LangChain 78 LangSmith 从入门到精通三
LangChain系列文章
- LangChain 60 深入理解LangChain 表达式语言23 multiple chains链透传参数 LangChain Expression Language (LCEL)
- LangChain 61 深入理解LangChain 表达式语言24 multiple chains链透传参数 LangChain Expression Language (LCEL)
- LangChain 62 深入理解LangChain 表达式语言25 agents代理 LangChain Expression Language (LCEL)
- LangChain 63 深入理解LangChain 表达式语言26 生成代码code并执行 LangChain Expression Language (LCEL)
- LangChain 64 深入理解LangChain 表达式语言27 添加审查 Moderation LangChain Expression Language (LCEL)
- LangChain 65 深入理解LangChain 表达式语言28 余弦相似度Router Moderation LangChain Expression Language (LCEL)
- LangChain 66 深入理解LangChain 表达式语言29 管理prompt提示窗口大小 LangChain Expression Language (LCEL)
- LangChain 67 深入理解LangChain 表达式语言30 调用tools搜索引擎 LangChain Expression Language (LCEL)
- LangChain 68 LLM Deployment大语言模型部署方案
- LangChain 69 向量数据库Pinecone入门
- LangChain 70 Evaluation 评估、衡量在多样化数据上的性能和完整性
- LangChain 71 字符串评估器String Evaluation衡量在多样化数据上的性能和完整性
- LangChain 72 reference改变结果 字符串评估器String Evaluation
- LangChain 73 给结果和参考评分 Scoring Evaluator
- LangChain 74 有用的或者有害的helpful or harmful Scoring Evaluator
- LangChain 75 打造你自己的OpenAI + LangChain网页应用
- LangChain 76 LangSmith 从入门到精通一
- LangChain 77 LangSmith 从入门到精通二

1. 与另一个提示词prompt进行比较
现在我们有了测试运行结果,我们可以对我们的代理进行更改并进行基准测试。让我们尝试用不同的提示再次尝试,看看结果。
candidate_prompt = hub.pull("wfh/langsmith-agent-prompt:39f3bbd0")
chain_results = run_on_dataset(
dataset_name=dataset_name,
llm_or_chain_factory=functools.partial(
create_agent, prompt=candidate_prompt, llm_with_tools=llm_with_tools
),
evaluation=evaluation_config,
verbose=True,
client=client,
project_name=f"runnable-agent-test-39f3bbd0-{unique_id}",
project_metadata={
"env": "testing-notebook",
"model": "gpt-3.5-turbo",
"prompt": "39f3bbd0",
},
)
View the evaluation results for project 'runnable-agent-test-39f3bbd0-97e1' at:
https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/14d8a382-3c0f-48e7-b212-33489ee8a13e/compare?selectedSessions=7753a05e-8235-4bc2-a227-d0622c1a36a4
View all tests for Dataset agent-qa-e2d24144 at:
https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/14d8a382-3c0f-48e7-b212-33489ee8a13e
[------------------------------------------------->] 5/5
实验结果:
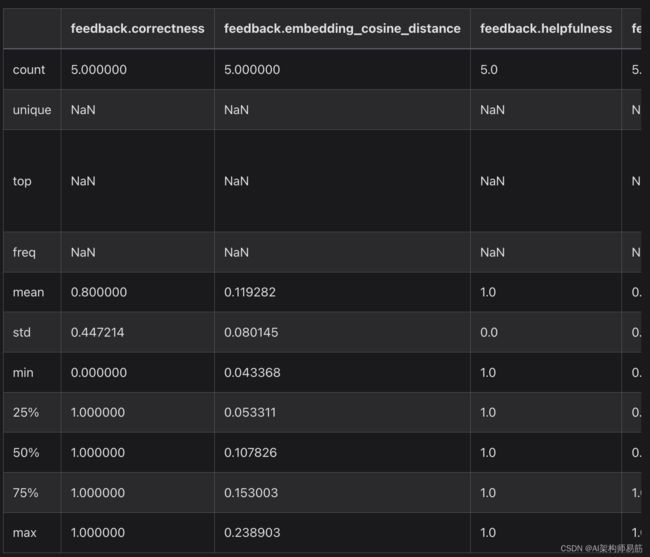
2. 导出数据集和运行
LangSmith允许您在Web应用程序中直接将数据导出到常见格式,如CSV或JSONL。您还可以使用客户端获取运行结果进行进一步分析,存储在您自己的数据库中,或与他人分享。让我们从评估运行中获取运行跟踪。
注意:在所有运行可访问之前可能需要一些时间。
runs = client.list_runs(project_name=chain_results["project_name"], execution_order=1)
# After some time, these will be populated.
client.read_project(project_name=chain_results["project_name"]).feedback_stats
{'correctness': {'n': 5, 'avg': 0.8},
'embedding_cosine_distance': {'n': 5, 'avg': 0.11926},
'helpfulness': {'n': 5, 'avg': 1.0},
'not_uncertain': {'n': 5, 'avg': 1.0},
'score_string:accuracy': {'n': 5, 'avg': 0.82}}
3. 总结
恭喜!您已成功跟踪和评估使用LangSmith的Agent!
这是一个快速入门指南,但使用LangSmith有许多其他方法可以加快开发流程并产生更好的结果。
有关如何充分利用LangSmith的更多信息,请查看LangSmith文档,并请通过[email protected]发送问题、功能请求或反馈。
代码
https://github.com/zgpeace/pets-name-langchain/tree/develop
参考
https://python.langchain.com/docs/langsmith/walkthrough