Hive学习之动态分区及HQL
Hive动态分区
1、首先创建一个分区表
create table t10(name string)
partitioned by(dt string,value string)
row format delimited fields terminated
by '\t' lines terminated by '\n'
stored as textfile;
2、然后对hive进行设置,使之支持动态分区,
set hive.exec.dynamic.partition.mode=nonstrict;
如果限制是strict,则必须有一个静态分区,且放在最前面
set hive.exec.dynamic.partition.mode=strict;
3、最后向t10表中插入数据,同时指定分区
insert overwrite table t10 partition(dt='2014010090',value)
select '34' as name,addr as value from t9;
HQL函数
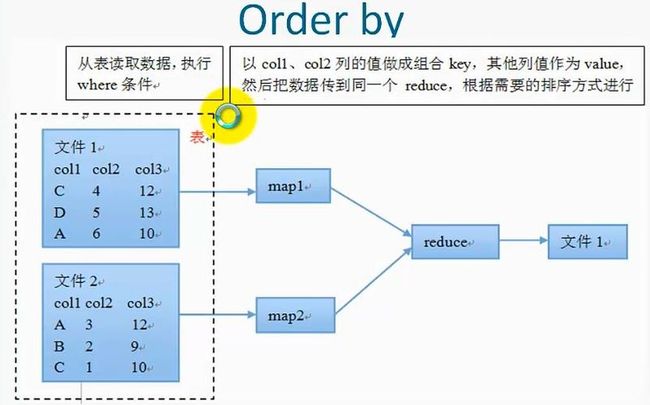
1、order by
按照某些字段进行排序,例如:select clol,clo2... from table_name where condition order by clo1,clo2[asc|desc];order by 后面可以对多列进行排序,默认按照字典进行排序,order by为全局排序,它需要reduce操作,并且只有一个reduce,和配置没有关系
假如表t2中的数据格式为:
id name
1 zhangsan
2 lisi
3 wangwu
4 sunfei
5 cuiying
对此进行语句:select * from t2 order by id desc,name asc;
对第一列进行降序排列,对第二列进行升序排列。由于order by是全局排序,并且只使用了一个reduce,所以在实际应用中应该尽量少使用order by进行排序
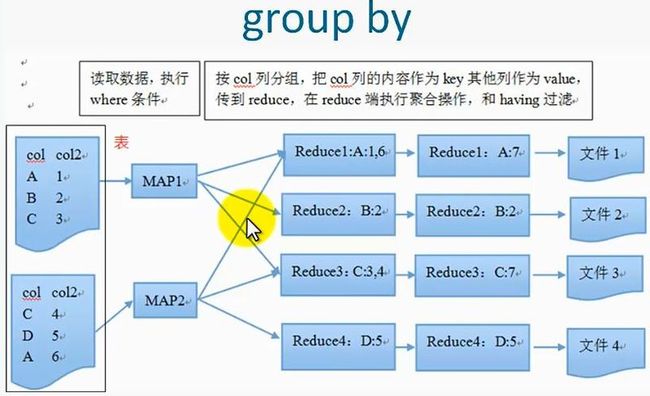
2、group by
按照某些字段的值进行分组,将相同的值放在一起
select col1[,col2],count(),sel_expr(聚合操作)
from table
where condition
group by col1[,col2]
[having]
注意,select后面非聚合列必须出现在group by中,除了普通列就是一些聚合操作,group by后面也可以跟表达式,比如substr(col)
同时,group by 使用了reduce操作,受限于reduce的数量,设置reduce的数量可以mapred.reduce.tasks,输出文件个数和reduce的个数
相同,文件大小与reduce处理的数据量有关,在实际应用过程中,它存在一些问题,如网络负载过重以及数据倾斜(在处理数据过程中,从map到reduce的过程是按照key值进行划分,
由key值决定文件是由哪个reduce来执行,假如某一个reduce中处理的key过多,即就是某一个reduce处理任务过多,执行时间过长,导致整个Job作业执行时间过长,在其他reduce任务已经完成后,
这个处理过多reduce的任务会严重拖慢整体任务的完成时间,这就是数据倾斜,可以通过将
hive.groupby.skewindata参数设置为true,hive自动启动优化程序来避免数据倾斜)等问题。
例如:set mapred.reduce.tasks=5;
set hive.groupby.skewindata=true;//数据倾斜时候可以使用
select country,count(1) as num from info group by country;
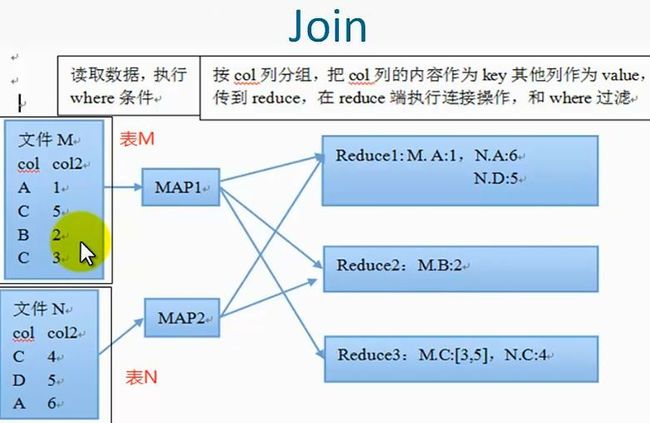
3、join
两个表m,n之间按照On条件进行连接,m中的一条记录和n中的一条记录组成一条新纪录,它是等值连接,只有某个值在m和n中同时存在的时候才可以进行连接操作,left outer join 左边外接,左边
表中的值无论是否在b中存在的时候,都输出,右边表中的值只有在左边表中存在的时候才输出,left outer join则相反,left semi join的作用类似于exits, mapjoin则是在map端完成join操作,
不需要reduce,基于内存做join,属于优化操作
例如:
a表: b表:
co1 co2 co3 co4
1 w 1 f
3 e 1 g
5 r 4 j
对a和b表执行语句:
select s.co1,s.co2,t.co4
from
(select col from a where ...(map端执行))s(左表)
join
(select col from b)t(右表)
on s.co1 = t.co3
where condition(reduce端执行)
其结果为:
1 w f
1 w g
5 e j
执行过程是:对于a表中的每一行数据,在b表中进行遍历,如果查找到相同的则提取这一样存在一个新表中。
如果将join修改为:left outer join 则执行结果为:
1 w f
1 w g
5 e j
3 r null
执行原则是:key值必须在a表中存在,但可以不在b表中存在
如果将join修改为:right outer join 则执行结果为:
1 w f
1 w g
5 e j
2 null p
执行原则是:key值必须在b表中存在,但可以不在a表中存在
如果将join修改为:left semi join 则执行结果为:
1 w f
5 e j
执行原则是:首先查看a表中的第一条记录,如果在b中存在相同记录则输出a中的记录
4、Mapjoin
Mapjoin在map端把小表加载到内存中,然后读取大表,和内存中的小表完成连接操作,
其中使用了分布缓存技术,它的执行不消耗集群的reduce资源(因为集群的reduce
资源相对短缺),减少了reduce操作,加快程序执行,降低网络负载,但是,它占用
部分内存,所以加载到内存中的表不能过大,因为每个计算节点都会加载一次,同时
会生成较多的小文件。
通过如下配置,hive自动根据sql选择使用common join或者map join
set hive.auto.convert.join=true;
hive.mapjoin.smalltable.filesize默认值为25Mb
还可以手动指定:
select/*+mapjoin(n(表名))*/m.col,m.col2,n.col3 from m
join n
on m.col = n.col
总之,mapjoin的使用场景主要有:
关联操作中有一张表非常小,大表和小表进行关联
不等值的链接操作

5、Hive分桶
(1)对于每一个表或者分区,Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据
范围划分
(2)Hive是针对某一列进行分桶
(3)Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶中
分桶的好处是可以获得更高的查询处理效率,使取样更高效
create table t(id int,name string)
clustered by(id)sorted by(name)into 4 buckets
row format delimited fields terminated by '\t'
stored as textfile;
set hive.enforce.bucketing=true;
6、分桶的使用
select * from t tablesample(bucket 1 out of 2 on id)
这句话的意思是将所有的桶分成两份,然后取其中的一份
bucket join
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge =true;
set hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
连接两个在(包含连接列)相同列张划分了桶的表,可以使用Map端连接(Map-site join)
高效的实现,比如Join操作。对于Join操作两个表有一个相同的列,如果对这两个表都进
桶操作,那么将保存相同列值得桶进行Join操作就可以,可以大大减少Join的数据量
对于Mapd端连接的情况,两个表以相同方式划分桶。处理左边表某个桶的mapper知道右边表
内相匹配的行在对应的桶内。因此,mapper只需要获取那个桶(这只是右边表内存储数据的
一小部分)即可进行连接。这一优化方法并不一定要求两个表的桶的个数相同,两个表的桶
个数是倍数关系也可以。