开源模型应用落地-工具使用篇-向量数据库(三)
一、前言
通过学习"开源模型应用落地"系列文章,我们成功地建立了一个完整可实施的AI交付流程。现在,我们要引入向量数据库,作为我们AI服务的二级缓存。本文将详细介绍如何使用Milvus Lite来为我们的AI服务部署一个前置缓存。
二、术语
2.1、向量数据库
向量数据库是一种专门用于存储和处理高维向量数据的数据库系统。与传统的关系型数据库或文档数据库不同,向量数据库的设计目标是高效地支持向量数据的索引和相似性搜索。
在传统数据库中,数据通常是以结构化的表格形式存储,每个记录都有预定义的字段。但是,对于包含大量高维向量的数据,如图像、音频、文本等,传统的数据库模型往往无法有效地处理。向量数据库通过引入特定的数据结构和索引算法,允许高效地存储和查询向量数据。
向量数据库的核心概念是向量索引。它使用一种称为向量空间模型的方法,将向量映射到多维空间中的点,并利用这种映射关系构建索引结构。这样,当需要搜索相似向量时,可以通过计算向量之间的距离或相似度来快速定位相似的向量。
2.2、向量数据库的使用场景
向量数据库在许多领域中都有广泛的应用场景,特别是涉及到高维向量数据存储和相似性搜索的任务。以下是一些常见的使用场景:
- 目标识别和图像搜索:向量数据库可用于存储图像特征向量,以支持快速的相似图像搜索和目标识别。它在图像搜索引擎、人脸识别和视频监控等领域具有重要作用。
- 推荐系统:向量数据库可以存储用户和物品的特征向量,用于个性化推荐。基于相似性搜索,可以找到与用户兴趣相似的物品,提供个性化的推荐结果。
- 自然语言处理:在文本处理任务中,可以使用向量数据库存储文本向量,如词向量、句向量等。基于相似性搜索,可以进行文本匹配、语义相似度计算等操作。
- 数据聚类和分类:向量数据库可用于高维向量数据的聚类和分类分析。它可以帮助发现数据集中的聚类模式和类别,用于数据挖掘和机器学习任务。
- 检索与推荐系统:在电子商务和商品搜索中,向量数据库可以存储商品特征向量,以支持相似商品的搜索和推荐。它可以提供更准确和个性化的搜索结果。
- 医疗和生物信息学:向量数据库可用于存储基因表达向量、蛋白质特征向量等生物信息学数据。它可以在基因组学、药物研发等领域中帮助进行数据分析和研究。
- 视频内容分析:向量数据库可用于存储视频特征向量,如视频帧特征、视频片段特征等。它可以用于视频内容搜索、视频剪辑和视频推荐等应用。
2.3、向量相似度检索
相似度检索是指将目标对象与数据库中数据进行比对,并召回最相似的结果。同理,向量相似度检索返回的是最相似的向量数据。
2.4、向量相似度检索算法
- 余弦相似度(Cosine Similarity):余弦相似度是一种常用的衡量向量相似性的方法。它通过计算两个向量之间的夹角余弦值来度量它们的相似程度。余弦相似度范围在[-1, 1]之间,值越接近1表示两个向量越相似。
- 欧氏距离(Euclidean Distance):欧氏距离是计算向量之间距离的一种常见方法。它衡量了两个向量之间的几何距离,即两个向量之间的直线距离。欧氏距离越小表示两个向量越相似。
- 曼哈顿距离(Manhattan Distance):曼哈顿距离是计算向量之间距离的一种度量方式。它衡量了两个向量之间的城市街区距离,即通过水平和垂直方向移动所需的步数之和。
- Jaccard相似度(Jaccard Similarity):Jaccard相似度通常用于计算集合之间的相似性,但也可以应用于特征向量的相似性计算。它通过计算两个向量的交集与并集之间的比值来度量它们的相似程度。
- 汉明距离(Hamming Distance):汉明距离通常用于计算两个等长字符串之间的距离,但也可应用于二进制向量的相似性计算。它衡量了两个向量之间在相应位置上不同位的数量。
- 最近邻搜索算法(Nearest Neighbor Search):最近邻搜索算法通过计算向量之间的相似度或距离,找到与目标向量最相似的邻居向量。常用的最近邻搜索算法包括暴力搜索、KD树、球树、LSH(局部敏感哈希)等。
2.5、Milvus
是一个开源的向量数据库引擎,专门用于存储和处理大规模高维向量数据。它提供了高效的向量索引和相似性搜索功能,使用户能够快速地进行向量数据的存储、查询和分析。
Milvus的设计目标是为了满足现代应用中对大规模向量数据的需求,例如人脸识别、图像搜索、推荐系统等。它采用了向量空间模型和多种索引算法,包括倒排索引、近似最近邻(Approximate Nearest Neighbor,ANN)等,以支持高效的相似性搜索。
Milvus提供了易于使用的编程接口和丰富的功能,使用户可以方便地插入、查询和分析向量数据。它支持多种数据类型的向量,包括浮点型、整型等,也支持多种距离度量方法,如欧氏距离、余弦相似度等。
Milvus还提供了分布式部署和横向扩展的能力,可以在多台机器上构建高可用性和高性能的向量数据库集群。它支持数据的分片和负载均衡,可以处理大规模数据集和高并发查询。
2.6、Milvus Lite
是Milvus向量数据库的一个轻量级版本。旨在提供在资源受限的环境中快速、高效地进行向量存储和相似性搜索的能力。
与完整版的Milvus相比,它具有以下特点:
- 轻量级:Milvus Lite具有较小的存储占用和内存消耗,适合在资源受限的设备上部署和运行。
- 快速部署:Milvus Lite提供了简化的部署和配置过程,使其更易于在嵌入式设备和边缘服务器上进行部署和集成。
- 高效的向量索引和搜索:尽管是轻量级版本,Milvus Lite仍然提供了高效的向量索引和相似性搜索功能,以支持快速的向量数据查询。
- 离线模式:Milvus Lite支持在离线模式下进行向量索引和搜索,无需实时连接到远程服务器。
2.7、Attu
是Milvus 的高效开源管理工具。 它具有直观的图形用户界面(GUI),使您可以轻松地与数据库进行交互。
2.8、归一化
是一种数据处理技术,用于将不同尺度或范围的数据转换为统一的标准范围,通常是0到1之间或者是-1到1之间。它是数据预处理的常见步骤之一,旨在消除不同特征之间的尺度差异,以便更好地比较和分析数据。
2.9、标准化
是一种数据处理技术,用于将数据转换为具有零均值和单位方差的标准分布。它是数据预处理的一种常见方法,旨在消除不同特征之间的尺度差异,使得数据更适合进行比较和分析。
三、使用方式
3.1、架构示意图
这里的Milvus Lite部署在内网,位于业务服务和AI服务的中间,作为AI服务的二级缓存(一级缓存为Redis),为AI服务减缓负载压力。

3.2、安装Milvus Lite
1. 创建虚拟环境
conda create --name milvus python=3.10
2. 激活虚拟环境
conda activate milvus
3. 安装milvus包
pip install milvus
3.3、编写Milvus Lite服务端代码
此处将Milvus Lite作为 Python 模块启动
from milvus import default_server
def start_server():
default_server.start()
def stop_server():
default_server.stop()
if __name__ == '__main__':
with default_server:
start_server()
input("按下任意键继续...")
3.4、启动Milvus Lite服务
python -u 上述代码的文件名

启动完成后,会监听19530端口
3.5、安装Milvus客户端管理工具
下载地址:Releases · zilliztech/attu · GitHub
3.6、登录Milvus Lite服务端
注意根据实际情况调整IP和端口,默认端口为19530

登录进去,就能看到如下信息:

四、业务整合
业务数据需要提前初始化到向量数据库中
4.1、连接milvus服务端
# 1. 连接向量数据库 Milvus
def connect_db(host):
logging.info("start connecting to Milvus")
# Milvus Lite has already started, use default_server here.
connections.connect(host=host, port=19530,user='root',password='123456',)
logging.info("connected to Milvus")
4.2、创建集合
dim = 256
alias = 'default'
nlist = 65536
# 2. 创建数据集合 collection
def create_collection(collection_name):
isExist = has_collection(collection_name=collection_name, using=alias)
if isExist:
print(f'集合{collection_name}已经存在')
return
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="keyword", dtype=DataType.FLOAT_VECTOR, dim=dim),
FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=4096)
]
schema = CollectionSchema(fields, "the collection of tb_test")
logging.info(f"Create collection {collection_name}")
tb_test = Collection(collection_name, schema, consistency_level="Strong")
return tb_testPS:keyword的向量维度是256,高维向量可以提供更丰富的信息表示能力,能够捕捉更多的特征和关系,从而提高模型的表达能力。
创建成功后:

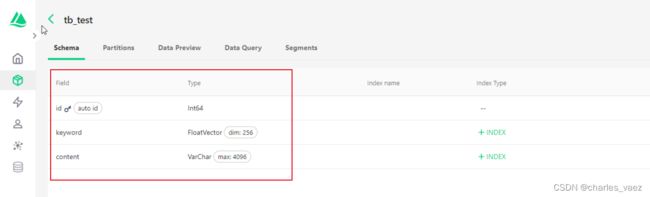
4.3、插入数据
# 3. 插入数据实体 entities
def insert_data(collection_name,narray,content,isNormalize = True):
res = None
try:
# 获得已存在集合对象
collection = Collection(name=collection_name, using=alias)
logging.info("Start inserting entities")
if isNormalize == True:
# 标准化处理
normalize_narray = pretreatment(narray)
print(normalize_narray)
# 补齐向量长度
padded_vector = narray_pad(normalize_narray, dim)
print(padded_vector)
else:
# 补齐向量长度
padded_vector = narray_pad(narray, dim)
# 打印补齐后的向量
logging.info(padded_vector.shape)
entities = [
padded_vector, # title
[content], # content
]
res = collection.insert(entities)
collection.flush()
finally:
return res
# 插入数据
narray = np.array([100220.0,102247.0,31905.0,40814.0,101009.0, 87335.0,8863.0,20.0,15.0,15.0,104745.0,100354.0,43815.0,103010.0,102233.0,100351.0,102482.0])
content = "标题:青春之光青春是一首歌,悠扬而激昂;青春是一幅画,斑斓而生动;青春是一部电影,感人至深。而在我心中,青春更是那个在奥运赛场上奔跑的刘翔。记得那是2004年的雅典奥运会,刘翔以12.91秒的成绩打破了世界纪录,成为中国田径历史上第一位获得奥运金牌的运动员。那一刻,我被他的坚韧和毅力深深打动,也深深地感受到了青春的力量。刘翔的青春,充满了挑战和奋斗。他曾经因为伤病困扰,一度想要放弃,但他没有。他知道,只有坚持下去,才能实现自己的梦想。于是,他在痛苦中挣扎,用汗水和泪水浇灌着自己的青春。终于,他成功了,他站在了奥运的最高领奖台上,成为了全中国的骄傲。刘翔的青春,充满了激情和活力。他是中国田径的一颗璀璨明星,他的每一次起跑都充满力量,他的每一次跨栏都充满速度。他的青春,就像一道闪电,照亮了整个赛场,也照亮了我们的心灵。刘翔的青春,充满了希望和梦想。他的梦想是成为最好的自己,他的希望是为中国赢得更多的荣誉。他的青春,就像一盏明灯,指引着他前进的方向,也激励着我们去追求自己的梦想。青春,就是要有梦想,有希望,有勇气去追逐。刘翔的青春,就是这样,充满了梦想、希望和勇气。他的青春,是我们所有人的青春,是我们所有人追求梦想的动力。青春,是一场无悔的旅程,无论前方有多少困难和挫折,只要我们有梦想,有希望,有勇气,就一定能够到达我们的目的地。让我们一起,像刘翔一样,用自己的青春,去创造属于我们自己的辉煌!"
# 调用方法
insert_data(collection_name,narray,content,True)插入成功后:

PS:受限于本篇内容较长,如何获取文本向量以及如何进行标准化或归一化处理,将在另外的文章中说明。
4.4、创建索引
# 4. 创建索引 index
def create_index(collection_name,index_column,index_name):
try:
collection = Collection(name=collection_name, using=alias)
# 给向量字段构建索引,并指定索引类型,以及相似度度量方式
# nlist 表示簇的个数,该参数可以将向量划分成多个区域,有利于加快搜索
index_params = {
"metric_type": "IP",
"index_type": "IVF_FLAT",
"params": {"nlist": nlist}
}
collection.create_index(field_name=index_column, index_name=index_name, index_params=index_params)
finally:
if collection:
collection.release()
# 创建索引 index
collection_name = "tb_test"
index_column='keyword'
index_name='idx_keyword'
# 调用
create_index(collection_name, index_column, index_name)创建成功后:
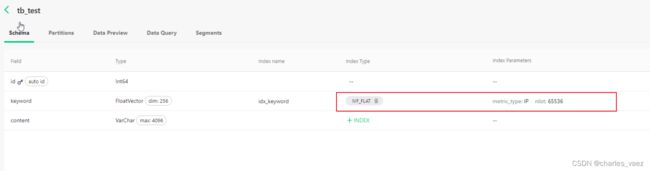
4.5、加载数据至缓存
def load_in_memory(collection_name):
collection = Collection(name=collection_name, using=alias)
# 将整个 collection 加载到内存中,也可以只加载某个 Partition
collection.load()
return collection
# 加载集合到缓存
collection_name = "tb_test"
# 调用
load_in_memory(collection_name)

五、附带说明
5.1、目前市面上成熟的向量数据库产品有很多,结合实际效果,这里选择Milvus作为项目解决方案。
5.2、其他Milvus Lite启动方式
# 通过 CLI 来启动 Milvus Lite,执行命令:milvus-server
# 通过 CLI 以调试模式来启动 Milvus Lite,执行命令:milvus-server --debug
5.3、milvus_cli管理工具
# 安装
pip install milvus-cli
# 登录
milvus_cli
# 连接数据库
connect -uri http://127.0.0.1:19530
5.4、milvus_cli常用命令
创建数据库
create database -db test
使用数据库
use database -db test
查看数据库
list databases
删除数据库
delete database -db test
创建collection
create collection -c car -f id:INT64:primary_field
-f vector:FLOAT_VECTOR:128
-f color:INT64:color
-f brand:INT64:brand
-p id -a
-level Strong
Options:
-c, --collection-name TEXT Collection name to specify alias.
-p, --schema-primary-field TEXT Primary field name.
-a, --schema-auto-id [Optional, Flag] - Enable auto id.
-desc, --schema-description TEXT [Optional] - Description details.
-d, --is-dynamic TEXT [Optional] - Collection schema supportsdynamic fields or not.
-level, --consistency-level TEXT [Optional] - Consistency level:Bounded,Session,Strong, Eventual .
-f, --schema-field TEXT [Multiple] - FieldSchema. Usage is "::"
-s, --shards-num INTEGER [Optional] - Shards number
查看collection
list collections
删除collection
delete collection -c tb_test
创建index
create index
Collection name (tb_test): tb_test
The name of the field to create an index for (vector): vector
Index name: vectorIndex
Default is ''
Index type (FLAT, IVF_FLAT, IVF_SQ8, IVF_PQ, RNSG, HNSW, ANNOY, AUTOINDEX, DISKANN, ) []: IVF_FLAT
Default is ''
Index metric type (L2, IP, HAMMING, TANIMOTO,): L2
Index params nlist: 2
查看index
list indexes -c tb_test
查看partitions
list partitions -c tb_test
删除partitions
delete partition -c tb_test -p new_partition
删除entities
delete entities -c tb_test
加载
load collection -c tb_test
Options:
-c, --collection TEXT The name of collection to load.
-p, --partition TEXT [Optional, Multiple] - The name of partition to load.
--help Show this message and exit.
释放
release collection -c tb_test
Options:
-c, --collection TEXT The name of collection to load.
-p, --partition TEXT [Optional, Multiple] - The name of partition to load.
--help
show
show collection -c tb_test
show index -c tb_test
show index_progress -c tb_test
show loading_progress -c tb_test
show partition -c tb_test
创建别名
create alias -c tb_test -A -a tb_test11
Options:
-c, --collection-name TEXT Collection name to be specified alias.
-a, --alias-name TEXT The alias of the collection.
-A, --alter [Optional, Flag] - Change an existing alias to
current collection.
创建用户
create user -u root -p 123456
-u, --username TEXT The username of milvus user.
-p, --password TEXT The password of milvus user.
查看用户
list users
查看版本
version
5.5、高维向量表示的优劣
优势:
- 表示能力增强:高维向量可以提供更丰富的信息表示能力,能够捕捉更多的特征和关系,从而提高模型的表达能力。
- 解决冗余信息:在高维空间中,冗余特征可能会被稀疏化,使得模型更容易识别和利用有效的特征。
- 处理复杂问题:某些复杂问题可能需要更高维度的向量来表示,以便更好地捕捉问题的复杂性和多样性。
劣势
- 维度灾难:高维度数据可能导致维度灾难问题,即数据稀疏性增加,对于有限的训练数据而言,模型的泛化能力可能会受到影响。
- 计算复杂性增加:高维度数据需要更多的计算资源和时间来处理和分析,可能会增加计算的复杂性和开销。
- 数据稀疏性:在高维空间中,数据点之间的距离变得更远,可能会导致数据稀疏性增加,从而影响模型的准确性和可靠性。