智能风控/数据分析 聚合 分组 连接
目录
data。head()查看前几行
配环境添加环境变量
聚合
groupby 方法
基本用法
分组
示例
聚合操作
示例
转换操作
示例
过滤操作
示例
实例方法
示例
总结
apply 方法
结合使用 groupby 和 apply
merge聚合
基本语法
参数说明
【连接键】
DataFrame 示例
内连接(INNER JOIN)
左连接(LEFT JOIN)
右连接(RIGHT JOIN)
真实
全外连接(FULL OUTER JOIN)
示例
内连接(INNER JOIN)
左连接(LEFT JOIN)
右连接(RIGHT JOIN)
外连接(FULL OUTER JOIN)
使用索引进行连接
添加合并指示器
注意事项
data。head()查看前几行
data.head() 是一个在Python的Pandas库中常用的方法,用于查看DataFrame对象的前几行数据。默认情况下,head() 方法会返回DataFrame的前5行数据,但是你也可以通过传递一个整数参数来指定返回的行数。
假设data是一个Pandas DataFrame,下面是一个例子来说明data.head()的输出:
import pandas as pd
# 创建一个示例DataFrame
data = pd.DataFrame({
'Column1': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'Column2': ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'],
'Column3': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
})
# 输出DataFrame的前5行
print(data.head())
输出将会是:
Column1 Column2 Column3
0 1 a 0.1
1 2 b 0.2
2 3 c 0.3
3 4 d 0.4
4 5 e 0.5
这个输出展示了data DataFrame的前5行,包括每一列的名称(Column1、Column2、Column3)和对应的值。如果你想要查看更多的行,比如前10行,你可以调用data.head(10)。
配环境添加环境变量
这行代码是Python中用于操作环境变量的一个例子,具体来说,它是在操作系统的环境变量PATH中添加一个新的路径。下面是对这行代码的详细解释:
os.environ是一个Python字典,包含了当前的环境变量。'PATH'是环境变量名,它通常包含了操作系统用来查找可执行文件的目录列表。+=是一个操作符,用于将右侧的值追加到左侧的变量上。os.pathsep是一个字符串,包含了当前操作系统的路径分隔符。在Windows上是分号;,在Unix/Linux上是冒号:。"C:/prog……"是你想要添加到PATH环境变量中的新路径。这里应该是"C:/prog……"(使用正斜杠/而不是冒号:),因为冒号在Python字符串中是转义字符的起始符号,而且Windows路径通常使用反斜杠\,但这里可能是由于格式错误或简写。
因此,这行代码的意思是将"C:/prog……"(假设是"C:/Program Files/SomeDirectory"或类似的正确路径)添加到当前的环境变量PATH中。这样,当你尝试运行某个程序时,操作系统就会在新增的这个目录中查找可执行文件。
需要注意的是,这种修改只会在当前Python脚本运行的环境中生效,并不会永久改变系统的环境变量。如果想要永久修改环境变量,你需要通过操作系统的设置来进行。
另外,这行代码中路径的写法有误,正确的写法应该是:
import os
os.environ['PATH'] += os.pathsep + "C:\\Program Files\\SomeDirectory"
这里使用了双反斜杠\\来转义反斜杠字符,因为在Python字符串中反斜杠是转义字符。如果你使用原始字符串(在字符串前加r)r‘str’,则不需要转义反斜杠:
import os
os.environ['PATH'] += os.pathsep + r"C:\Program Files\SomeDirectory"聚合
如下:
python
gn = pd.DataFrame()
for i in agg_list:
# 计算个数
tp = pd.DataFrame(df.groupby('uid').apply(lambda df:len(df[i])).reset_index())
tp.columns = ['uid',i + '_cnt']
if gn.empty == True:
gn = tp
else:
gn = pd.merge(gn, tp, on='uid', how='left')
# 求历史特征值大于0的个数
tp = pd.DataFrame(df.groupby('uid').apply(lambda df:np.where(df[i]>0,1,0).sum()).reset_index())
tp.columns = ['uid',i +'_num']
if gn.empty == True:
gn = tp
else:
gn = pd.merge(gn, tp, on='uid', how='left')
# 对历史数据求和
tp = pd.DataFrame(df.groupby('uid').apply(lambda df:np.nansum(df[i]).reset_index()))
tp.columns = ['uid',i +'_tot']
if gn.empty == True:
gn = tp
else:
gn = pd.merge(gn, tp, on='uid', how='left')
这段代码的主要功能是对一个DataFrame (df) 进行一系列聚合操作,并将结果合并到一个新的DataFrame (gn) 中。下面是每一步的解释:
- 初始化一个新的空的DataFrame
gn,用来存储最终的聚合结果。 - 对于每个指定的列名列表 (
agg_list),执行以下操作:- 使用
groupby和apply方法计算每个uid的特定列值的数量,并将其重置索引后添加到临时DataFrametp中。 - 如果
gn是空的,则直接将tp赋值给gn;否则,通过左连接的方式将tp合并到gn中。 - 更新
tp以计算每个uid的特定列值大于0的数量,同样地将其合并到gn中。 - 最后,对每个
uid的特定列值进行求和,并将结果合并到gn中。
- 使用
这个过程的目的是为了从原始数据中提取出一些统计指标,如计数、非零值的数量以及总和等,以便于后续的分析或建模工作。
在Pandas库中,groupby 和 apply 是进行数据分组和操作的两个非常强大的函数。以下是它们如何协同工作的详细说明:
groupby 方法
groupby 方法用于将DataFrame按照一个或多个键(通常是列名)进行分组。它可以让你对每个组应用不同的操作,比如聚合、转换或过滤。
基本语法如下:
df.groupby(key_or_keys)
其中 key_or_keys 可以是单个列名,也可以是列名列表。
groupby 是 Pandas 库中一个非常重要的功能,它允许用户根据某些标准将数据分组,并对每个组应用函数。以下是 groupby 用法的详细描述:
基本用法
分组
要对 DataFrame 进行分组,可以使用以下语法:
df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False, **kwargs)
by: 用于分组的键,可以是列名、列名的列表、字典或者函数。axis: 分组依据的轴,默认为 0(行)。level: 如果 DataFrame 是多级索引(MultiIndex),则可以根据索引的级别进行分组。as_index: 默认为 True,表示结果中的分组键作为索引。如果设置为 False,则分组键将作为列。sort: 默认为 True,表示对分组键进行排序。如果设置为 False,则不排序。group_keys: 默认为 True,表示将分组的键添加到聚合后数据的索引中。squeeze: 如果可能,减少结果到一个系列。observed: 默认为 False,如果为 True 且分组键是索引,则只显示观测到的唯一值。
示例
python
复制
import pandas as pd
# 创建一个简单的 DataFrame
data = {
'key': ['A', 'B', 'C', 'A', 'B', 'C', 'A', 'B'],
'data1': [0, 5, 10, 15, 20, 25, 30, 35],
'data2': [1, 2, 3, 4, 5, 6, 7, 8]
}
df = pd.DataFrame(data)
# 使用 groupby 按照列 'key' 进行分组
grouped = df.groupby('key')
聚合操作
分组后,通常会对每个组应用聚合操作,如求和、平均、最大值等。
示例
python
复制
# 对每个组应用多个聚合函数
result = grouped.agg({
'data1': 'sum',
'data2': 'mean'
})
# 或者分别对每个列应用聚合函数
result = grouped['data1'].sum()
result2 = grouped['data2'].mean()
转换操作
除了聚合,还可以对每个组应用转换操作,返回一个与原始 DataFrame 形状相同的 DataFrame。
示例
python
复制
# 对每个组的数据进行标准化
def normalize(group):
return (group - group.mean()) / group.std()
result = grouped.transform(normalize)
过滤操作
可以使用 filter 方法根据某些条件过滤分组。
示例
python
复制
# 过滤出 'data1' 列总和大于 30 的组
result = grouped.filter(lambda x: x['data1'].sum() > 30)
实例方法
groupby 对象还提供了许多实例方法,如 sum、mean、size 等,可以直接调用这些方法进行聚合。
示例
python
复制
# 计算每个组的大小
result = grouped.size()
# 计算每个组的总和
result = grouped.sum()
总结
groupby 是一个非常灵活和强大的工具,可以用于执行复杂的分组、聚合和转换操作。理解其基本用法和各种选项可以帮助你在数据分析中更有效地处理数据。
apply 方法
apply 方法用于对 groupby 创建的每个组应用一个函数。这个函数可以是Pandas内置的聚合函数,如 sum、mean 等,也可以是自定义的函数。
基本语法如下:
grouped.apply(func)
其中 func 是你想要应用到每个组的函数。
结合使用 groupby 和 apply
以下是如何结合使用 groupby 和 apply 来计算每个 uid 的特定列值的数量的步骤:
-
分组:首先,使用
groupby方法根据uid列对DataFrame进行分组。grouped = df.groupby('uid') -
应用函数:然后,对每个分组应用一个函数。这个函数计算每个组中特定列值的数量。在示例中,这个函数是
lambda函数,它使用len函数来计算每个组的大小。result = grouped.apply(lambda df: len(df[i]))这里
df[i]表示分组后的每个子DataFrame的特定列i。 -
重置索引:由于
groupby操作会创建一个多级索引,通常需要使用reset_index方法将结果转换回标准的DataFrame格式。回头
result = result.reset_index() -
列名重命名:最后,你可能需要重命名结果DataFrame的列名,使其更具可读性。
result.columns = ['uid', i + '_cnt']
整个操作可以写为:
tp = pd.DataFrame(df.groupby('uid').apply(lambda df: len(df[i])).reset_index())
tp.columns = ['uid', i + '_cnt']
这里,tp 是一个临时DataFrame,它包含了每个 uid 的特定列 i 的数量统计。这个过程对于每个在 agg_list 中的列都会执行一次,然后将这些统计信息合并到一个总的DataFrame gn 中。
merge聚合
merge 是 Pandas 库中用于数据集合并的函数,类似于 SQL 中的 JOIN 操作。它可以根据一个或多个键将不同的 DataFrame 对象按指定的方式进行连接。以下是 merge 方法的详细描述:
基本语法
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'),
copy=True, indicator=False, validate=None)
参数说明
left: 第一个 DataFrame 对象。right: 第二个 DataFrame 对象。how: 要执行的合并类型,可以是 ‘left’, ‘right’, ‘outer’ (或 ‘full’), ‘inner’。默认为 ‘inner’。- ‘left’: 类似于 SQL 中的 LEFT OUTER JOIN,使用左侧 DataFrame 的键。
- ‘right’: 类似于 SQL 中的 RIGHT OUTER JOIN,使用右侧 DataFrame 的键。
- ‘outer’ 或 ‘full’: 类似于 SQL 中的 FULL OUTER JOIN,合并两个 DataFrame 的键。
- ‘inner’: 类似于 SQL 中的 INNER JOIN,只合并两个 DataFrame 共有的键。
on: 用于连接的列名。如果未指定,并且没有设置left_on和right_on,则使用两个 DataFrame 中共同列名的交集。left_on: 左侧 DataFrame 中用作连接键的列。right_on: 右侧 DataFrame 中用作连接键的列。-
【连接键】
- 在数据库和数据科学中,“连接键”是指在执行数据表之间的连接操作时所使用的字段。这个字段通常存在于两个或多个需要连接的表中,通过该字段的值来关联相应的记录。
用作连接键的列通常是那些能够唯一标识一条记录的字段,如主键、外键等。在实际应用中,选择哪个列作为连接键取决于具体的业务需求和数据结构。 -
连接键(Join Key)是数据库管理系统中用来连接两个或多个关系表的字段。当您想要从多个表中检索相关联的信息时,通常会使用连接键来实现这一点。连接键可以是单个字段,也可以是多个字段的组合,只要这些字段能够在不同的表中唯一标识相关的记录即可。
在SQL查询中,连接键通常出现在JOIN子句中,用于指定哪些字段应该被匹配以连接表。例如,如果您有一个客户表和一个订单表,并且这两个表都有一个“CustomerID”字段,那么您就可以使用这个字段作为连接键来连接这两个表,从而检索出每个客户的订单信息。
除了简单的相等比较之外,连接键还可以用于更复杂的条件匹配,例如范围匹配或模糊匹配。此外,连接键并不一定要在所有参与连接的表中都存在;在某些情况下,您可能只需要在一个表中定义连接键,然后在另一个表中使用ON子句来指定如何将这个键与第一个表中的数据进行匹配。
总之,连接键是数据库管理和数据处理中的一个重要概念,它允许您以一种有效的方式整合来自不同来源的数据,以便更好地分析和利用这些信息。
-
让我们通过一个具体的例子来解释 Pandas 中的
merge方法是如何工作的。假设我们有两个 DataFrame,一个是关于客户的信息,另一个是关于订单的信息。DataFrame 示例
首先,我们创建两个简单的 DataFrame:
import pandas as pd # 客户信息 DataFrame customers_df = pd.DataFrame({ 'CustomerID': [1, 2, 3, 4], 'CustomerName': ['Alice', 'Bob', 'Charlie', 'David'] }) # 订单信息 DataFrame orders_df = pd.DataFrame({ 'OrderID': [100, 101, 102, 103], 'CustomerID': [1, 2, 3, 5], 'OrderAmount': [200, 150, 300, 250] })内连接(INNER JOIN)
现在,我们想要将这两个 DataFrame 合并,以便我们可以看到每个客户的订单金额。由于我们想要只包含在两个 DataFrame 中都存在的记录,我们将使用内连接。
# 使用内连接合并 DataFrame merged_inner = pd.merge(customers_df, orders_df, on='CustomerID', how='inner') print(merged_inner)输出将是:
CustomerID CustomerName OrderID OrderAmount 0 1 Alice 100 200 1 2 Bob 101 150 2 3 Charlie 102 300在这个例子中,我们使用
on='CustomerID'来指定连接键,how='inner'表示我们想要进行内连接。内连接只包含两个 DataFrame 中都有的CustomerID。左连接(LEFT JOIN)
如果我们想要保留左侧 DataFrame(customers_df)中的所有记录,即使它们在右侧 DataFrame(orders_df)中没有匹配的记录,我们将使用左连接。
# 使用左连接合并 DataFrame merged_left = pd.merge(customers_df, orders_df, on='CustomerID', how='left') print(merged_left)输出将是:
CustomerID CustomerName OrderID OrderAmount 0 1 Alice 100.0 200 1 2 Bob 101.0 150 2 3 Charlie 102.0 300 3 4 David NaN NaN在这个例子中,
CustomerID为 4 的 David 在订单 DataFrame 中没有匹配的记录,因此在合并后的 DataFrame 中,OrderID和OrderAmount列的值为 NaN。右连接(RIGHT JOIN)
如果我们想要保留右侧 DataFrame(orders_df)中的所有记录,即使它们在左侧 DataFrame(customers_df)中没有匹配的记录,我们将使用右连接。
python
# 使用右连接合并 DataFrame merged_right = pd.merge(customers_df, orders_df, on='CustomerID', how='right') print(merged_right)输出将是:
CustomerID CustomerName OrderID OrderAmount 0 1 Alice 100.0 200 1 2 Bob 101.0 150 2 3 Charlie 102.0 300 3 5 NaN 103.0 250在这个例子中,
CustomerID为 5 的记录在客户 DataFrame 中没有匹配的记录,因此在合并后的 DataFrame 中,CustomerName列的值为 NaN。 -
真实
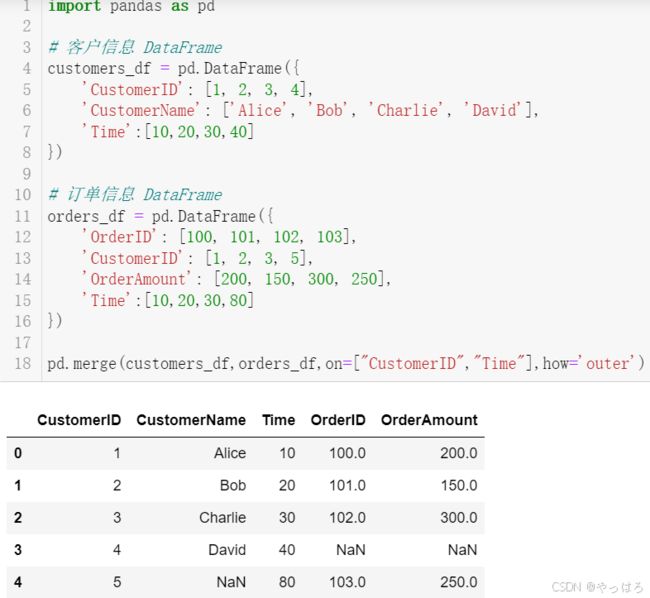
-

全外连接(FULL OUTER JOIN)
如果我们想要保留两个 DataFrame 中的所有记录,即使它们在另一个 DataFrame 中没有匹配的记录,我们将使用全外连接。
python
# 使用全外连接合并 DataFrame merged_full = pd.merge(customers_df, orders_df, on='CustomerID', how='outer') print(merged_full)输出将是:
CustomerID CustomerName OrderID OrderAmount 0 1 Alice 100.0 200 1 2 Bob 101.0 150 2 3 Charlie 102.0 300 3 4 David NaN NaN 4 5 NaN 103.0 250在这个例子中,我们得到了两个 DataFrame 中所有的记录,没有匹配的记录在相应的列中用 NaN 表示。
这些例子展示了如何使用 Pandas 的
merge方法来执行不同类型的数据库风格的连接操作。 -
実は——
left_index: 如果为 True,则使用左侧 DataFrame 的索引(行标签)作为其连接键。在多索引(MultiIndex)的情况下,级别数必须与右侧 DataFrame 的连接键数匹配。right_index: 如果为 True,则使用右侧 DataFrame 的索引(行标签)作为其连接键。sort: 根据连接键对合并后的数据进行排序,默认为 False。suffixes: 字符串元组,用于追加到重叠列名的末尾。默认为 (‘_x’, ‘_y’)。copy: 默认为 True,总是复制数据。如果为 False,则尽可能避免复制数据,但可能会更改输入的 DataFrame。indicator: 如果为 True,则添加一个特殊列_merge,显示每行的来源(‘left_only’, ‘right_only’, ‘both’)。validate: 指定要验证的合并类型,例如 ‘one_to_one’ 或 ‘one_to_many’。
示例
假设我们有以下两个 DataFrame:
import pandas as pd
df1 = pd.DataFrame({
'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]
})
df2 = pd.DataFrame({
'key': ['B', 'D', 'D', 'E'],
'value': [5, 6, 7, 8]
})
内连接(INNER JOIN)
python
复制
result_inner = pd.merge(df1, df2, on='key', how='inner')
左连接(LEFT JOIN)
python
复制
result_left = pd.merge(df1, df2, on='key', how='left')
右连接(RIGHT JOIN)
python
复制
result_right = pd.merge(df1, df2, on='key', how='right')
外连接(FULL OUTER JOIN)
python
复制
result_outer = pd.merge(df1, df2, on='key', how='outer')
使用索引进行连接
python
复制
# 假设 df1 和 df2 的索引分别是 ['A', 'B', 'C', 'D'] 和 ['B', 'C', 'D', 'E']
result_index = pd.merge(df1, df2, left_index=True, right_index=True, how='inner')
添加合并指示器
python
复制
result_indicator = pd.merge(df1, df2, on='key', how='outer', indicator=True)
注意事项
- 当两个 DataFrame 中有多个共同列名时,使用
on参数指定要连接的列。 - 如果 DataFrame 中的列名不同,但你想基于这些列进行连接,可以使用
left_on和right_on参数。 - 使用
suffixes参数可以避免合并后列名冲突的问题。 - 合并大型数据集时,确保理解不同的
how参数对性能的影响。
merge 方法是 Pandas 中进行数据集合并的强大工具,正确使用它可以帮助你高效地处理复杂数据操作。