c语言 数组散列 高效 HashTable Dictionary
声明:图片转载自@http://www.cnblogs.com/1-2-3/archive/2010/10/25/generic-dictionary-source-part2.html
c语言 数组散列 高效 HashTable Dictionary ,不管集合大小,任意长度根据key查询都最快一次寻址,so 最快时间复杂度为O1!
目的:
首先了解需求,我们要的是一个Dictionary,字典,就是一个 <key,value>集合,
要求:
根据key查找时间复杂度很低!很快!
而且我们需要删除的方法,时间复杂度很低!很快!
准备:
首先我们来了解hash,就是散列, hash ——>就是把任意长度的输入,通过算法,变换成固定长度的输出,该输出就是散列值”!
int GetHashCode(char* str)
{
int hashcode=0;
char *p;
for(p=str; *p; p++){
hashcode = hashcode*CM_STR_HASHFUNC_CONSTANT + *p;
}
return hashcode;
}
以上方法实现了输入字符串得到一个数值的功能,但是并不是定长!,定长的标准hash算法有很多,你可以google,比如MD5~
@http://page.renren.com/601301709/note/818040393
这是一个简单的获取hash的方法!c#或者其他语言很容易得到一个对象的hash!c#: object.gethashcode();
然后我们来说碰撞:
碰撞就是hash算法里面两个不同的输入,得到的hash输出是一样的,这就称之为碰撞!比如MD5理论上是不会发生碰撞的!
重点:
我们知道计算机查找集合里面数组是最快的,因为数组内存是连续存储的,直接根据计算的地址得到值,
char * name="dark89757"; char _4=name[3];
name[3]=>name首地址+3 内存取值为sizeof(char)!
我们现在有一个keyvalue型列表。每行都是<key,value>,我们想让这个字典列表集合也拥有数组差不多的查找优势!
但是,我们的key不是内存地址!
没事,一步一步来,
不是有hash吗?我们可以计算出key的hash,
通过文中的gethashcode,我们可以得到一个key(字符串)的hash,一个数值!
那么我们是不是可以这样做,定义一个超长的数组,数组类型为key value 的value类型,你可以这样 void* data [maxint];
Insert:我们先计算出key的hash,然后根据得到的keyhash,写入数组 ,
Get::同样的,先计算key的hash,然后return data[code];
实现如下
void* data [maxint];
void insert(char *key,void* value)
{
int code=gethashcode(key);
data[code]=value;
}
void* get(char* key)
{
int code=gethashcode(key);
return data[code];
}
但是这样做并不科学,首先是数组太大,可能有些hash值maxint根本没法存!而且开辟的空间大部分都没有,其次是碰撞,如果两个不同key的hash是一样的,是不是就数据丢失了!
人总是聪明的,首先我们来解决第二个问题,
就是两个不同key的hash值一样的问题,我们可以这样做,把数组的值弄成一个链表,
因为c不甚了解了,太慢了,所以用了c#代替写!
class Program
{
class Item
{
public string key = null;
public object value = null;
public Item nextitem;
}
static Item[] data = new Item[Int32.MaxValue];//存储链表的首节头,第一个节点
static int gethashcode(string key)
{
return key.GetHashCode();
}
static void insert(string key, object value)
{
int code = gethashcode(key);
Item keyindex = data[code];
if (data[code] == null)//没有链表
{
keyindex = new Item();
keyindex.key = key;
keyindex.value = value;
data[code] = keyindex;
return;
}
if (keyindex.key == key)//是否和当前新添加key相同
{
keyindex.value = value;
return;
}
while (keyindex.nextitem != null)//循环至尾
{
keyindex = keyindex.nextitem;
}
var temp = new Item();//结尾添加链表节点
keyindex.nextitem = temp;
temp.key = key;
temp.value = value;
return;
}
static object get(string key)
{
int code = gethashcode(key);
Item keyindex = data[code];
while (keyindex != null)//遍历链表节点
{
if (keyindex.key == key)
return keyindex.value;
keyindex = keyindex.nextitem;
}
return null;
}
static void Main(string[] args)
{
insert("123", "123 value~~");
Console.WriteLine(get("123"));
insert("456", "456 value~~");
insert("123", "123 new value~~");
Console.WriteLine(get("123"));
Console.ReadKey();
}
}
以上代码并不能运行,因为maxint的缘故!可以参考下流程,我们把碰撞的hash弄成了一个链表了,这样值完全存贮了,
然后我们来解决下一个问题,原来方案需要开辟N大的空间,根本不实际,可能程序都不会让你开辟maxint的数组,!
然后数学是美好的,记得求余吗?
int hashcode; int qiuyuhashcode=hashcode%100;
这样得到的hash总是在0~99之间的!,说道这里,聪明的人一下就想到了!
我们将以上maxint数组的链表,该成100长度的数组!
将上面的代码改成这样:
// out -》static Item[] data = new Item[Int32.MaxValue];
static int length=100;
static Item[] data = new Item[length];//存储链表的首节头,第一个节点
static int gethashcode(string key)
{
// out -》return key.GetHashCode();
return Math.Abs(key.GetHashCode() % length);
}
再次运行将会成功!这是一个简单的除hash数组!
我们将key的hash求余,这样我们只会有一百个链表,不会有maxint长的链表!
但这并不能实践,首先一个问题是数组只有一百个,如果字典行很多,大概这一百个链表都很长!查找时涉及到的遍历链表这还是会很慢!
然后是删除,这也会遍历链表!还是很慢!
这里还能继续优化,就是我们的数组动态增长,增长判断为插入key的条数,让数组的长度始终大于key的长度,
因为hash碰撞的几率是很小的,我们如果我们有1000个<key,value>,我们就定义1000个数组,可能90%都会只有数组头,另外10%都是除余数的hash碰撞,存在链表尾!
如果你要将上述代码添加动态增长大小方法,有一点别忘了,必须重新排列原来的100个链表,比如增长到1000大小,把key%1000再插入!
这样做完全的提升了删除和查找的速度!
然而问题还有!
我们先看下现在解决方案图:
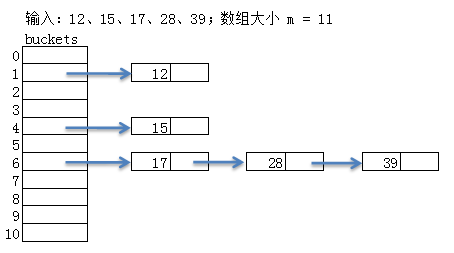
就是这种链表在内存不是连续的,如果你用c/c++写,在内存上插入和删除都需要开辟和释放空间的!
内存池管理,是的,我们把这一百个链表的内存集合起来处理,
假如我有一百个<key,value>,我先定义一百的数组来存链表头的指针,然后定义一百个来放{key,value,nextnode}链表节点!这就是最终hashtable方案!
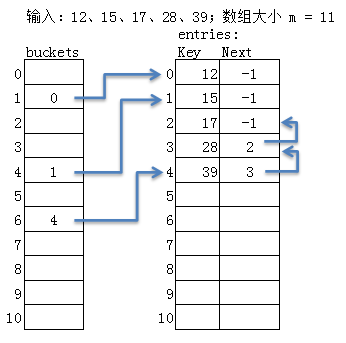
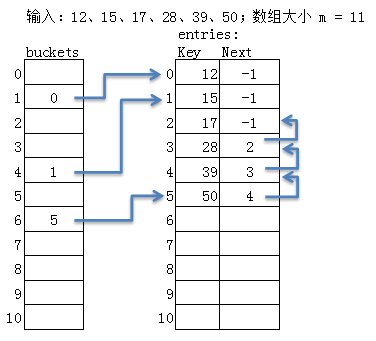
最后一个问题,就是删除,我们定义两个变量,一个是int freecount,删除个数,另一个node freenode; 是链节点 链表头,我们把所有删除的链表都串起来!
下次我添加的时候,先判断free,然后再次利用 freenode这个节点,如果 freenode 的next还有值,我们将这个值赋给 freenode,下次再利用!
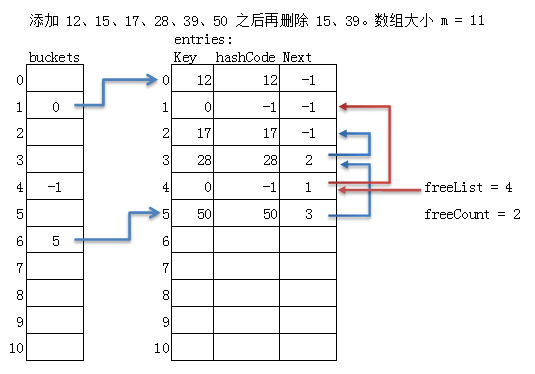
以上就是整个hashtable整个简单讲解!如果你觉得本文对你有些许帮助,请点一下右下角的顶!
下面有我c写的hashtable的实现,附带有测试代码和下载地址。
HashDictionary.h
#define CM_STR_HASHFUNC_CONSTANT 31
#define KEYSIZE 40
struct Entry
{
int hashCode;
int next;
char key[KEYSIZE];
void* value;
};
struct HashDictionary
{
int* buckets;
Entry* entrys;
int bucketslength;
int entryslength;
int count;
int freeList;
int freeCount;
};
static int primes[] = {
3, 7, 11, 17, 23, 29, 37, 47, 59, 71, 89, 107, 131, 163, 197, 239, 293, 353, 431, 521, 631, 761, 919,
1103, 1327, 1597, 1931, 2333, 2801, 3371, 4049, 4861, 5839, 7013, 8419, 10103, 12143, 14591,
17519, 21023, 25229, 30293, 36353, 43627, 52361, 62851, 75431, 90523, 108631, 130363, 156437,
187751, 225307, 270371, 324449, 389357, 467237, 560689, 672827, 807403, 968897, 1162687, 1395263,
1674319, 2009191, 2411033, 2893249, 3471899, 4166287, 4999559, 5999471, 7199369};
//获取hash
int GetHashCode(char* str);
//是否质数
bool IsPrime(int candidate);
//获取>min最近的质数
int GetPrime(int min);
//初始化
void Initialize(HashDictionary* hd);
//初始化
void Initialize(HashDictionary* hd,int capacity);
//释放
void Disponse(HashDictionary* hd);
//重定义大小
void Resize(HashDictionary* hd);
//插入 add如果是true,并且key存在,则返回-1,否则替换新值
int Insert(HashDictionary* hd,char* key,void* value,bool add);
//找到下标 没有返回 -1
int FindEntryIndex(HashDictionary* hd,char* key);
//查找 没有返回null
Entry* FindEntry(HashDictionary* hd,char* key);
//删除 如果没有返回false
bool Remove(HashDictionary* hd,char* key);
//是否含有key
bool ContainsKey(HashDictionary* hd,char* key);
int GetCount(HashDictionary* hd);
void GetAllKey(HashDictionary* hd,char* allkey);
HashDictionary.cpp
#include "stdafx.h"
#include "HashDictionary.h"
#include <malloc.h>
#include <math.h>
#include <limits.h>
#include <string.h>
int GetHashCode(char* str)
{
int hashcode=0;
char *p;
for(p=str; *p; p++){
hashcode = hashcode*CM_STR_HASHFUNC_CONSTANT + *p;
}
return hashcode;
}
bool IsPrime(int candidate)
{
if ((candidate & 1) != 0)
{
int limit = (int)sqrt((double)candidate);
int divisor;
for (divisor = 3; divisor <= limit; divisor += 2)
{
if ((candidate % divisor) == 0)
return false;
}
return true;
}
return (candidate == 2);
}
int GetPrime(int min)
{
if (min < 0)
return 3;
int i;
int length=sizeof(primes)/sizeof(primes[0]);
for (i = 0; i < length; i++)
{
int prime = primes[i];
if (prime >= min)
return prime;
}
for (int i = (min | 3); i < INT_MAX;i+=2)
{
if (IsPrime(i))
return i;
}
return min;
}
void Initialize(HashDictionary** hd)
{
Initialize(*hd,3);
}
void Initialize(HashDictionary* hd,int capacity)
{
int size=GetPrime(capacity);
hd->buckets=(int*)malloc(sizeof(int)*size);
int i = 0;
for (; i < size; i++)
{
hd->buckets[i]=-1;
}
hd->bucketslength=size;
hd->entrys=(Entry*)malloc(sizeof(Entry)*size);
i = 0;
for (; i < size; i++)
{
hd->entrys[i].hashCode=-1;
hd->entrys[i].next=-1;
hd->entrys[i].value=0;
}
hd->entryslength=size;
hd->count=0;
hd->freeCount=0;
hd->freeList=-1;
};
void Disponse(HashDictionary* hd)
{
free(hd->buckets);
free(hd->entrys);
}
void Resize(HashDictionary* hd)
{
int newsize=hd->count*2;
int* newbuckets=(int*)malloc(sizeof(int)*newsize);
Entry* newentrys=(Entry*)malloc(sizeof(Entry)*newsize);
int i = 0;
for (; i < newsize; i++)
{
newbuckets[i]=-1;
}
for ( i = 0; i < newsize; i++)
{
newentrys[i].hashCode=-1;
newentrys[i].next=-1;
newentrys[i].value=0;
}
hd->bucketslength=hd->entryslength=newsize;
memcpy(newentrys,hd->entrys,sizeof(Entry)*hd->count);
free(hd->buckets);
free(hd->entrys);
hd->buckets=newbuckets;
hd->entrys=newentrys;
//重新排列
for (int i = 0; i < hd->count; i++) {
if (hd->entrys[i].hashCode >= 0) {
int bucket = hd->entrys[i].hashCode % hd->bucketslength;
hd->entrys[i].next = hd->buckets[bucket];
hd->buckets[bucket] = i;
}
}
}
int Insert(HashDictionary* hd,char* key,void* value,bool add)
{
int hashCode = GetHashCode(key) & 0x7FFFFFFF;
int targetBucket = hashCode % hd->bucketslength;
//new value
int i = hd->buckets[targetBucket];
for (i = hd->buckets[targetBucket]; i >= 0; i = hd->entrys[i].next) {
if (hd->entrys[i].hashCode == hashCode && strcmp(hd->entrys[i].key,key)==0) {
if (add) {
return -1;
}
hd->entrys[i].value = value;
return 2;
}
}
int index;
if (hd->freeCount > 0) {
index = hd->freeList;
hd->freeList =hd-> entrys[index].next;
hd->freeCount--;
}
else {
if (hd->count == hd->entryslength)
{
Resize(hd);
targetBucket = hashCode % hd->bucketslength;
}
index = hd->count;
hd->count++;
}
/*if( buckets[targetBucket]!=-1)
printf("碰撞");*/
hd->entrys[index].hashCode = hashCode;
hd->entrys[index].next = hd->buckets[targetBucket];
memcpy(hd->entrys[index].key,key,strlen(key)+1);
hd->entrys[index].value = value;
hd->buckets[targetBucket] = index;
return 1;
}
int FindEntryIndex(HashDictionary* hd,char* key)
{
int hashCode = GetHashCode(key) & 0x7FFFFFFF;
int i = hd->buckets[hashCode % hd->bucketslength];
for (; i >= 0; i = hd->entrys[i].next) {
//printf("%s find item \n",entrys[i].key);
if (hd->entrys[i].hashCode == hashCode && strcmp(hd->entrys[i].key,key)==0)
{
return i;
}
}
return -1;
}
Entry* FindEntry(HashDictionary* hd,char* key)
{
int index=FindEntryIndex(hd,key);
if(index>=0)
{
return &hd->entrys[index];
}
return 0;
}
bool Remove(HashDictionary* hd,char* key)
{
int hashCode = GetHashCode(key) & 0x7FFFFFFF;
int bucket = hashCode % hd->bucketslength;
int last = -1;
for (int i = hd->buckets[bucket]; i >= 0; last = i, i = hd->entrys[i].next) {
if (hd->entrys[i].hashCode == hashCode && strcmp(hd->entrys[i].key,key)==0) {
if (last < 0) {
hd->buckets[bucket] = hd->entrys[i].next;//如果第一个
}
else {
hd->entrys[last].next = hd->entrys[i].next;
}
hd->entrys[i].hashCode = -1;
hd->entrys[i].next = hd->freeList;//串连逻辑删除链表
memset(hd->entrys[i].key,0,20);
hd->entrys[i].value =0;
hd->freeList = i;
hd->freeCount++;
return true;
}
}
return false;
}
bool ContainsKey(HashDictionary* hd,char* key)
{
return FindEntryIndex(hd,key) >= 0;
}
int GetCount(HashDictionary* hd)
{
return hd->count-hd->freeCount;
}
void GetAllKey(HashDictionary* hd,char* allkey)
{
int length=(hd->count-hd->freeCount);
memset(allkey,0,KEYSIZE*length);
int bytelength=KEYSIZE*length;
for (int i = 0; i < hd->entryslength; i++)
{
if(hd->entrys[i].hashCode!=-1)
{
//strcat_s(allkey,bytelength,hd->entrys[i].key);
memcpy_s(allkey+i*KEYSIZE,bytelength,hd->entrys[i].key,KEYSIZE);
}
}
}
测试代码
// testDic.cpp : 定义控制台应用程序的入口点。 // #include "stdafx.h" #include "HashDictionary.h" #include <malloc.h> #include <Windows.h> #include<time.h> int _tmain(int argc, _TCHAR* argv[]) { //dark 89757 HashDictionary* hashdic=(HashDictionary*)malloc(sizeof(HashDictionary)); Initialize(hashdic,3);//3 这个参数是默认数组初始大小,一般设置为=估计有多少条数据,小了也无所谓,是动态增长的 #pragma region 基本操作 Insert(hashdic,"abc","this abc value",true); Insert(hashdic,"12341","this 12341 value~~~~",true); printf("键值对12341是否含有:%d\n",FindEntryIndex(hashdic,"12341")); Remove(hashdic,"12341");//删除 printf("键值对12341是否含有:%d\n",FindEntryIndex(hashdic,"12341")); Insert(hashdic,"name","国人自强不息!",true); Insert(hashdic,"32.252","this abc value",true); printf(" abc: %s \n",FindEntry(hashdic,"abc")->value); Insert(hashdic,"abc","this NEW v~~~~",false);// <-false printf(" abc: %s \n",FindEntry(hashdic,"abc")->value); printf(" name: %s \n",FindEntry(hashdic,"name")->value); int count=GetCount(hashdic); printf("table条数:%d\n",count); char* allkey=(char*)malloc(count*KEYSIZE); GetAllKey(hashdic,allkey);//返回的结果是以KEYSIZE为单位长度的字符集合=》KEYSIZE+KEYSIZE+KEYSIZE+KEYSIZE for (int i = 0; i < count; i++) { printf("key item:%s\n",allkey+i*KEYSIZE);//零食输出 应该是 i*KEYSIZE~(i+1)*KEYSIZE 这段才是一个key } #pragma endregion Entry* find; printf( "---------------------------------------------\n"); #pragma region 删除 插入时间检测 clock_t start, finish; double duration; char* value="这是共有的value~~~~"; start = clock(); int i = 0; char tempkey[20]; for (; i < 1000000; i++) { _itoa_s(i,tempkey,10); if(i==50000){ Insert(hashdic,tempkey,"this debug 5000",true); } Insert(hashdic,tempkey,value,true); } finish = clock(); duration = (double)(finish - start) / CLOCKS_PER_SEC; printf( "插入hashtable 一百万条数:1000000 条! 消费时间: %f seconds\n", duration ); printf("table条数:%d\n",GetCount(hashdic)); Remove(hashdic,"100"); Remove(hashdic,"235"); Remove(hashdic,"888888"); //检测所有插入是否存在 for ( i = 0;i < 1000000; i++) { _itoa_s(i,tempkey,10); find= FindEntry(hashdic,tempkey); if(find==NULL) printf("%s没有找到!!!\n",tempkey); else { //printf( "%s\n", find->value ); 打印100万条很耗时 } } printf( "检查100万完成~\n"); #pragma endregion printf( "---------------------------------------------\n"); start = clock(); char *testkey="50000"; find= FindEntry(hashdic,testkey); printf("指定key查找: key:%s value:%s\n",testkey,find->value); char *testkey2="50001"; find= FindEntry(hashdic,testkey2); printf("指定key查找: key:%s value:%s\n",testkey2,find->value); finish = clock(); duration = (double)(finish - start) / CLOCKS_PER_SEC; printf( "查找两条耗时: %f seconds\n", duration ); printf( "---------------------------------------------\n"); start = clock(); Insert(hashdic,"汉字","this 汉字 的值",true); find= FindEntry(hashdic,"汉字"); printf("指定key查找: key:%s value:%s\n","汉字",find->value); duration = (double)(finish - start) / CLOCKS_PER_SEC; printf( "插入+查找耗时: %f seconds\n", duration ); printf("table条数:%d\n",GetCount(hashdic)); Disponse(hashdic);//malloc -》free system("pause"); return 0; }

demo源码下载 地址1:链接: http://pan.baidu.com/s/1vstEu 密码: y5lq
demo源码下载 地址2:http://bcs.duapp.com/darkweb/testDic.zip