数据分析基础之《pandas(7)—高级处理2》
四、合并
如果数据由多张表组成,那么有时候需要将不同的内容合并在一起分析
1、先回忆下numpy中如何合并
水平拼接
np.hstack()
竖直拼接
np.vstack()
两个都能实现
np.concatenate((a, b), axis=)
2、pd.concat([data1, data2], axis=1)
按照行或者列进行合并,axis=0为列索引,axis=1为行索引
将刚才处理好的one-hot编码与原数据合并
# pd.concat实现合并
# 原始数据
stock.head()
# one-hot编码处理好的数据
stock_change.head()
pd.concat([stock, stock_change], axis=1)
# 如果强行按照列索引拼接
pd.concat([stock_change, stock], axis=0)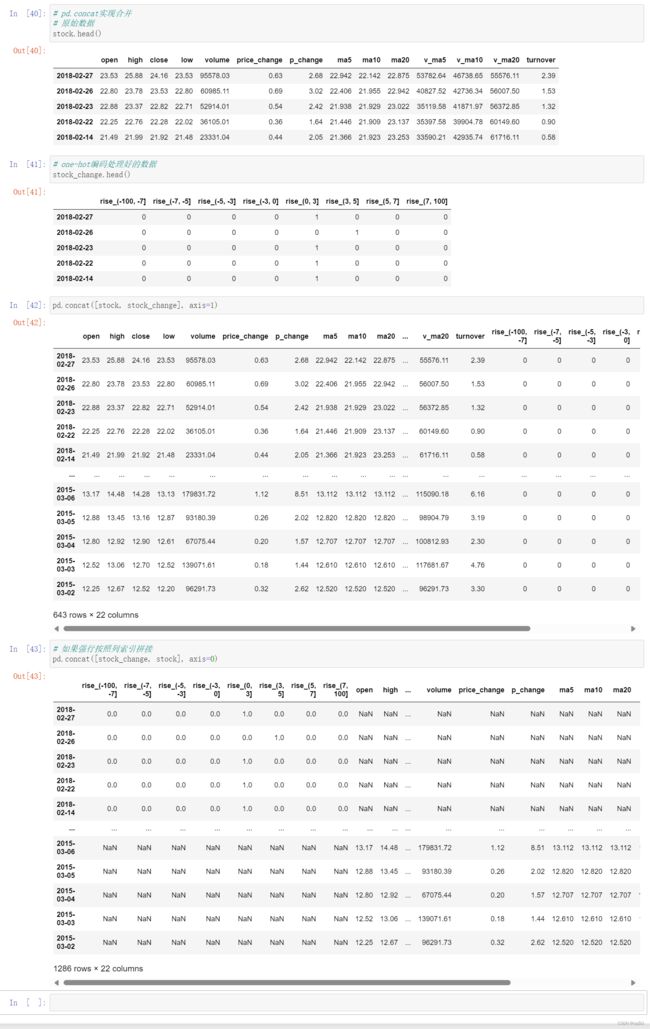
3、pd.merge(left, right, how="inner", on=[索引])
说明:
left:左表
right:右表
how:如何合并,left左连接,right右连接,inner内连接,outer外连接
on:按什么字段
五、交叉表与透视表
1、交叉表与透视表有什么作用
找到、探索两个变量之间的关系
2、交叉表
交叉表用于计算一列数据对于另外一列数据的分组个数(寻找两个列之间的关系)
pd.crosstab(value1, value2)
# 交叉表
# 星期数和涨跌幅之间的关系
# pd.crosstab(星期数据列, 涨跌幅数据列)
# 准备星期数据列
date = pd.to_datetime(stock.index)
date
# stock加上星期一列
stock["week"] = date.weekday
stock
# 准备涨跌幅数据列
stock["pona"] = np.where(stock["p_change"] > 0, 1, 0)
stock
# 调用交叉表
data = pd.crosstab(stock["week"], stock["pona"])
data
# 将频数转成百分比
data.div(data.sum(axis=1), axis=0)
# 画图
data.div(data.sum(axis=1), axis=0).plot(kind="bar", stacked=True)
3、透视表
使用透视表,刚才的过程更加简单
pivot_table([数据字段], index=[分组字段])
# 透视表
# 对pona字段,用week来分组
stock.pivot_table(["pona"], index=["week"])
六、分组与聚合
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况
刚才的交叉表与透视表也有分组的功能,所以算是分组的一种形式,只不过他们主要是计算次数或者计算比例!!
1、什么是分组与聚合
分组:group by
聚合:通常是统计函数
2、分组与聚合API
(1)DataFrame.groupby(by=, as_index=False)
说明:
by:分组的列数据,可以多个
(2)Series.groupby()
用法和DataFrame.groupby类似
# 进行分组,对颜色分组,price1进行聚合
# 用dataframe的方法进行分组
col.groupby(by="color")["price1"].max()
# 使用series进行分组
col["price1"].groupby(col["color"]).max()
3、星巴克零售店铺数据案例
想知道美国的星巴克数量和中国的哪个多,或者想知道中国每个省份星巴克的数量的情况
# 星巴克零售店铺数据案例
starbucks = pd.read_csv("./directory.csv")
starbucks
# 按照国家分组,求出每个国家的星巴克零售店数量
starbucks.groupby("Country").count()["Brand"].sort_values(ascending=False)[:10].plot(kind="bar", figsize=(20, 8), fontsize=20)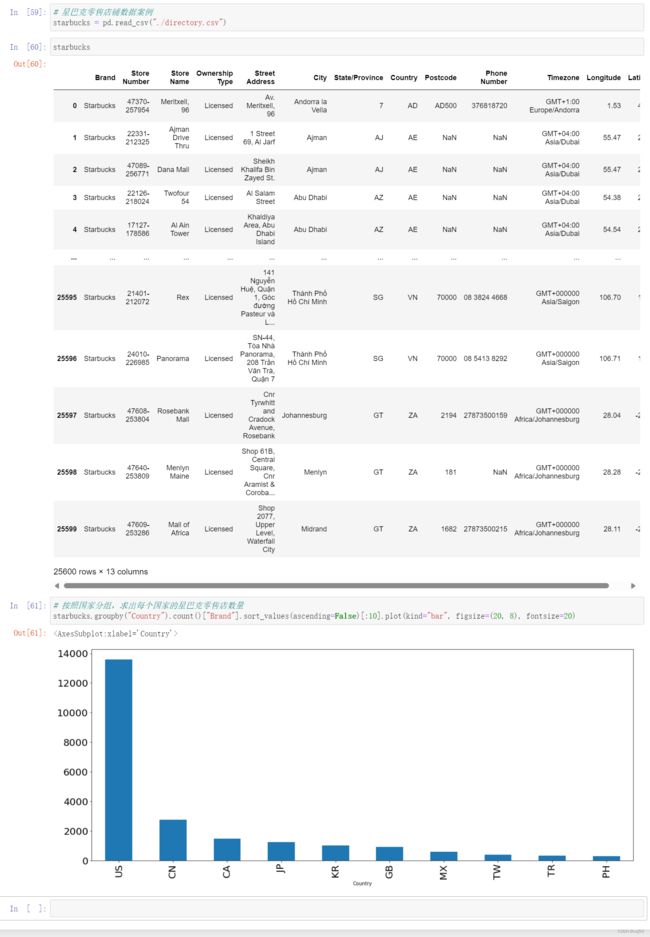
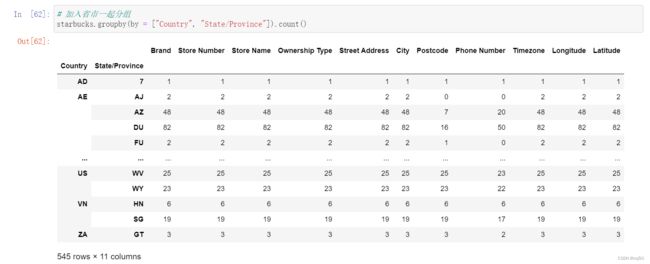
# 加入省市一起分组
starbucks.groupby(by = ["Country", "State/Province"]).count()