哈夫曼树
最优二叉树
1.树的路径长度
树的路径长度是从树根到树中每一结点的路径长度之和。在结点数目相同的二叉树中,完全二叉树的路径长度最短。
2.树的带权路径长度(Weighted Path Length of Tree,简记为WPL)
结点的权:在一些应用中,赋予树中结点的一个有某种意义的实数。
结点的带权路径长度:结点到树根之间的路径长度与该结点上权的乘积。
树的带权路径长度(Weighted Path Length of Tree):定义为树中所有叶结点的带权路径长度之和,通常记为: ![]()
其中: n表示叶子结点的数目 wi和li分别表示叶结点ki的权值和根到结点ki之间的路径长度。
树的带权路径长度亦称为树的代价。
3.最优二叉树或哈夫曼树
在权为wl,w2,…,wn的n个叶子所构成的所有二叉树中,带权路径长度最小(即代价最小)的二叉树称为最优二叉树或哈夫曼树。
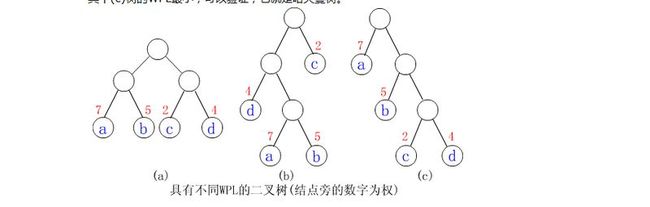
【例】给定4个叶子结点a,b,c和d,分别带权7,5,2和4。构造如下图所示的三棵二叉树(还有许多棵),它们的带权路径长度分别为: (a)WPL=7*2+5*2+2*2+4*2=36 (b)WPL=7*3+5*3+2*1+4*2=46 (c)WPL=7*1+5*2+2*3+4*3=35
其中(c)树的WPL最小,可以验证,它就是哈夫曼树。
注意: ① 叶子上的权值均相同时,完全二叉树一定是最优二叉树,否则完全二叉树不一定是最优二叉树。
② 最优二叉树中,权越大的叶子离根越近。
③ 最优二叉树的形态不唯一,WPL最小
构造最优二叉树
1.哈夫曼算法
哈夫曼首先给出了对于给定的叶子数目及其权值构造最优二叉树的方法,故称其为哈夫曼算法。其基本思想是:
(1)根据给定的n个权值wl,w2,…,wn构成n棵二叉树的森林F={T1,T2,…,Tn},其中每棵二叉树Ti中都只有一个权值为wi的根结点,其左右子树均空。
(2)在森林F中选出两棵根结点权值最小的树(当这样的树不止两棵树时,可以从中任选两棵),将这两棵树合并成一棵新树,为了保证新树仍是二叉树,需要增加一个新结点作为新树的根,并将所选的两棵树的根分别作为新根的左右孩子(谁左,谁右无关紧要),将这两个孩子的权值之和作为新树根的权值。
(3)对新的森林F重复(2),直到森林F中只剩下一棵树为止。这棵树便是哈夫曼树。 用哈夫曼算法构造哈夫曼树的过程见【动画演示】。
注意: ① 初始森林中的n棵二叉树,每棵树有一个孤立的结点,它们既是根,又是叶子
② n个叶子的哈夫曼树要经过n-1次合并,产生n-1个新结点。最终求得的哈夫曼树中共有2n-1个结点。 ③ 哈夫曼树是严格的二叉树,没有度数为1的分支结点。
2.哈夫曼树的存储结构及哈夫曼算法的实现
(1) 哈夫曼树的存储结构 用一个大小为2n-1的向量来存储哈夫曼树中的结点,其存储结构为:
#define n 100 //叶子数目
#define m 2*n-1//树中结点总数
typedef struct
{ //结点类型 float weight; //权值,不妨设权值均大于零
int lchild,rchild,parent; //左右孩子及双亲指针
}HTNode;
typedef HTNode HuffmanTree[m];
//HuffmanTree是向量类型
注意: 因为C语言数组的下界为0,故用-1表示空指针。树中某结点的lchild、rchild和parent不等于-1时,它们分别是该结点的左、右孩子和双亲结点在向量中的下标。
这里设置parent域有两个作用:其一是使查找某结点的双亲变得简单;其二是可通过判定parent的值是否为-1来区分根与非根结点。
(2)哈夫曼算法的简要描述
在上述存储结构上实现的哈夫曼算法可大致描述为(设T的类型为HuffmanTree):
(1)初始化 将T[0..m-1]中2n-1个结点里的三个指针均置为空(即置为-1),权值置为0。
(2)输人 读人n个叶子的权值存于向量的前n个分量(即T[0..n-1])中。它们是初始森林中n个孤立的根结点上的权值。
(3)合并 对森林中的树共进行n-1次合并,所产生的新结点依次放人向量T的第i个分量中(n≤i≤m-1)。
每次合并分两步: ①在当前森林T[0..i-1]的所有结点中,选取权最小和次小的两个根结点[p1]和T[p2]作为合并对象,这里0≤p1,p2≤i-1。
② 将根为T[p1]和T[p2]的两棵树作为左右子树合并为一棵新的树,新树的根是新结点T[i]。具体操作: 将T[p1]和T[p2]的parent置为i, 将T[i]的lchild和rchild分别置为p1和p2 新结点T[i]的权值置为T[p1]和T[p2]的权值之和。
注意: 合并后T[pl]和T[p2]在当前森林中已不再是根,因为它们的双亲指针均已指向了T[i],所以下一次合并时不会被选中为合并对象。
哈夫曼算法模拟演示过程【参见动画模拟】
(3)哈夫曼算法的求精 v
oid CreateHuffmanTree(HuffmanTree T)
{//构造哈夫曼树,T[m-1]为其根结点
int i,p1,p2;
InitHuffmanTree(T); //将T初始化
InputWeight(T); //输入叶子权值至T[0..n-1]的weight域
for(i=n;i<m;i++){//共进行n-1次合并,新结点依次存于T[i]中
SelectMin(T,i-1,&p1,&p2); //在T[0..i-1]中选择两个权最小的根结点,其序号分别为p1和p2
T[p1].parent=T[p2].parent=i; TIi].1child=p1; //最小权的根结点是新结点的左孩子 T[j].rchild=p2; //次小权的根结点是新结点的右孩子
T[i].weight=T[p1].weight+T[p2].weight;
} // end for
}
上述算法中调用的三个函数【参见练习】。
【例】以7个权值:7,5,1,4,8,10,20为例,执行CreateHuffmanTree求最优二叉树的过程【参见动画模拟】
哈夫曼编码:
1. 编码和解码
数据压缩过程称为编码。即将文件中的每个字符均转换为一个惟一的二进制位串。 数据解压过程称为解码。即将二进制位串转换为对应的字符。
根据最优二叉树构造哈夫曼编码
利用哈夫曼树很容易求出给定字符集及其概率(或频度)分布的最优前缀码。哈夫曼编码正是一种应用广泛且非常有效的数据压缩技术。该技术一般可将数据文件压缩掉20%至90%,其压缩效率取决于被压缩文件的特征。
1. 具体做法
(1)用字符ci作为叶子,pi或fi做为叶子ci的权,构造一棵哈夫曼树,并将树中左分支和右分支分别标记为0和1;
(2)将从根到叶子的路径上的标号依次相连,作为该叶子所表示字符的编码。该编码即为最优前缀码(也称哈夫曼编码)。
2. 哈夫曼编码为最优前缀码
由哈夫曼树求得编码为最优前缀码的原因:
① 每个叶子字符ci的码长恰为从根到该叶子的路径长度li,平均码长(或文件总长)又是二叉树的带权路径长度WPL。而哈夫曼树是WPL最小的二叉树,因此编码的平均码长(或文件总长)亦最小。
② 树中没有一片叶子是另一叶子的祖先,每片叶子对应的编码就不可能是其它叶子编码的前缀。即上述编码是二进制的前缀码。
3. 求哈夫曼编码的算法
(1)思想方法
给定字符集的哈夫曼树生成后,求哈夫曼编码的具体实现过程是:依次以叶子T[i](0≤i≤n-1)为出发点,向上回溯至根为止。上溯时走左分支则生成代码0,走右分支则生成代码1。
注意:
① 由于生成的编码与要求的编码反序,将生成的代码先从后往前依次存放在一个临时向量中,并设一个指针start指示编码在该向量中的起始位置(start初始时指示向量的结束位置)。
② 当某字符编码完成时,从临时向量的start处将编码复制到该字符相应的位串bits中即可。
③ 因为字符集大小为n,故变长编码的长度不会超过n,加上一个结束符'\0',bits的大小应为n+1。
(2)字符集编码的存储结构及其算法描述
typedef struct
{
char ch; //存储字符
char bits[n+1]; //存放编码位串
}CodeNode;
typedef CodeNode HuffmanCode[n];
void CharSetHuffmanEncoding(HuffmanTree T,HuffmanCode H)
{//根据哈夫曼树T求哈夫曼编码表H
int c,p,i;//c和p分别指示T中孩子和双亲的位置
char cd[n+1]; //临时存放编码
int start; //指示编码在cd中的起始位置
cd[n]='\0'; //编码结束符
for(i=0,i<n,i++)
{ //依次求叶子T[i]的编码
H[i].ch=getchar();//读入叶子T[i]对应的字符
start=n; //编码起始位置的初值
c=i; //从叶子T[i]开始上溯
while((p=T[c].parent)>=0)
{//直至上溯到T[c]是树根为止
//若T[c]是T[p]的左孩子,则生成代码0;否则生成代码1
cd[--start]=(T[p).1child==C)?'0':'1';
c=p; //继续上溯
}
strcpy(H[i].bits,&cd[start]); //复制编码位串
}//endfor
}//CharSetHuffmanEncoding
文件的编码和解码
有了字符集的哈夫曼编码表之后,对数据文件的编码过程是:依次读人文件中的字符c,在哈夫曼编码表H中找到此字符,若H[i].ch=c,则将字符c转换为H[i].bits中存放的编码串。
对压缩后的数据文件进行解码则必须借助于哈夫曼树T,其过程是:依次读人文件的二进制码,从哈夫曼树的根结点(即T[m-1])出发,若当前读人0,则走向左孩子,否则走向右孩子。
一旦到达某一叶子T[i]时便译出相应的字符H[i].ch。然后重新从根出发继续译码,直至文件结束。
文件的编码和解码算法【参见练习】。