深度学习之循环神经网络进阶
这一讲我们学习如何实现一个循环神经网络的分类器:
我们要解决的问题是名字分类,我们根据名字找到其对应的国家。
上一讲我们介绍了循环神经网络。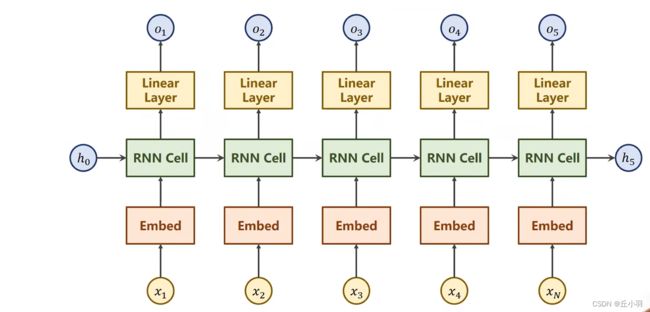
我们在处理自然语言的时候我们通常是以上这种方式,我们在处理单词的时候,通常都要先将其转化为one-hot独热向量。但是独热向量维度太高,而且过于稀疏,所以一般来说我们都要先经过嵌入层将其转化为一个低维稠密的向量,然后经过循环神经网络,RNN一层,隐层的输出不一定与我们要求的目标一致,然后我们再经过线性层将其转化到与我们目标一致。
其实可以用更简单的可视化图表示过程:
下面来看我们今天所学的内容:
我们首先将输入经过嵌入层转化为低维稠密的输出,然后经过GRU层得到输出,再经过线性层转化为我们的目标输出。在我们的例子里面就是18维(数据中包含18个国家)。
我们先对我们的数据进行分析。
以第一个输入麦卡伦为例。我们的输入其实是一个序列,Maclean,其中的每一个字符都是我们序列里面的x1,x2,x3,以此类推。所以我们这里面看起来输入只是一个名字,一个字段,其实它是一个字段,而且我们的序列长度并不统一。有的序列长,有的序列短。我们在处理序列问题的时候,经常遇到的一种情况就是我们在处理序列问题的时候长短不一。
接下来我们来看我们的模型的处理过程。
首先我们来看数据上的准备,我们拿到的是一些字符串,第一件事我们需要将其转化为一个序列。其中每一个元素都是名字之中的一个字符。
接下来我们做词典,用英文字符做词典其实还是比较好做的,用ASCII码表做词典,ASCII码表里面一共有128个字符,我们去求每一个字符对应的ASCII码值,将该值的序列拼成一个序列。这样我们就将其转化成一个数字序列了。
很显然,77并不是说M的值是77,实际上对应的是一个独热向量,这个独热向量有128维,除了第77个元素是1之外,其余所有元素都是0。但是我们对于嵌入层来说,我们只需要告诉我们的Emdeding层,第几个维度是1就行了。
解决完这个问题之后呢,我们还注意到一个问题,这些序列长短不一,而我们的处理层要求维度一致,这个时候需要我们对我们的序列进行统一处理,将其进行扩维(padding),都转化为该序列组中的最高维度,空缺 的部分添加0补上。(因为我们的输入是(Sqlen,batch,input ,output))。要求必须是一个矩阵。张量必须保证所有的元素都要填满。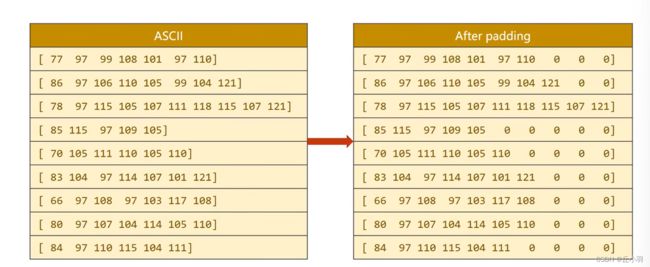
这样我们就构成了一个张量。
对我们的名字做完处理之后,接下来就是对国家做处理,首先我们需要对国家做分类索引。
代码就先不分析
下面我们来分析双向神经网络,先看我们原本的神经网络。
我们把x1和h0放进来,做线性变换和激活,然后将结果传递到下一项。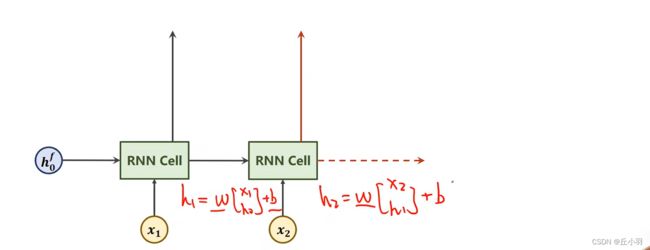
接下来按照这个顺序不停的走,然后我们就将隐层和输出都算出来了。
显然得到的结果只考虑过去的信息,(结果包含前面的各种信息)。而实际上有时候我们在自然语言里面我们要考虑未来的信息,就是说以后会发生的事情对它造成的影响。双向的循环神经网络是指什么呢?
我们的Forward是沿着序列的方向走一遍,还有一种backward是反过来算。
当然这个Forward和backward是指序列的正方向和反方向,要和梯度下降里面的Forward和backward区分开,后者是指梯度传播方向。
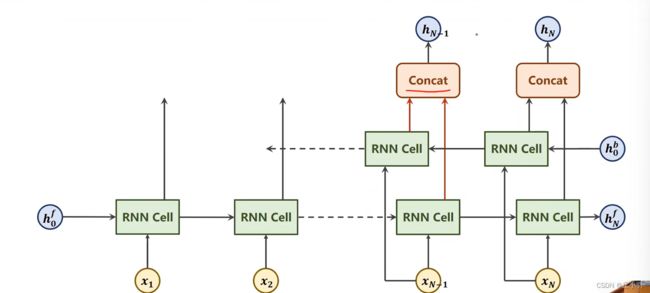
我们将正向和反向的输出拼接起来。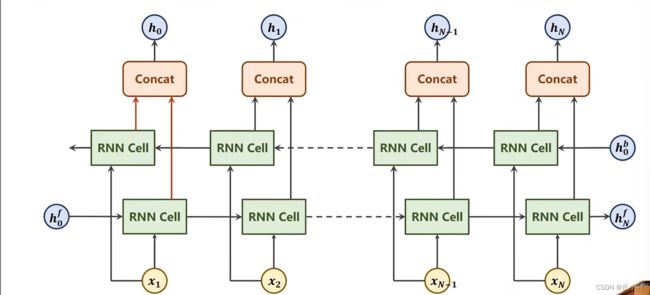
我们得到的最终的循环网络叫做双向循环神经网络。我们隐层的输出使用红圈圈起来。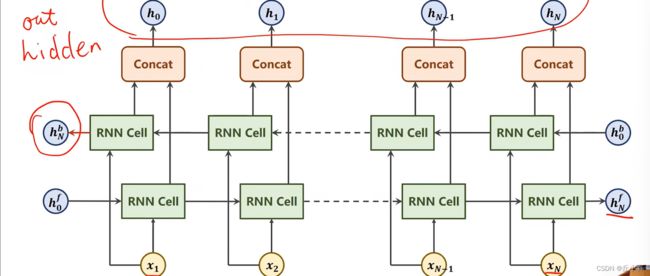
当然我们最终的输出包含两部分,一是hidden(用红圈圈住),另一个就是隐层输出output。


所以双向循环网络输出的隐层每一个hn的维度是单向的两倍。
嵌入过程: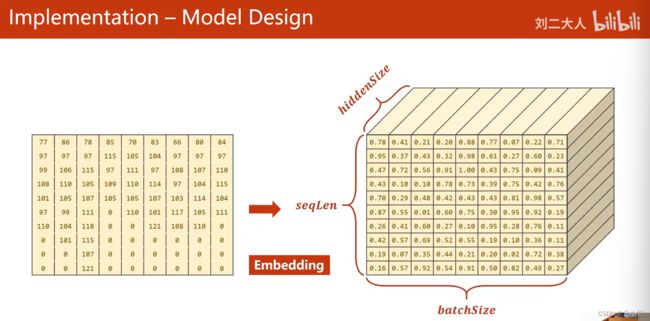
我们的每一个元素将来都会变成一个嵌入的向量。图中有些部分不太准确,0应该转化出来的结果都是一样的。
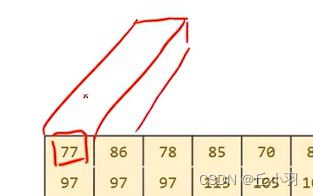

高亮部分应该是一样的数值。
接下来我们解释一下由名字转化为Tensor的过程: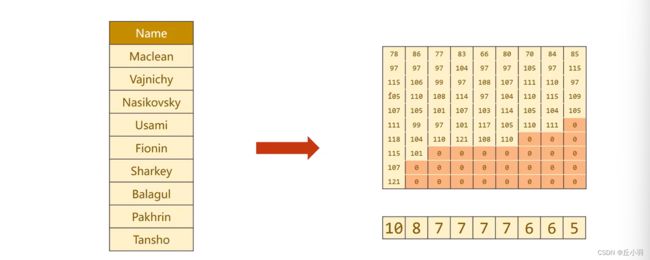
我们需要一个行表示batch列表示sqlen的矩阵,来表示姓名,我们还需要一个表示名字长度的行向量。我们一共需要两个数据。
转化的过程,先把字符串表示成一个一个字符,再把字符转化为一个一个ASCII码值。

之后做填充,填充完之后做转置。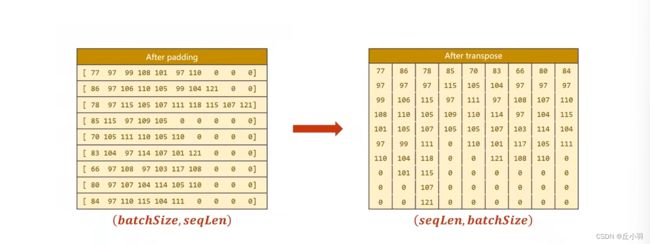
转置之后做排序。