1、将 ChatGPT 集成到数据科学工作流程中:提示和最佳实践
将 ChatGPT 集成到数据科学工作流程中:提示和最佳实践
希望将 ChatGPT 集成到您的数据科学工作流程中吗?这是一个利用 ChatGPT 进行数据科学的提示的实践。
ChatGPT、其继任者 GPT-4 及其开源替代品非常成功。开发人员和数据科学家都希望提高工作效率,并使用 ChatGPT 来简化他们的日常任务。
在这里,我们将通过与 ChatGPT 的结对编程会话来了解如何将 ChatGPT 用于数据科学。我们将构建一个文本分类模型,可视化数据集,确定模型的最佳超参数,尝试不同的机器学习算法等等——所有这些都使用 ChatGPT。
在此过程中,我们还将研究某些提示来构建提示,以获得有用的结果。要继续,您需要拥有一个免费的 OpenAI 帐户。如果您是 GPT-4 用户,您也可以按照相同的提示进行操作。
更快地构建工作模型
让我们尝试使用 ChatGPT 为 scikit-learn 中的 20 个新闻组数据集构建一个新闻分类模型。
这是我使用的提示:“我想使用 sklearn 20 个新闻组数据集构建一个新闻分类模型。你知道吗?
虽然我的提示在这一点上不是很具体,但我已经陈述了目标和数据集:
- 目的:建立新的分类模型
- 要使用的数据集:来自 scikit-learn 的 20 个新闻组数据集
ChatGPT 的响应告诉我们从加载数据集开始。
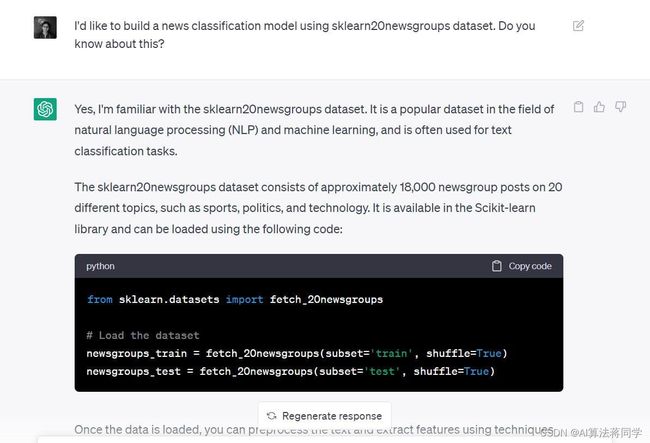
# Load the dataset
newsgroups_train = fetch_20newsgroups(subset='train', shuffle=True)
newsgroups_test = fetch_20newsgroups(subset='test', shuffle=True)
正如我们也陈述了目标(构建文本分类模型)一样,ChatGPT 告诉我们如何做到这一点。
我们看到它为我们提供了以下步骤:
- 用于文本预处理并提出数字表示。这种使用 TF-IDF 分数的方法比使用 .
TfidfVectorizer``CountVectorizer - 使用朴素贝叶斯或支持向量机 (SVM) 分类器在数据集的数值表示上创建分类模型。
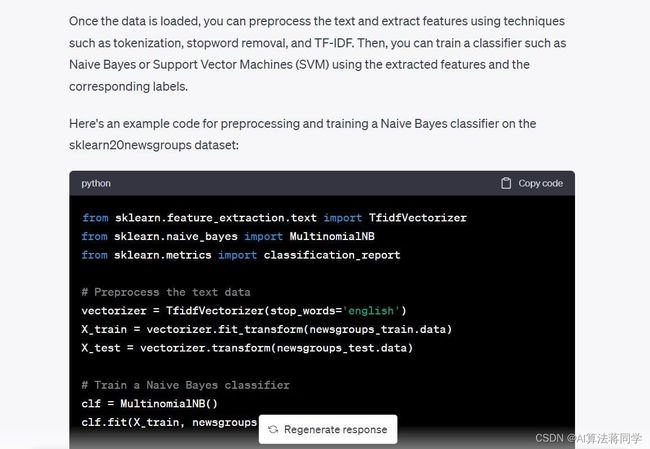
它还给出了多项式朴素贝叶斯分类器的代码,所以让我们使用它并检查我们是否已经有一个工作模型。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
# Preprocess the text data
vectorizer = TfidfVectorizer(stop_words='english')
X_train = vectorizer.fit_transform(newsgroups_train.data)
X_test = vectorizer.transform(newsgroups_test.data)
# Train a Naive Bayes classifier
clf = MultinomialNB()
clf.fit(X_train, newsgroups_train.target)
# Evaluate the performance of the classifier
y_pred = clf.predict(X_test)
print(classification_report(newsgroups_test.target, y_pred))
我继续运行上面的代码。而且它按预期工作,没有错误。我们在几分钟内从空白屏幕变成了文本分类模型,只有一个提示。
Output >>
precision recall f1-score support
0 0.80