YOLOv8中的C2f模块代码详解
C2f模块代码详解
-
- 1.C2f模块组成
- 2.C2f模块作用
- 3.具体流程
- 4.代码实现
- 5.关键组件和参数说明
- 6.运行流程
- 7.输入输出示例
在YOLOv8网络结构中,C2F模块(CSP Bottleneck with 2 Convolutions)是一个关键组件,用于实现跨阶段部分聚合(Cross Stage Partial Fusion)。
YOLOv8整体网络结构图:
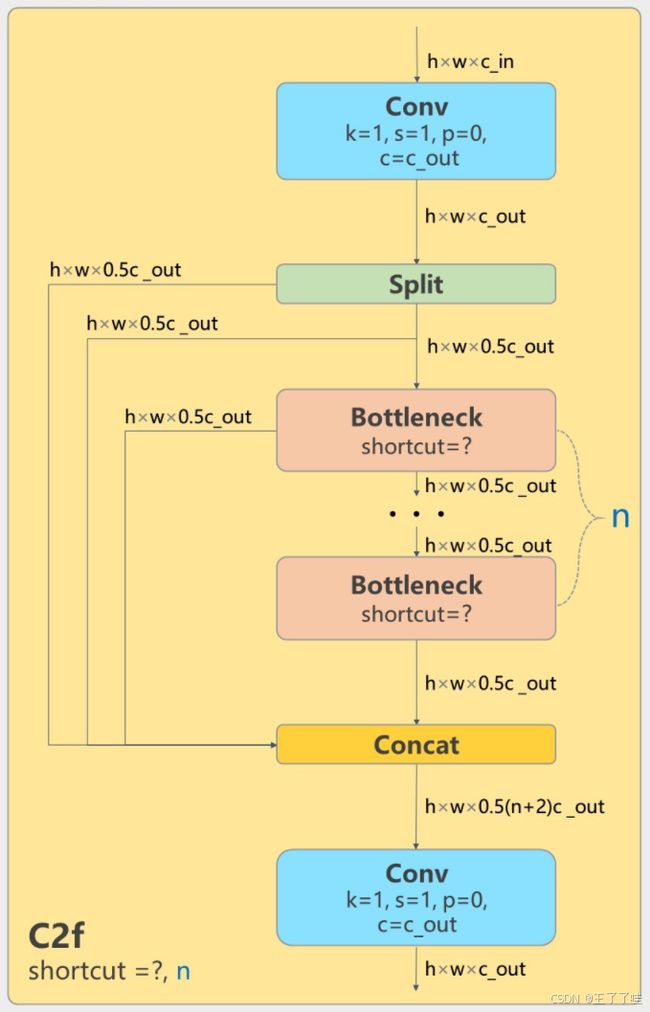
其中C2f的模块结构如下图所示:
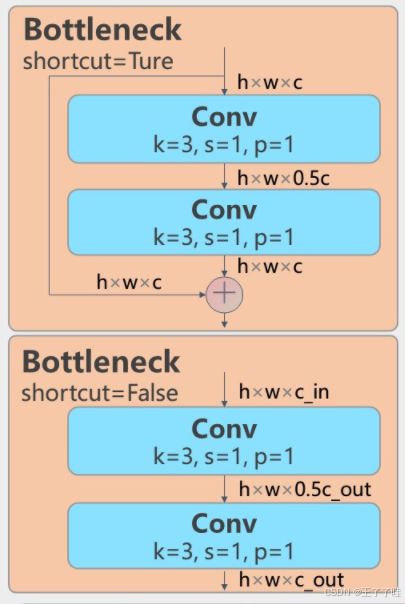
Bottleneck结构如下图所示:
1.C2f模块组成
Conv1: 首先对输入的特征图进行一次卷积,将通道数变为输入通道数的两倍。
Bottleneck:接下来是多个Bottleneck模块,逐步提取特征。每个Bottleneck模块包含多个卷积层,并且可以配置是否使用shortcut连接(残差连接)。
Concat:将多个Bottleneck模块的输出特征图与原始的特征图拼接起来。
Conv2:最后通过一次卷积将拼接后的特征图再进行压缩,输出目标通道数的特征图。
2.C2f模块作用
特征聚合:通过将不同Bottleneck模块的输出和原始特征图拼接在一起,C2F模块能够更好地聚合多尺度信息。
模型压缩:C2F模块中的卷积操作可以有效地压缩特征图,减少计算量,同时保持或增强模型的表达能力。
3.具体流程
Conv1:输入特征图首先经过一个卷积层(通常为1x1卷积)处理,输出的特征图通道数增加一倍。这一步的目的是增加模型的特征表达能力。
Split:在C2f模块内部,输入特征图被一分为二,一部分进入Bottleneck模块,另一部分直接参与后续的拼接。
Bottleneck:经过分割后的特征图在多个Bottleneck模块中逐层处理,提取更深层次的特征。Bottleneck模块可以配置是否使用shortcut连接,用于增强梯度传播和信息流动。
Concat:将所有Bottleneck模块的输出以及之前分割的特征图进行拼接,增加特征的多样性。
Conv2:最终通过一个卷积层将拼接后的特征图通道数压缩到所需的输出通道数,以适应下一步的处理需求。
4.代码实现
C2F模块对应的代码实现是一个基于CSP(Cross Stage Partial)架构的模块,主要包括两个卷积操作(cv1和cv2)和多个Bottleneck模块。通过拼接和卷积操作,实现特征图的聚合与压缩。
具体位置在:ultralytics.nn.models.block.py
C2f代码:
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
Bottleneck代码:
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
5.关键组件和参数说明
1.参数:
c1:输入通道数(ch_in)。
c2:输出通道数(ch_out)。
n:瓶颈块 (Bottleneck) 的数量。
shortcut:是否使用捷径连接(残差连接)。
g:分组卷积的组数(groups)。
e:扩展系数,控制隐藏通道数的比例。
2.组件:
self.c:隐藏通道数,由 c2 和扩展系数 e 计算得到 (self.c = int(c2 * e))。
self.cv1:第一个卷积层,将输入的通道数 c1 转换为 2 * self.c 的通道数。
self.cv2:第二个卷积层,将输入的通道数 ((2 + n) * self.c) 转换为输出通道数 c2。
self.m:一个包含 n 个瓶颈块的模块列表,每个瓶颈块的输入和输出通道数均为 self.c。
6.运行流程
1. init 初始化方法
计算隐藏通道数 self.c。
初始化两个卷积层 cv1 和 cv2。
初始化包含 n 个瓶颈块 (Bottleneck) 的模块列表 self.m。
2. forward 前向传播方法
输入 x 经过第一个卷积层 cv1,得到通道数为 2 * self.c 的张量,并将其在通道维度上分割为两个张量 y。
对分割后的第二个张量依次通过 n 个瓶颈块,将每次的输出继续添加到列表 y 中。
最后,将 y 中所有张量在通道维度上拼接,并通过第二个卷积层 cv2,输出最终结果。
3. forward_split 方法
与 forward 方法类似,不同之处在于,forward_split 使用 split() 方法而非 chunk() 方法来分割张量。split() 允许更灵活的分割方式。
split 函数与 chunk 的不同之处在于,split 是根据指定的每一部分的大小来分割,而 chunk 是将通道均等分割。
7.输入输出示例
假设我们有一个输入张量 x,形状为 (B, c1, H, W),经过 C2f 模块处理后,输出张量的形状将为 (B, c2, H, W),通道数由 c1 变为 c2,而高度和宽度保持不变。
比如:输入张量的形状为 (B, c1, H, W) = (1, 64, 128, 128)
1. 计算隐藏通道数:
self.c = int(c2 * e) = int(128 * 0.5) = 64
self.cv1 = Conv(c1, 2 * self.c, 1, 1) 的输出通道数为 2 * self.c = 128。
2. 第一个卷积层 (cv1):
输入张量 x 的形状为 [1, 64, 128, 128]。
卷积操作将通道数从 64 转换为 128,输出张量的形状为 [1, 128, 128, 128]。
3. chunk 操作:
将输出张量沿着通道维度分成 2 个部分,每个部分的形状为 [1, 64, 128, 128]。
y = list(self.cv1(x).chunk(2, 1)) 的结果是两个张量,y[0] 和 y[1],它们的形状都是 [1, 64, 128, 128]。
4. Bottleneck 层的操作:
self.m 中包含 n=2 个 Bottleneck 层。
通过 y.extend(m(y[-1]) for m in self.m),它在循环中将多个 Bottleneck 层的输出逐步添加到列表 y 中,依次将 y[-1] 作为输入传给每一个 Bottleneck 层,然后将输出添加到列表 y 中。
y[-1] 表示 y 列表中的最后一个元素(即最新的特征图)
m(y[-1]) for m in self.m:这是一个生成器表达式。它遍历 self.m 中的每一个 Bottleneck 层 m,并将 y[-1] 即将 y 列表的最后一个特征图,作为输入传递给这个 Bottleneck 层。每次迭代生成新的特征图。
y.extend(m(y[-1]) for m in self.m)具体过程
假设 self.m 包含 2 个 Bottleneck 层,列表 y 初始状态有 2 个元素(由 self.cv1(x).chunk(2, 1) 产生):
初始 y = [y1, y2],其中 y1 和 y2 是 chunk 分割出来的两个特征图。
-
第一轮循环:
y[-1] 是 y2。
将 y2 输入到 self.m 中的第一个 Bottleneck 层,得到新特征图 y3。
将 y3 添加到列表 y 中,y 变为 [y1, y2, y3]。 -
第二轮循环:
y[-1] 是 y3。
将 y3 输入到 self.m 中的第二个 Bottleneck 层,得到新特征图 y4。
将 y4 添加到列表 y 中,y 最终变为 [y1, y2, y3, y4]。
总结:y.extend(m(y[-1]) for m in self.m) 这一行代码的作用是,遍历 self.m 中的所有 Bottleneck 层,将每个 Bottleneck 层的输出依次添加到列表 y 中。每次迭代时,都会使用列表中最新的特征图(y[-1])作为输入,生成新的特征图,并将其附加到 y 的末尾。这种方式有效地逐步构建了包含多个特征图的列表,为后续的特征图拼接操作 (torch.cat(y, 1)) 做准备。
每个 Bottleneck 层的输入和输出形状都是 [1, 64, 128, 128]。
5.通道拼接:
torch.cat(y, 1) 将 y 列表中的所有张量沿着通道维度进行拼接。
经过 Bottleneck 层后,y 列表中包含 2 + n = 4 个张量,每个张量的形状都是 [1, 64, 128, 128]。
拼接后的张量形状为 [1, 256, 128, 128]。
6.第二个卷积层 (cv2):
最后通过 self.cv2 将通道数从 256 转换为 c2 = 128。
输出张量的形状为 [1, 128, 128, 128]。
输入: [1, 64, 128, 128]
cv1 输出: [1, 128, 128, 128]
chunk 分割: [1, 64, 128, 128] 和 [1, 64, 128, 128]
Bottleneck 层处理: [1, 64, 128, 128] → [1, 64, 128, 128](重复 n 次)
拼接后的形状: [1, 256, 128, 128]
cv2 输出: [1, 128, 128, 128]