HiveQL:对数据定义的学习
1.Hive中的数据库:
它是表的一个目录或者命名空间,用来避免表命名冲突,我们通常使用数据库来将生产表组织成逻辑组。
基本命令:
(1)创建一个数据库(如果不存在该数据库):
create database if not exists time;
(2)查看Hive中所包含的所有数据库:
show databases;

注:Hive会为每个数据库创建一个目录,数据库中的表将会以这个数据库目录的子目录形式存储,有一个例外是default数据库中的表,default目录中的表会默认直接存储在hive.metastore.warehouse.dir之下。
我们可以设置属性hive.cli.print.current.db=true来让hive的CLI显示的指出当前工作在哪一个数据库下:
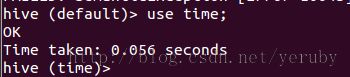
如上,先是在default目录下,使用use time;命令后切换到time数据库下。
2. Hive中数据的保存:
分为元数据、“真实”数据和日志:
(1)元数据:默认情况下,Hive元数据保存在内置的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。为了支持多用户多会
话,则需要一个独立的元数据库,笔者使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
我们可以进入mysql中查看hive中表的元数据:
默认的元数据的表有:

其中主要涉及的表有:

例如:我们在mysql中查看hive元数据信息的TBLS表:

作为对照,我们查看hive中是否存在log表和hive_test表:

注:在hive的安装过程中有三种模式:
内置模式:元数据保持在内嵌的Derby模式,只允许一个会话连接
本地独立模式:在本地安装Mysql,把元数据放到Mysql内
远程模式:元数据放置在远程的Mysql数据库
(2)“真实”数据:存在hdfs上。
(3)日志:存在本地/tmp/${user_name}/hive.log (例如:/tmp/hadoop/hive.log 是笔者的存放路径)
3. Hive中的表:分为内部表(又叫管理表)和外部表。
(1)若创建内部表,会将数据移动到数据仓库指向的路径。在删除内部表的时候,内部表的元数据和数据会被一起删除;
(2)若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变(即数据已经存在hdfs上,新创建的表指向它)。外部表只删除元数据,不删除数据。这样外部表相对来
说更加安全些,数据组织也更加灵活,方便共享源数据。
4. 对表进行分区:
(1)在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因
此建表时引入了partition概念——>更快的查询,提高性能!
(2)分区表指的是在创建表时指定的partition的分区空间。如果需要创建有分区的表,需要在create表的时候调用可选参
partitioned by。
eg:create table employees (name string , salary string) partitioned by (country string , state string);
此时我们只是声明了employees表有分区结构,但还没有创建分区,我们可以通过载入数据的方式创建分区,也可以通过alter命令增加、修改、删除分区。如下笔者使用第一种方法创建分区并上传数据:
eg:load data local inpath '/home/hadoop/extend/data_employees' into table employees partition (country='US',state='CA');

Hive会创建这个分区对应的目录,并上传文件到这个目录下。
注:Hive并不会验证用户装载的数据和表的模式是否匹配。然而,Hive会验证文件格式是否和表结构定义的一致,即如果在表创建时定义的存储格式是SEQUENCEFILE,那么装载进去的文件也必须是sequencefile格式。