Sphinx+MySQL5.1x+SphinxSE+mmseg中文分词
Sphinx+MySQL5.1x+SphinxSE+mmseg中文分词
搜索引擎架构搭建
什么是Sphinx
Sphinx 是一个在GPLv2 下发布的一个全文检索引擎,一般而言,Sphinx是一个独立的搜索引擎,意图为其他应用提供高速、低空间占用、高结果相关度的全文搜索功能。Sphinx可以非常容易的与SQL数据库和脚本语言集成。当前系统内置MySQL和PostgreSQL 数据库数据源的支持,也支持从标准输入读取特定格式的XML数据。通过修改源代码,用户可以自行增加新的数据源(例如:其他类型的DBMS的原生支持)。
Sphinx的特性
高速的建立索引(在当代CPU上,峰值性能可达到10 MB/秒);
高性能的搜索(在2 – 4GB 的文本数据上,平均每次检索响应时间小于0.1秒);
可处理海量数据(目前已知可以处理超过100 GB的文本数据, 在单一CPU的系统上可处理100 M 文档);
提供了优秀的相关度算法,基于短语相似度和统计(BM25)的复合Ranking方法; 支持分布式搜索;
provides document exceprts generation;
可作为MySQL的存储引擎提供搜索服务;
支持布尔、短语、词语相似度等多种检索模式;
文档支持多个全文检索字段(最大不超过32个);
文档支持多个额外的属性信息(例如:分组信息,时间戳等);
停止词查询;
支持单一字节编码和UTF-8编码;
原生的MySQL支持(同时支持MyISAM 和InnoDB );
原生的PostgreSQL 支持.
更多特性参考手册。
原生MySQL存储引擎检索流程:
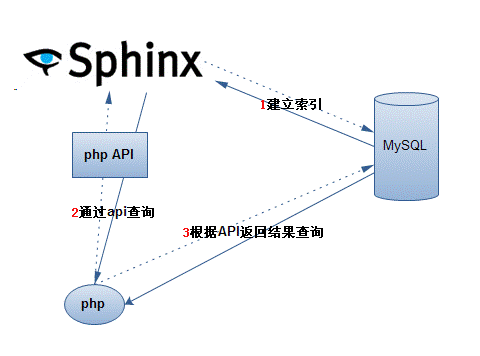
基于Sphinx存储引擎检索:

开始
本文以CentOS5.5+mysql-5.1.55+sphinx-0.9.9(coreseek-3.2.14.tar.gz目前最新稳定版)为例介绍
安装前准备文件
Sphinx+MySQL5.1x+SphinxSE存储引擎+mmseg中文分词搜索引擎架构搭建过程。
通过yum命令更新依赖包(与php环境搭建依赖包一起更新了)
yum -y install gcc g++ gcc-c++ libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel ncurses ncurses-devel curl curl-devel e2fsprogs e2fsprogs-devel krb5 krb5-devel libidn libidn-devel openssl openssl-devel openldap openldap-devel nss_ldap openldap-clients openldap-servers patch libtool automake imake mysql-devel expat-devel
安装MySQL+SphinxSE,进入软件包目录
tar zxvf mysql-5.1.55.tar.gz
tar zxvf sphinx-0.9.9.tar.gz
cp -r sphinx-0.9.9/mysqlse/ mysql-5.1.55/storage/sphinx
cd mysql-5.1.55
./BUILD/autorun.sh
./configure --prefix=/usr/local/webserver/mysql/ --enable-assembler --with-extra-charsets=complex --enable-thread-safe-client --with-big-tables --with-readline --with-ssl --with-embedded-server --enable-local-infile --with-plugins=partition,innobase,myisammrg,sphinx
make
make install
。。。省略若干配置步骤,和平时配置MySQL没什么两样。
安装完成启动MySQL后查看sphinx存储引擎是否安装成功
在mysql命令行下执行
show engines;
如果出现如下图红色方框内的信息说明SphinxSE已经安装成功!

安装Sphinx全文检索服务器
Sphinx默认不支持中文索引及检索, 以前用Coreseek的补丁来解决,目前Coreseek 不单独提供补丁文件,而基于sphinx开发了Coreseek 全文检索服务器,Coreseek应该是现在用的最多的sphinx中文全文检索,它提供了为Sphinx设计的中文分词包LibMMSeg包含mmseg中文分词,其实coreseek-3.2.14.tar.gz中已经包含了sphinx,前面安装SphinxSE时也可以使用这个压缩包里的mysqlse。
我们来看一下的安装过程:
安装autoconf
tar zxvf autoconf-2.64.tar.gz
cd autoconf-2.64
./configure --prefix=/usr
make
make install
cd ..
安装Coreseek
tar zxvf coreseek-3.2.14.tar.gz
cd coreseek-3.2.14
cd mmseg-3.2.14/
./bootstrap
./configure --prefix=/usr/local/mmseg3
make
make install
cd ../csft-3.2.14/
sh buildconf.sh
./configure --prefix=/usr/local/coreseek --without-python --without-unixodbc --with-mmseg --with-mmseg-includes=/usr/local/mmseg3/include/mmseg/ --with-mmseg-libs=/usr/local/mmseg3/lib/ --with-mysql --host=arm
make
make install
cd /usr/local/coreseek/etc
进入配置目录通过命令ls可以看到3个文件
example.sql sphinx.conf.dist sphinx-min.conf.dist
其中example.sql是示例sql脚本我们将其导入到数据库中的test数据库中作为测试数据(会创建两张表 documents和tags)
vi sphinx.conf
输入以下内容
source src1
{
type = mysql
sql_host = localhost
sql_user = root
sql_pass =12345678
sql_db = test
sql_port = 3306 # optional, default is 3306
sql_sock = /tmp/mysql.sock
sql_query_pre = SET NAMES utf8
sql_query = \
SELECT id, group_id, UNIX_TIMESTAMP(date_added) AS date_added, title, content \
FROM documents
sql_attr_uint = group_id
sql_attr_timestamp = date_added
sql_query_info = SELECT * FROM documents WHERE id=$id
}
index test1
{
source = src1
path = /usr/local/coreseek/var/data/test1
docinfo = extern
charset_type = zh_cn.utf-8
mlock = 0
morphology = none
min_word_len = 1
html_strip = 0
charset_dictpath = /usr/local/mmseg3/etc/
ngram_len = 0
}
indexer
{
mem_limit = 32M
}
searchd
{
port = 9312
log = /usr/local/coreseek/var/log/searchd.log
query_log = /usr/local/coreseek/var/log/query.log
read_timeout = 5
max_children = 30
pid_file = /usr/local/coreseek/var/log/searchd.pid
max_matches = 1000
seamless_rotate = 1
preopen_indexes = 0
unlink_old = 1
}
说明:
代码段source src1{***} 代表数据源里面主要包含了数据库的配置信息,src1表示数据源名字,可以随便写。
代码段index test1{***} 代表为哪个数据源创建索引,与source *** 是成对出现的,其中的source参数的值必须是某一个数据源的名字。
其他参数可以查看手册,这里不再赘述。
生成索引
/usr/local/coreseek/bin/indexer -c /usr/local/coreseek/etc/sphinx.conf --all
其中参数--all表示生成所有索引
当然也可以是索引的名字例如:/usr/local/coreseek/bin/indexer -c /usr/local/coreseek/etc/sphinx.conf test1
执行后可以在/usr/local/coreseek/var/data目录中看到多出一些文件,是以索引名为文件名的不同的扩展名的文件
在不启动sphinx的情况下即可测试命令:
/usr/local/coreseek/bin/search -c /usr/local/coreseek/etc/sphinx.conf number
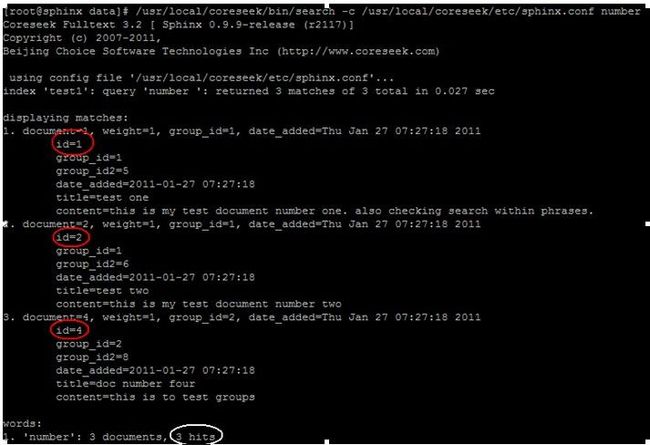
可以看到将内容中含有number数据的数据查询出来。
过滤查询
/usr/local/coreseek/bin/search -c /usr/local/coreseek/etc/sphinx.conf number --filter group_id 2
限定group_id 为2 返回一条记录
同样也可以测试中文(需将命令行终端编码调整为utf-8)
/usr/local/coreseek/bin/search -c /usr/local/coreseek/etc/sphinx.conf 研究生创业
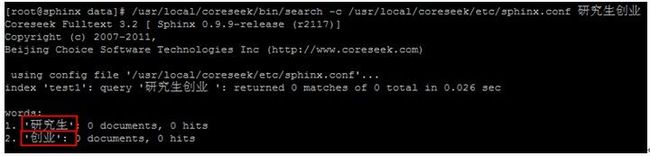
可以看到我们输入的查询文字已经被拆分成了两个词,只是因为我们的测试数据中没有中文数据查询结果为空。我们插入几条新数据。
set names utf8 之前一定要设置字符集
INSERT INTO `test`.`documents` (
`id` ,
`group_id` ,
`group_id2` ,
`date_added` ,
`title` ,
`content`
)
VALUES (
NULL , '2', '3', '2011-02-01 00:37:12', '研究生的故事', '研究生自主创业'
), (
NULL , '1', '1', '2011-01-28 00:38:22', '研究', '为了创业而研究生命科学'
);
我们再来看以下数据库中的主要数据
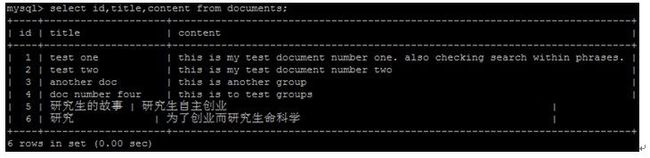
插入新数据后需要重新生成索引
/usr/local/coreseek/bin/indexer -c /usr/local/coreseek/etc/sphinx.conf test1
然后执行查询测试 /usr/local/coreseek/bin/search -c /usr/local/coreseek/etc/sphinx.conf 研究生创业
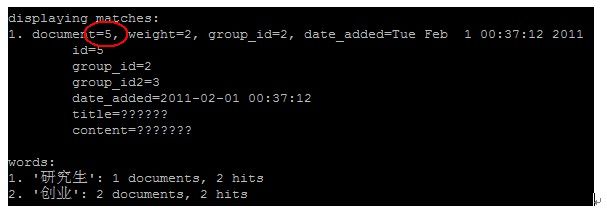
我们搜索的词语是“研究生创业”,可以看到词语被拆分成了研究生和创业两个词,虽然有两条记录都包含“创业和”研究生”这几个字但是“研究生命科学”中的“研究生”三个字虽然是紧挨着的但是不是一个词语,结果是只匹配一条“研究生自主创业”,我们在搜索“研究”这个词语
/usr/local/coreseek/bin/search -c /usr/local/coreseek/etc/sphinx.conf 研究

同样匹配一条记录,而“研究生的故事”和“研究生自主创业”的词语却没有被查询出来,可以看出sphinx与分词技术结合可以匹配出相关度更高的结果。
当然我们的目的不仅限与命令行下的测试,我们可以通过搜索API调用来执行搜索,搜索API支持PHP、Python、Perl、Rudy和Java。如果从PHP脚本检索需要先启动守护进程searchd,PHP脚本需要连接到searchd上进行检索:
/usr/local/coreseek/bin/searchd -c /usr/local/coreseek/etc/sphinx.conf
在解压后的sphinx-0.9.9/api目录下的sphinxapi.php就是sphinx官方为我们提供的API文件(其实也可以使用PHP的sphinx扩展),只需将其包含进自己的PHP脚本文件就可以了。
示例代码:
<?php
include('sphinxapi.php');
$cl = new SphinxClient();
//设置sphinx服务器地址与端口,如果是本机则可以为localhost
$cl->SetServer( "192.168.16.6", 9312 );
//以下设置用于返回数组形式的结果
$cl->SetArrayResult ( true );
//$cl->SetMatchMode( SPH_MATCH_ANY );//匹配模式
//$cl->SetFilter( 'group_id', array( 2 ) );
$result = $cl->Query( '研究生创业', 'test1' ); //参数 关键字 索引名
if ( $result === false ) {
echo "Query failed: " . $cl->GetLastError() . ".\n";
}
else {
if ( $cl->GetLastWarning() ) {
echo "WARNING: " . $cl->GetLastWarning() . "";
}
echo '<pre>';
print_r( $result );
}
?>
执行后的结果:
Array
(
[error] =>
[warning] =>
[status] => 0
[fields] => Array
(
[0] => title
[1] => content
)
[attrs] => Array
(
[group_id] => 1
[date_added] => 2
)
[matches] => Array
(
[5] => Array
(
[weight] => 2
[attrs] => Array
(
[group_id] => 2
[date_added] => 1296491832
)
)
)
[total] => 1
[total_found] => 1
[time] => 0.078
[words] => Array
(
[研究生] => Array
(
[docs] => 1
[hits] => 2
)
[创业] => Array
(
[docs] => 2
[hits] => 2
)
)
)
在matches中的就是查询结果,我们注意到sphinx是将记录中的主键ID值返回而不是返回所有数据,上面的例子中的键名5就是记录的ID(如果在查询前执行$cl->SetArrayResult ( true );则数组结构会有些许差异)。至此搜索服务器已经为我们完成了大部分工作,接下来我们通过主键ID值来查询我们想要的数据就可以了。
Sphinx存储引擎的使用
SphinxSE是一个可以编译进MySQL 5.x版本的MySQL存储引擎,它利用了该版本MySQL的插件式体系结构。尽管被称作“存储引擎”,SphinxSE自身其实并不存储任何数据。它其实是一个允许MySQL服务器与searchd交互并获取搜索结果的嵌入式客户端。所有的索引和搜索都发生在MySQL之外。
SphinxSE的适用于:
使将MySQL FTS 应用程序移植到Sphinx
使没有Sphinx API的那些语言也可以使用Sphinx
当需要在MySQL端对Sphinx结果集做额外处理(例如对原始文档表做JOIN,MySQL端的额外过滤等等)时提供优化。
要通过SphinxSE搜索,需要建立特殊的ENGINE=SPHINX的“搜索表”,然后使用SELECT语句从中检索,把全文查询放在WHERE子句中。
创建一张表t1
CREATE TABLE t1
(
id INTEGER UNSIGNED NOT NULL,
weight INTEGER NOT NULL,
query VARCHAR(3072) NOT NULL,
group_id INTEGER,
INDEX(query)
) ENGINE=SPHINX CONNECTION="sphinx://localhost:9312/test1";
搜索表前三列的类型必须是INTEGER,INTEGER和VARCHAR,这三列分别对应文档ID,匹配权值和搜索查询。查询列必须被索引,其他列必须无索引。列的名字会被忽略,所以可以任意命名,参数CONNECTION来指定用这个表搜索时的默认搜索主机、端口号和索引,语法格式:CONNECTION="sphinx://HOST:PORT/INDEXNAME"。
执行SQL语句 select d.id,d.title,d.content from t1 join documents as d on t1.id = d.id and t1.query = '研究生创业';
+----+--------------------+-----------------------+
| id | title | content |
+----+--------------------+-----------------------+
| 5 | 研究生的故事 | 研究生自主创业 |
+----+--------------------+-----------------------+
1 row in set (0.04 sec)
结果返回了我们想要的数据,可见利用SphinxSE可以仅仅在SQL语句上做很小的改动即可很方便的实现全文检索!