【Elasticsearch】Elasticsearch索引创建与管理详解
文章目录
- 引言
- 一、Elasticsearch 索引的基础概念
- 二、创建索引
-
- 2.1 使用默认设置创建索引
- 2.2 自定义设置创建索引
- 2.3 创建索引并设置映射
- 三、索引模板
-
- 3.1 创建索引模板
- 3.2 使用索引模板创建索引
- 四、管理索引
-
- 4.1 查看索引
- 4.2 更新索引设置
- 4.3 删除索引
- 五、索引别名
-
- 5.1 创建索引别名
- 5.2 使用别名查询
- 5.3 更新索引别名
- 六、分片和副本管理
-
- 6.1 分片
- 6.2 副本
- 七、索引性能优化
-
- 7.1 分片数量的选择
- 7.2 动态调整副本
- 7.3 索引刷新间隔
- 八、索引模板的高级应用
- 九、索引管理工具
-
- 9.1 Kibana
- 9.2 Curator

引言
Elasticsearch 是一个基于 Apache Lucene 的开源搜索引擎,具有分布式、近实时、RESTful API 等特点。索引是 Elasticsearch 的核心概念之一,索引的创建和管理是使用 Elasticsearch 的基础技能。本文将详细介绍 Elasticsearch 索引的创建与管理,包括索引的基础概念、创建索引、索引模板、映射和索引别名等内容。
一、Elasticsearch 索引的基础概念
在 Elasticsearch 中,索引类似于传统数据库中的数据库。一个索引包含了多个文档,而每个文档都包含了多个字段。以下是一些关键概念:
- 文档(Document):Elasticsearch 中的数据单位,类似于数据库中的一行数据。
- 索引(Index):包含多个文档,类似于数据库中的数据库。
- 类型(Type):在较早版本的 Elasticsearch 中,索引中的一种逻辑划分,现已弃用。
- 分片(Shard):索引可以分为多个分片,以实现水平扩展和高可用性。
- 副本(Replica):分片的备份,以提高数据的容错能力。
二、创建索引
2.1 使用默认设置创建索引
Elasticsearch 提供了简单的创建索引的方法,只需发送一个 HTTP 请求即可。
PUT /my_index
这个命令将在 Elasticsearch 中创建一个名为 my_index 的索引,使用默认的设置和映射。
2.2 自定义设置创建索引
可以在创建索引时自定义分片、副本和其他设置。
PUT /my_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
这将创建一个名为 my_index 的索引,包含 3 个主分片和 2 个副本。
2.3 创建索引并设置映射
映射定义了索引中字段的类型及其属性,可以在创建索引时一起定义。
PUT /my_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
},
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"created_at": {
"type": "date",
"format": "yyyy-MM-dd"
}
}
}
}
这个命令创建了一个索引,并定义了三个字段:name(文本类型)、age(整数类型)和 created_at(日期类型)。
三、索引模板
索引模板允许你为符合特定模式的索引设置默认配置和映射,当索引名称符合模板定义的模式时,会自动应用模板中的设置和映射。
3.1 创建索引模板
PUT /_template/my_template
{
"index_patterns": ["my_index_*"],
"settings": {
"number_of_shards": 1
},
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
这个模板将应用于所有以 my_index_ 开头的索引,并自动设置其分片数量和映射。
3.2 使用索引模板创建索引
当创建符合模板模式的索引时,模板会自动应用:
PUT /my_index_2024
这个命令将创建一个名为 my_index_2024 的索引,并应用 my_template 中定义的设置和映射。
四、管理索引
4.1 查看索引
可以使用以下命令查看索引的详细信息:
GET /my_index
这个命令将返回索引的配置信息和状态。
4.2 更新索引设置
索引创建后,可以动态更新一些设置,例如副本数量:
PUT /my_index/_settings
{
"number_of_replicas": 1
}
4.3 删除索引
可以使用以下命令删除索引:
DELETE /my_index
这个命令将删除 my_index 索引及其所有数据。
五、索引别名
索引别名允许你为一个或多个索引创建别名,以便于查询和管理。
5.1 创建索引别名
POST /_aliases
{
"actions": [
{
"add": {
"index": "my_index",
"alias": "my_index_alias"
}
}
]
}
这个命令为 my_index 创建了一个别名 my_index_alias。
5.2 使用别名查询
GET /my_index_alias/_search
{
"query": {
"match_all": {}
}
}
这个查询将通过别名 my_index_alias 查询 my_index 中的所有文档。
5.3 更新索引别名
可以动态更新别名,例如将别名指向另一个索引:
POST /_aliases
{
"actions": [
{
"remove": {
"index": "my_index",
"alias": "my_index_alias"
},
"add": {
"index": "new_index",
"alias": "my_index_alias"
}
}
]
}
这个命令将 my_index_alias 从 my_index 移除,并指向 new_index。
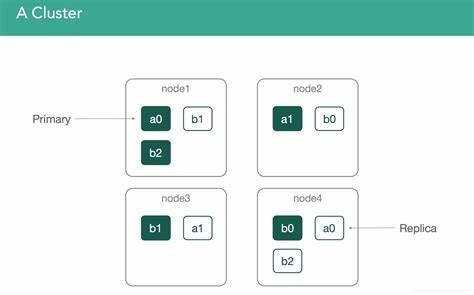
六、分片和副本管理
6.1 分片
分片是 Elasticsearch 用于水平扩展和分布式存储的基本单位。每个索引可以分为多个主分片(Primary Shard),每个主分片可以有多个副本分片(Replica Shard)。分片的数量在索引创建时设置,并且一旦设置就不能更改,但副本数量可以动态调整。
分片的优点包括:
- 扩展性:可以将数据分布到多个节点上,提高存储和处理能力。
- 高可用性:通过副本分片提供容错能力,当主分片失效时,副本分片可以提升为主分片。
6.2 副本
副本分片是主分片的完整拷贝,用于提供高可用性和读取性能。当一个节点失效时,副本分片可以确保数据不会丢失并继续提供服务。
七、索引性能优化
7.1 分片数量的选择
在创建索引时,选择适当的分片数量是优化索引性能的关键。过多的分片会导致资源浪费,过少的分片会导致性能瓶颈。可以根据数据量和节点数量来合理设置分片数量。
7.2 动态调整副本
在读多写少的场景中,可以增加副本数量以提高读取性能。在写多读少的场景中,可以减少副本数量以提高写入性能和减少开销。
7.3 索引刷新间隔
默认情况下,Elasticsearch 每秒会刷新一次索引,将新数据写入磁盘。在批量写入数据时,可以适当增加刷新间隔以提高写入性能,减少 I/O 开销。
PUT /my_index/_settings
{
"index": {
"refresh_interval": "30s"
}
}
八、索引模板的高级应用
动态模板
动态模板允许根据字段名称或数据类型自动应用特定的映射规则,适用于需要灵活处理不同字段的情况。
PUT /_template/dynamic_template_example
{
"index_patterns": ["dynamic_*"],
"mappings": {
"dynamic_templates": [
{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
这个动态模板会将所有以 dynamic_ 开头的索引中的字符串字段映射为 keyword 类型。
九、索引管理工具
9.1 Kibana
Kibana 是 Elasticsearch 的数据可视化和管理工具,提供了直观的界面来管理和查询 Elasticsearch 索引。可以通过 Kibana 查看索引状态、执行查询和分析数据。
9.2 Curator
Curator 是 Elasticsearch 的索引管理工具,提供了一组命令行工具来管理索引生命周期。可以使用 Curator 定期删除旧索引、优化索引和管理快照。