但是既然它们的名字不一样那么使用场景也必然不一样,网关过滤器需要配合某个路由进行使用,而全局过滤器是作用于所有路由上。
所以网关过滤器和全局过滤器都会作用于路由上,它们会共同形成一个过滤器链,就像这样:
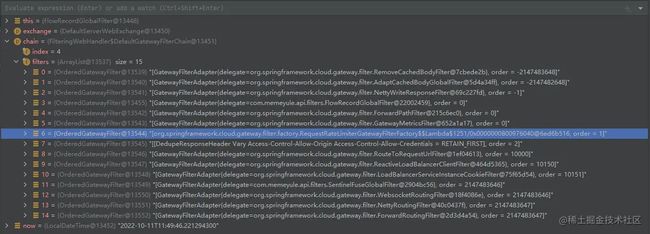
从上图中可以看到过滤器的名字,凡是以 GatewayFilterAdapter 开头的都是全局过滤器,反之则是网关过滤器,GatewayFilterAdapter 在这里起到一个包装的作用,将 GlobalFilter 包装成 GatewayFilter。
从图中还可以注意到过滤器链中的过滤器都有一个顺序字段 - Order,整个过滤器链的顺序是以 Order 字段来排序的,所有的 GlobalFilter 都会实现一个 Order 接口用于排序,Order 越小越靠前。
但是网关过滤器并没有实现 Order 接口,所以在组合全局过滤器和网关过滤器的时候会通过网关过滤器的加载顺序从 0 开始为网关过滤器进行 Order 赋值,所以可以看到网关过滤器都是在中间的,因为它的顺序从 0 开始。
经过这么一个流程后,请求就会经过过滤器链上的所有的过滤器,当然某些过滤器具有拦截请求的功能,它可以让请求提前停止,比如限流、熔断,经过之后在目标服务得到响应之后响应会再次经过这个过滤器链,直至返回给发送方。
4. 网关过滤器
接下来是网关过滤器,截止到现在3.1.3版本,它一共有 33 个实现类,由于实现类实在太多,我们就选择10个比较常用且重要的进行讲解:
AddRequestHeader: 传入一个 name 和一个 value,将此键值对添加为请求上的一个 header。AddRequestParameter: 传入一个 name 和一个 value,将此键值对添加为请求上的一个查询参数。AddResponseHeader: 传入一个 name 和一个 value,将此键值对添加为响应上的一个 header。DedupeResponseHeader: 传入请求头枚举和一个重复请求头处理策略(默认为保留第一个),可以去除这个请求头的重复头,多用于CROS中,在浏览器跨域处理中如果你的响应返回了重复的跨域头,浏览器会给出报错。CircuitBreaker:这个是用于 resilience4j 的熔断器处理,并且需要引入spring-cloud-starter-circuitbreaker-reactor-resilience4j依赖。PrefixPath: 传入一个参数作为请求截断的前缀,比如你的微服务是靠路径进行转发的,/order-api 开头的请求都转发到 order 服务,但是你的 order 服务的请求并不是以 /order-api 开头而是以 /order 开头,这个时候你可以把你所有原来的请求都加上 /order-api 前缀,这个过滤器自动帮你把 /order-api 截断,只保留后面的 URL,这对某些没有加入网关的老旧服务非常有用。- RequestRateLimiter: 用于限流的过滤器,需要引入
spring-boot-starter-data-redis-reactive,由于此过滤器参数较多且复杂留在后文详细说明。 RemoveRequestHeader: 传入一个请求头参数,删除此请求头。RemoveResponseHeader: 传入一个请求头参数,删除此响应中的请求头。StripPrefix:传入一个数字,代表去除多少个前缀,比如一个请求的 URI 为 /a/b/c,传入 1 之后得到的就是 /b/c,传入 2 之后得到的就是 /c,PrefixPath是靠字符串匹配截断而此过滤器是靠对 URI 分段进行截断。
剩下的过滤器的文档在这里,有需要的可以自行查看,如需自定义网关过滤器,实现 GatewayFilter 即可,但是如果你想要一个带配置的网关过滤器,可以按照 AddRequestHeaderGatewayFilterFactory 这个类的实现进行仿写,需要先实现一个继承 AbstractGatewayFilterFactory 的配置抽象类,然后再用网关过滤器去实现这个配置抽象类,你就可以得到一个带有配置的网关过滤器了。
5. 全局过滤器
接下来是全局过滤器,截止到现在3.1.3版本,全局过滤器一共有 14 个实现类,官网只标注了 8 个,经我查看实现后觉得比较重要的也就是官网标注的那些,所以我们主要说一下官网所标注的 8 个全局过滤器:
1. Custom
public class CustomGlobalFilter implements GlobalFilter, Ordered {
@Override
public Mono filter(ServerWebExchange exchange, GatewayFilterChain chain) {
log.info("custom global filter");
return chain.filter(exchange);
}
@Override
public int getOrder() {
return -1;
}
}
复制代码 准确来说这并不是一个过滤器,而是一个全局过滤器的示例,如果你要自定义一个全局过滤器,除了实现 GlobalFilter 接口之外还要实现 Ordered 接口,Ordered 接口会为你的过滤器设置一个 Order 值,SCG 中的所有全局过滤器都会实现这两个接口,根据 Order 值的大小来决定过滤器的先后顺序,Order 数值越小,过滤器越靠前。
2. ForwardRoutingFilter
此过滤器是用来转发本地请求的,它的 order 值是 Integer.MAX_VALUE,这代表它是在整个过滤器链的最后方。
我们在路由上配置 URI 属性的时候可以配置多种 scheme 比如 http、lb 和 forward,这个过滤器就是用来处理 forward 类型请求的,当你在 URI 配置了此类型的转发之后,此过滤器会使用 Spring 的 dispatcherHandler 转发这个请求。
3. ReactiveLoadBalancerClientFilter
此过滤器是为了负载均衡而使用的,它的核心代码较为简单:
private Mono> choose(Request lbRequest, String serviceId,
Set supportedLifecycleProcessors) {
ReactorLoadBalancer loadBalancer = this.clientFactory.getInstance(serviceId,
ReactorServiceInstanceLoadBalancer.class);
if (loadBalancer == null) {
throw new NotFoundException("No loadbalancer available for " + serviceId);
}
supportedLifecycleProcessors.forEach(lifecycle -> lifecycle.onStart(lbRequest));
return loadBalancer.choose(lbRequest);
}
复制代码 通过一个 ReactorLoadBalancer 子类去拿到调用服务的某个实例信息,所以负载均衡中进行实例选择的工作是 ReactorLoadBalancer 在做,这里默认使用 RoundRobinLoadBalancer 进行选择,它使用的是轮询方案,如果你开启了 Nacos 的负载均衡则会使用 NacosLoadBalancer 进行实例的选择,它使用随机+权重的方案。
4. NettyRoutingFilter
它的 order 值也是 Integer.MAX_VALUE,这代表它是在整个过滤器链的最后方,它的主要作用是用于发送 http/ https 请求,请求发送成功之后会把响应的数据存储在 ServerWebExchange 中,以待后面的过滤器使用。
5. NettyWriteResponseFilter
它的 order 值是 -1,在 SCG 的老版本中,它的优先级是最高的,所以在处理响应的时候它是最后一个被处理,它的主要任务就是将 NettyRoutingFilter 存储下来的响应数据发送给请求客户端。
6. RouteToRequestUrlFilter
它的主要作用是将请求 URL 和路由的 URI 属性拼接起来,比如你的请求URL是 gw.com/abc,匹配到的路由 URI 是 lb://order-api,最终你的请求就会变成 lb://order-api/abc,然后也会将这个值放在 ServerWebExchange 中,以待后方的过滤器使用。
7. WebsocketRoutingFilter
它用来处理 WS 请求路由。
8. GatewayMetricsFilter
它主要来用统计网关性能,使用之前需要添加 spring-boot-starter-actuator 作为项目依赖,接着将配置中的 spring.cloud.gateway.metrics.enabled 设置为 true 即可。它可以和 Grafana 组合使用,形成可视化监控。
5. 最后
本篇主要的重点是对路由概念的认识,至于其他过滤器和断言的相关叙述则是为了更好的让大家理解路由这个概念里面都包含了什么,以及在真正使用的时候我们都可以借助内置的哪些功能帮助我们处理业务上的问题。
本篇没有技术点相关的更新,下一篇将带大家详细了解一下在 SCG 中,如果借助内置的限流器做一个网关限流。
最后,如果大家觉得本文还不错的话就可以点赞以示支持,对内容有什么疑问也可以在评论区,我会积极对线的,下篇见。