代码+视频基于R语言进行K折交叉验证
我们在建立数据模型后通常希望在外部数据验证模型的检验能力。然而当没有外部数据可以验证的时候,交叉验证也不失为一种方法。交叉验验证(交叉验证,CV)则是一种评估模型泛化能力的方法,广泛应用中于数证据采挖掘和机器学习领域,在交叉验证通常将数据集分为两部分,一部分为训练集,用于建立预测模型;另一部分为测试集,用于测试该模型的泛化能力。
在如何划分2个集合的问题上,统计学界提出了多种方法:简单交叉验证、留一交叉验证、k折交叉验证、多重三折交叉验证、分层法、自助法等。
简单交叉验证:是我们临床论文中最常使用到的,从数据中随机选择中随机选择70%点的数据作为训练集建立模型,30%的数据当做外部数据来验证模型的预测能力。但其最终所得结果与集合划分比率密切相关,不同划分比率结果变异可能较大。该方法在总数据据集并不是非常大的情形下很难达到准确实评模型的目的。
留一交叉验证是指:假设在总集合中共有有n个体,每次选取1个体作为测试试集,其余个体作为训练集。总共进行n 次训练,取平均值是最终评价指标。留一交叉验证较为可靠靠,在每次模型训练中纳入几度乎所有个体,当总集合中个体 数目轨迹的情势下计算时间较长。
k折交叉验证:可以看成是留一交叉验证的简化版,是将原始数据据随机平均分为k个子集(通常5-10个),每个子集做测试集的同时,其余k-1个子集合并作为训练 ,进行 k 次训练,取各评价指标(灵敏度、特异度、AUC等)的平均值。测试通过平均的评价指来降低训练集和测试集划分方式对预测结果的影响,有研究值表明k 折评估准准确性高,当k为5或10时在评估准准后性和计算复杂性下综合性能最优。
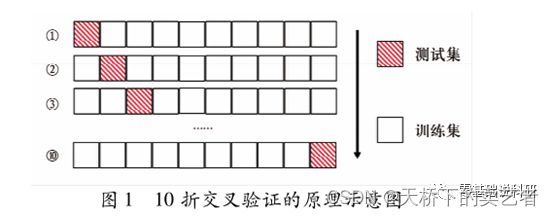
10折交叉验证是指将原始数据集随机划分为样本数近乎相等的10个子集,轮流将其中的9个合并作为训练集,其余1个作为测试试集。算正确率等评价指标,最终终通过K次试验验后取评价指标的平均值来评估该模型的泛化能力。
10折交叉证验证的基本步骤下:
( 1)原始数据集划分为10个样本量尽可均衡的子集;
( 2)使用第1个子集作为测试集,第2~9个子集合并作为训练集;
( 3)使用训练集对模型进行训练,计算多种评价指标在测试集下的结果;
( 4)重复2 ~3 步流亜,轮将第2 ~10个子集作为测试集;
( 5)计算各评价指标的平均值作为最终结果。
今天我们通过视频来演示k折交叉验证(K取10),需要使用到caret包和pROC包,需要使用到我们既往的不孕症数据(公众号回复:不孕症,可以获得该数据)
基于R语言进行K折交叉验证
代码:
library("caret")
library(pROC)
###公众号回复:不孕症,可以获得这个数据
bc<-read.csv("E:/r/test/buyunzheng.csv",sep=',',header=TRUE)
###
bc$education<-ifelse(bc$education=="0-5yrs",0,ifelse(bc$education=="6-11yrs",1,2))
bc$spontaneous<-as.factor(bc$spontaneous)
bc$case<-as.factor(bc$case)
bc$induced<-as.factor(bc$induced)
bc$education<-as.factor(bc$education)
####拆分数据
set.seed(666)
folds <- createFolds(y=bc$case,k=10)###分成10份
#####我们先来做第一个数据的,要提取列表的数据,需要做成[[1]]这种形式,
fold_test <- bc[folds[[1]],]#取fold 1数据,建立测试集和验证集
fold_train <- bc[-folds[[1]],]#
######
fold_pre <- glm(case ~ age + parity +spontaneous,
family = binomial(link = logit), data =fold_train )###建立模型
fold_predict <- predict(fold_pre,type='response',newdata=fold_test)##生成预测值
roc1<-roc((fold_test[,5]),fold_predict)
round(auc(roc1),3)##AUC
round(ci(roc1),3)##95%CI
##得出结果后我们可以进一步画图
plot(roc1, print.auc=T, auc.polygon=T, grid=c(0.1, 0.2),
grid.col=c("green", "red"), max.auc.polygon=T,
auc.polygon.col="skyblue",
print.thres=T)
plot(1-roc1$specificities,roc1$sensitivities,col="red",
lty=1,lwd=2,type = "l",xlab = "specificities",ylab = "sensitivities")
abline(0,1)
legend(0.7,0.3,c("auc=0.34","ci:0.457-0.99."),lty=c(1),lwd=c(2),col="red",bty = "n")
# 嫌一个一个做比较麻烦的话我们也可以做成循环,一次跑完结果
# 先建立一个auc的空值,不然跑不了
auc_value<-as.numeric()
for(i in 1:10){
fold_test <- bc[folds[[i]],] #取folds[[i]]作为测试集
fold_train <- bc[-folds[[i]],] # 剩下的数据作为训练集
fold_pre <- glm(case ~ age + parity +spontaneous,
family = binomial(link = logit), data =fold_train )
fold_predict <- predict(fold_pre,type='response',newdata=fold_test)
auc_value<- append(auc_value,as.numeric(auc(as.numeric(fold_test[,5]),fold_predict)))
}
####
mean(auc_value)