每日一“酷”之difflib
介绍:difflib 比较序列。该模块包含一些用来计算和处理序列直接差异的工具。她对于比较文本尤其用,其中包含的函数可以使用多种常用差异格式生成报告。
测试数据(splitlines()按行划分为序列列表):
text1 = """ We all know that English is very useful. Many people in the world speak English. So more and more people in China study it. How to study English well? I think we must have a good way to study English. If you want to learn English well, listening, speaking, reading and writing are important. You should listen to tapes every day. You should often speak English with your teachers and friends. You should read English every morning. And, you had better keep a diary every day. In this way, you can study English well. """ text1_lines = text1.splitlines() text2 = """ We all know that English is very useful. Many people in the world speak English. So more and more people in China study it. How to study English well? I think we must have a good way for study English. If you wants to learn English well, listening, speaking, reading and writing are important. He could not read music, but if he heard a tune a few times, he could play it. You should listen to tapes every day. You should often speak English with your teachers and friends. You should read English everyday morning. And, you had better keep a diary every day. In this ways, you can study English well. """ text2_lines = text2.splitlines()
1、比较文本体
Differ类 勇于处理文本序列,生成人类可读的差异或者更改指令,包括各行中的差异。Differ类生成的默认输出与UNIX下的diff命令行工具类似,包括两个列表的原始输入值(包含共同的值),以及指示做了哪些更改的标记数据。
· 有“-”前缀的行指示这些行在第一个序列中,但不包含在第二个序列中
· 有“+”前缀的行在第二个序列中,但不包含在第一个序列中
· 如果某一行在不同版本之间存在增量差异,会使用一个以“?”为前缀的额外的行强调新版本的变更
· 如果一行未改变,会输出该行,而且其左边有一个额外的空格,使它在与其他可能有差异的输出对齐
将文本传入compare()之前先分解为由单个文本行构成的序列,与传入大字符串相比,这样可以生成更可读的输出
1 import difflib 2 from difflib_data import * 3 d = difflib.Differ() 4 diff = d.compare(text1_lines,text2_lines) 5 print '\n'.join(diff)
运行结果:
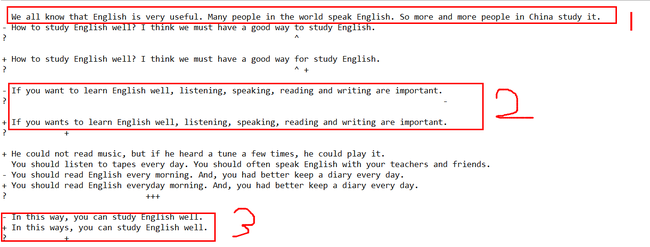
上面是程序运行的结果,简单分析一下:
第一部分,是没有异常的即两段文字一样,就会原样输出。
第二部分与第三部分雷同,都是存在一定的差异,会用“-”与“+”号进行处理并标注在相应位置。
如果差异过长会完全删除老版本,而增加新版本。(compare(lt1,lt2)两者后者是新版本)
ndiff()函数生成的输出基本相同,会特别“加工”来处理文本数据,并删除输入中的“噪声”。用法:difflib.ndiff(lt1,lt2)
其他格式输出:
Differ类会显示所有输入行,统一差异格式则不同,它只包含已修改的文本行和一些上下文,使用unified_diff()函数
演示:
1 import difflib 2 from difflib_data import * 3 #unified_diff 4 diff = difflib.unified_diff(text1_lines, 5 text2_lines, 6 lineterm='' 7 ) 8 print '\n'.join(list(diff)) 9 print '-----------------------' 10 #context_diff 11 diff = difflib.context_diff(text1_lines, 12 text2_lines, 13 lineterm='' 14 ) 15 print '\n'.join(list(diff))
演示结果:
说明:lineterm 参数用来告诉unified_diff()不必为它返回的控制昂追加换行符,因为输入航不包含这些换行符。输出时所有都会则感觉换行符。
2、无用数据
所有生成差异序列的函数都可以接受一些参数来指示应当忽略那些行,以及应当忽略一行中的那些字符,例如:可以用这些参数指定跳过一个文件两个本中的标记或者空白变更。
1 from difflib import SequenceMatcher 2 def show_result(s): 3 i,j,k = s.find_longest_match(0,5,0,9) 4 print ' i = %d' % i 5 print ' j = %d' % j 6 print ' k = %d' % k 7 print ' A[i:i+k] = %r' % A[i:i+k] 8 print ' B[j:j+k] = %r' % B[j:j+k] 9 10 A = " abcd" 11 B = "abcd abcd" 12 13 print 'A = %r' % A 14 print 'B = %r' % B 15 16 print '\nWithout junk detection:' 17 show_result(SequenceMatcher(None,A,B))
运行结果:

默认情况下,Differ不会显式忽略任何行或者字符,而回依赖SequenceMatcher 的能力检测噪声。ndiff()的默认行为时忽略空格和制表符。
3、比较任意类型
SequenceMatcher类用于比较任意类型的两个系列,只要它们的值是可散列。这个类使用一个算法来标识序列中最长的链接匹配块,并删除对实际数据没有贡献的无用值。
实例:
1 import difflib 2 from difflib_data import * 3 4 s1 = [1,2,3,5,6,4] 5 s2 = [2,3,5,4,6,1] 6 print 'Initial data:' 7 print 's1 = ',s1 8 print 's2 = ',s2 9 print 's1 == s2:', s1 == s2 10 print 11 12 matcher = difflib.SequenceMatcher(None,s1,s2) 13 for tag,i1,i2,j1,j2 in reversed(matcher.get_opcodes()): 14 if tag == 'delete': 15 print 'Remove %s from positions [%d : %d]' %\ 16 (s1[i1:i2],i1,i2) 17 del s1[i1:i2] 18 elif tag == 'equal': 19 print 's1[%d : %d] and s2[%d : %d] are the same' % \ 20 (i1,i2,j1,j2) 21 elif tag == 'insert': 22 print 'Insert %s from s2[%d : %d] into s1 at %d' % \ 23 (s2[j1:j2],j1,j2,i1) 24 s1[i1:i2] = s2[j1:j2] 25 elif tag == 'replace': 26 print 'Replace %s from s1[%d : %d] with %s from s2[%d : %d]' % \ 27 (s1[i1:i2],i1,i2,s2[j1:j2],j1,j2) 28 s1[i1:i2] = s2[j1:j2] 29 print ' s1 =',s1 30 print 's1 == s2:',s1 == s2
执行结果:

这个例子比较了量证书列表,并使用get_opcodes()得到将原列表转换为新列表的指令,这里以逆序应用所做的修改,是的添加和删除元素之后雷暴索引仍是正确的。
SwquenceMatcher 用于处理定制类以及内置类型,前提是它们必须是课散列的