机器学习基石笔记13——机器可以怎样学得更好(1)
转载请注明出处:http://www.cnblogs.com/ymingjingr/p/4271742.html
目录
机器学习基石笔记1——在何时可以使用机器学习(1)
机器学习基石笔记2——在何时可以使用机器学习(2)
机器学习基石笔记3——在何时可以使用机器学习(3)(修改版)
机器学习基石笔记4——在何时可以使用机器学习(4)
机器学习基石笔记5——为什么机器可以学习(1)
机器学习基石笔记6——为什么机器可以学习(2)
机器学习基石笔记7——为什么机器可以学习(3)
机器学习基石笔记8——为什么机器可以学习(4)
机器学习基石笔记9——机器可以怎样学习(1)
机器学习基石笔记10——机器可以怎样学习(2)
机器学习基石笔记11——机器可以怎样学习(3)
机器学习基石笔记12——机器可以怎样学习(4)
机器学习基石笔记13——机器可以怎样学得更好(1)
机器学习基石笔记14——机器可以怎样学得更好(2)
机器学习基石笔记15——机器可以怎样学得更好(3)
机器学习基石笔记16——机器可以怎样学得更好(4)
十三、Hazard of Overfitting
过拟合的危害
13.1 What is Overfitting?
什么是过拟合?
假设一个输入空间X是一维的,样本点数量为5的回归问题,其目标函数为二次函数,但是标记 包含噪音,因此标记表示为
包含噪音,因此标记表示为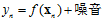 。使用四次多项式转换结合线性回归求解该问题的权值向量w,得出
。使用四次多项式转换结合线性回归求解该问题的权值向量w,得出 的唯一解,如图13-1所示。
的唯一解,如图13-1所示。

图13-1 二次的目标函数与四次多项式的最优假设函数
从图中不难得出该假设函数的 很大,因此四次的多项式函数有很差的泛化能力。
很大,因此四次的多项式函数有很差的泛化能力。
依据图13-2中分析此问题,在VC维 变大时,
变大时, 变小,但
变小,但 变大,此种情况称作过拟合(overfitting),意思为在训练样本上拟合做的很好,
变大,此种情况称作过拟合(overfitting),意思为在训练样本上拟合做的很好,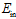 非常小,但是过度了,使得泛化能力变差,导致
非常小,但是过度了,使得泛化能力变差,导致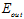 很大;当然还有一种情况是VC维
很大;当然还有一种情况是VC维 变小时,出现了
变小时,出现了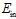 越来越小,同时
越来越小,同时 也越来越小,此种情况称为欠拟合(underfitting)。其中如何解决欠拟合的问题已经在12.4节作了介绍, 不断地提高多项式次数,使得VC维
也越来越小,此种情况称为欠拟合(underfitting)。其中如何解决欠拟合的问题已经在12.4节作了介绍, 不断地提高多项式次数,使得VC维 提高,达到拟合的效果,但过拟合的问题更为复杂,以后的章节会更深入的探讨。过拟合和坏的泛化有所不同,过拟合指的是
提高,达到拟合的效果,但过拟合的问题更为复杂,以后的章节会更深入的探讨。过拟合和坏的泛化有所不同,过拟合指的是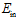 和
和 变化的过程,在
变化的过程,在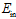 变小,
变小,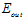 变大时称为过拟合;而坏的泛化是在某一点,
变大时称为过拟合;而坏的泛化是在某一点,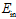 很小,
很小, 很大。
很大。

图13-2 VC维与错误率之间的关系
或许理解上还是有些困难,用一个类比的方式,便于人理解。将机器学习比作开车,如表13-1所示。
表13-1
| 机器学习 |
开车 |
| 过拟合 |
出车祸 |
| 使用过度的VC维 |
开得太快 |
| 噪音 |
颠簸的路面 |
| 数据量的大小 |
对路面状况的观察 |
其中第3~5行表示构成第2行的原因,即除了VC维度之外噪音和训练数据的大小对过拟合都有影响。
13.2 The Role of Noise and Data Size
噪音与数据量所扮演的角色。
为了更直观的解释产生过拟合的因素,设计两个实验,分别设计两个目标函数,一个10次多项式,另一个50次多项式,前者加上噪音,后者无噪音,生成如图13-3所示的数据点。

图13-3 a) 10次多项式加上噪音生成的训练数据 b) 10次多项式没有噪音生成的训练数据
使用两种不同的学习模型(二次式假设空间 与10次多项式假设空间
与10次多项式假设空间 )分别根据以上两个生成的训练数据进行学习。
)分别根据以上两个生成的训练数据进行学习。
首先,使用两种模型学习13-3a)生成的数据,两种模型产生的最优假设如图13-4所示,其中绿线表示二次模型学习得到的假设函数g, ,红色表示10次模型学习得到的假设函数g,
,红色表示10次模型学习得到的假设函数g, 。
。

图13-4 两种模型学习10次目标函数生成的数据
这两个最优函数的错误率如表13-2所示,在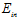 上,显然二次函数不如10次函数的错误率低,但是在
上,显然二次函数不如10次函数的错误率低,但是在 上,10次函数远远的高于2次函数(能够知道
上,10次函数远远的高于2次函数(能够知道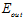 是因为已知目标函数,当然在现实中是不可能的),说明在做10次函数生成的训练数据上,使用2次函数模型会得到效果更优的
是因为已知目标函数,当然在现实中是不可能的),说明在做10次函数生成的训练数据上,使用2次函数模型会得到效果更优的 。
。
表13-2两种模型从10次目标函数生成数据产生的错误率
|
|
|
|
|
|
0.050 |
0.034 |
|
|
0.129 |
9.00 |



继续使用这两种模型对13-3 b)生成的数据进行学习,得到两种假设函数如图13-5所示。

图13-5两种模型学习50次目标函数生成的数据
这两个最优函数的错误率如表13-3所示,在 上,显然二次函数不如10次函数的错误率低,但是在
上,显然二次函数不如10次函数的错误率低,但是在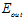 上,10次函数远远的高于2次函数,说明在做50次函数生成的训练数据上,使用2次函数模型会得到效果更优的
上,10次函数远远的高于2次函数,说明在做50次函数生成的训练数据上,使用2次函数模型会得到效果更优的 。
。
表13-3两种模型从50次目标函数生成数据产生的错误率
|
|
|
|
|
|
0.029 |
0.00001 |
|
|
0.120 |
7680 |



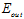
难道在两种情况下,从2次函数到10次函数都是过拟合?答案是对的。为什么二次式模型与目标函数的次数有很大差距反而比10次多项式模型学习能力还好?
要从学习鸿沟说起(learning curves),二次函数和10次函数的学习鸿沟如图13-6所示。
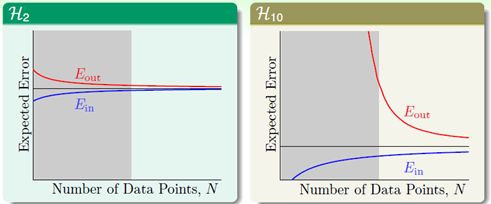
图13-6 a) 二次函数学习鸿沟 b) 10次函数学习鸿沟
从图中可以看出,数据量少时,尽管2次假设的 比10次函数的
比10次函数的 大很多,但是2次假设中
大很多,但是2次假设中 和
和 的差距比10次假设小的多,因此在样本点不多时,低次假设的学习泛化能力更强,即在灰色区域(样本不多的情况下)中,高次假设函数发生了过拟合。
的差距比10次假设小的多,因此在样本点不多时,低次假设的学习泛化能力更强,即在灰色区域(样本不多的情况下)中,高次假设函数发生了过拟合。
上述阐述了在含有噪音的情况下,低次多项式假设比和目标函数同次的多项式假设表现更好,那如何解释在50次多项式函数中也是二次式表现好的现象呢?因为50次目标函数对于不论是2次假设还是10次假设都相当于一种含有噪音的情况(两者都无法做到50次的目标函数,因此相当于含有噪音)。
13.3 Deterministic Noise
确定性噪音。
数据样本由两个部分组成,一是目标函数产生,和在此之上夹杂的噪音。其中假设噪音服从高斯分布,称作高斯噪音,其强度为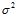 ;目标函数使用复杂度
;目标函数使用复杂度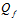 表示,即
表示,即 次多项式函数。
次多项式函数。
不难看出过拟合和噪音强度 、目标函数复杂度
、目标函数复杂度 (上节最后说明高次也是一种噪音形式)和训练数据量N都有着密切的关系,以下通过固定某一参数对比其他两个参数的方式,观察每个参数对过拟合的影响,分为
(上节最后说明高次也是一种噪音形式)和训练数据量N都有着密切的关系,以下通过固定某一参数对比其他两个参数的方式,观察每个参数对过拟合的影响,分为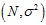 和
和 。
。
为了体现各个参数的影响,通过编写的程序完成一些规定的实验,绘制成具体的图像,便于理解。和上一节相同使用两种学习模型测试,二次式模型和10次多项式模型,其最优假设函数分别表示为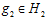 ,
, ,错误率满足
,错误率满足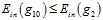 ,并使用
,并使用  作为过拟合的衡量。分别固定复杂度
作为过拟合的衡量。分别固定复杂度 和噪音强度
和噪音强度 得到如图13-7所示的两幅图。
得到如图13-7所示的两幅图。

图13-7 a) 固定算法强度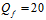 时
时  与N对拟合度的影响 b) 固定噪音强度
与N对拟合度的影响 b) 固定噪音强度 时
时 与N对拟合度的影响
与N对拟合度的影响
图13-7 a)表示在固定算法强度 时 ,噪音强度
时 ,噪音强度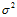 与样本数据量N对拟合度的影响,图中的颜色表示过拟合程度,深红色的部分表示过拟合,蓝色表示表现好,从图中得知在噪音强度
与样本数据量N对拟合度的影响,图中的颜色表示过拟合程度,深红色的部分表示过拟合,蓝色表示表现好,从图中得知在噪音强度 越大与样本数据量N越小时,过拟合越严重,有关高斯噪音产生的噪音又被称作随机噪音(stochastic noise);图13-7 b)表示在固定噪音强度
越大与样本数据量N越小时,过拟合越严重,有关高斯噪音产生的噪音又被称作随机噪音(stochastic noise);图13-7 b)表示在固定噪音强度 时 ,算法强度
时 ,算法强度 与样本数据量N对拟合度的影响,从图中得知在算法强度
与样本数据量N对拟合度的影响,从图中得知在算法强度 越大且样本数据量N越小时,过拟合越严重,在图的左下角的表现,与图13-7 a)的表现略有不同,即在算法强度
越大且样本数据量N越小时,过拟合越严重,在图的左下角的表现,与图13-7 a)的表现略有不同,即在算法强度 且数据量很小成三角形的区域,造成该现象的原因是此处选用的两个模型是二次式与10次多项式,而在低于10次的目标函数中使用10次多项式模型学习,即产生了13.1节中提过的,过度的VC维使用,有关算法强度产生也相当于产生了噪音,称作确定性噪音(deterministic noise)。
且数据量很小成三角形的区域,造成该现象的原因是此处选用的两个模型是二次式与10次多项式,而在低于10次的目标函数中使用10次多项式模型学习,即产生了13.1节中提过的,过度的VC维使用,有关算法强度产生也相当于产生了噪音,称作确定性噪音(deterministic noise)。
总结,造成严重过拟合现象的原因有四个:数据量N少,随机噪音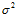 高,确定性噪音高,过量的VC维。
高,确定性噪音高,过量的VC维。
可能确定性噪音比较难于理解,通过图13-8再做一次简单的解释。

图13-8 确定性噪音示意图
其中蓝色曲线表示目标函数,红色取消表示二次式函数模型学习到的曲线,其中红色曲线的弯曲的形状使用2次函数是不可能模仿的,因此就相当于一种噪音。为什么使用低次函数学习效果却好呢?;这类似于教小孩学习学习简单的问题反而有助于成长。
13.4 Dealing with Overfitting
处理过拟合。
回忆13.1节中的表13-1,,提到了产生过拟合的三种原因,本节提出防止出现过拟合的几种情况,该情况与防止出车祸的应对措施作对比如表13-4所示。
表13-4 防止过拟合的措施与防止出车祸的措施的对比
| 从简单的模型出发 |
开慢点 |
| 数据清理/裁剪(data cleaning/pruning) |
更准确的路况信息 |
| 数据提示(data hinting) |
获取更多的路况信息 |
| 正则化(regularization) |
踩刹车 |
| 确认(validation) |
安装仪表盘 |
从简单模型出发的措施在前几节中都有体现,不再赘述,本节主要介绍数据清理以及数据提示,而正则化和确认则在后面的章节介绍。
以手写数字数据为例,介绍数据清理和数据裁剪,观察图13-9,手写数字为1的使用 表示;手写数字为5的使用
表示;手写数字为5的使用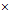 表示。其中在数字1中存在一个数字5的样本点,即图中左上角中的
表示。其中在数字1中存在一个数字5的样本点,即图中左上角中的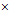 ,查看该样本的原图很难看出是数字5,类似这种离不同类别很近,离相同类别很远的样本,可以认为是噪音或者是离群点(outlier)。应对该种情况,有两种措施可用:纠正标识号,即数据清理(data cleaning)的方式处理该情况;删除错误样本,即数据裁剪(data pruning)的方式处理。处理措施很简单,但是发现样本是噪音或离群点却比较困难。
,查看该样本的原图很难看出是数字5,类似这种离不同类别很近,离相同类别很远的样本,可以认为是噪音或者是离群点(outlier)。应对该种情况,有两种措施可用:纠正标识号,即数据清理(data cleaning)的方式处理该情况;删除错误样本,即数据裁剪(data pruning)的方式处理。处理措施很简单,但是发现样本是噪音或离群点却比较困难。
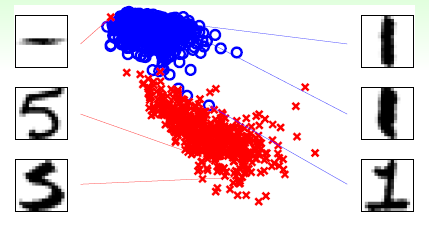
图13-9 手写数字的分布情况
继续介绍数据提示,还是以手写数字集为例,将如图13-10所示的手写数字集略作修改产生更多的手写数字样本,达到增加数据量N的目的。如将如下手写数字略作旋转(rotating)和平移(shifting),但要注意旋转和平移的幅度都不能太大,如6转180°就成了9。还需注意这种方式产生的虚拟样本(virtual examples),不在符合独立同分布,因此产生的虚拟样本与实际样本差距一定不宜太大。

图13-10 手写数字集