B 树、B+ 树、B* 树
内容源自:
http://blog.csdn.net/v_JULY_v/article/details/6530142
动态查找树主要有:二叉查找树、平衡二叉查找树、红黑树、B树/B树的变形。前三者是典型的二叉查找树结构,其查找的时间复杂度O(logn)与树的深度相关,降低树的深度自然会提高查找效率
在大规模数据存储方面,大量数据存储在外存磁盘中,而在外存磁盘中读取/写入块(block)中某数据时,首先需要定位到磁盘中的某块,如何有效地查找磁盘中的数据,需要一种合理高效的外存数据结构,这就用到了B-tree结构,以及相关变种结构:B+树结构和B*树结构
1. B-树 又叫平衡多路查找树
B树是为了磁盘或者其它存储设备而设计的一种多叉平衡查找树,与红黑树相似,但在降低磁盘I/O操作方面要更好一些。许多数据库系统都一般使用B树或者B树的各种变形结构来存储信息
B树与红黑树最大的不同在于,B树的结点可以有许多子女,从几个到几千个。然而和红黑树一样,一颗含有n个结点的B树的高度也为O(logn),但可能比红黑树的高度小许多,因为它的分支因子比较大。B树可以再O(logn)时间内,实现各种如插入、删除等动态集合操作。
一颗m阶的B树是一颗平衡的m路搜索树,定义如下:
1. 每个非根节点所包含的关键字的个数 j 满足: ┌m/2┐ -1 <= j<=m-1, 所以每个非根节点拥有的子女个数至少为m/2,最多为m
2. 若根节点不是叶子节点那么最少有两个孩子
3. 一个非叶子节点如果包含k-1个关键字,那么就拥有k个孩子节点
4. 所有的叶子节点都在同一层
注意:叶子节点是不存在的节点,每个内部节点中都存储关键字以及指向这些关键字对应数据的指针
因为叶子结点不包含关键字,所以可以把叶子结点看成在树里实际上并不存在外部结点,指向这些外部结点的指针为空,叶子结点的数目正好等于树中所包含的关键字总个数加1
B树的类型和节点定义
#define m 1024
struct BTNode{
int keyNum; //实际关键字个数
PBTNode parent;
PBTNode *ptr; //子树指针向量:ptr[0] ... ptr[keyNum]
KeyType * key; //关键字向量: key[0] … key[keyNum-1]
};
typedef struct BTNode * BTree;
B-树中的一个包含n个关键字,n+1个指针的结点的一般形式为: (n,P0,K1,P1,K2,P2,…,Kn,Pn)
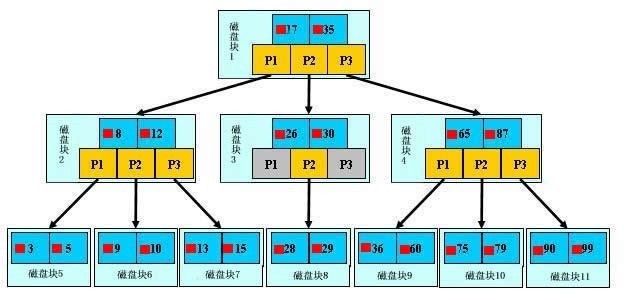
文件查找的具体过程(涉及磁盘IO操作)
为了简单,这里用少量数据构造一棵3叉树的形式,实际应用中的B树结点中关键字很多的。上面的图中比如根结点,其中17表示一个磁盘文件的文件名;小红方块表示这个17文件内容在硬盘中的存储位置;p1表示指向17左子树的指针。
其结构可以简单定义为:
typedef struct {
/*文件数*/
int file_num;
/*文件名(key)*/
char * file_name[max_file_num];
/*指向子节点的指针*/
BTNode * BTptr[max_file_num+1];
/*文件在硬盘中的存储位置*/
FILE_HARD_ADDR offset[max_file_num];
}BTNode;
假如每个盘块可以正好存放一个B树的结点(正好存放2个文件名)。那么一个BTNODE结点就代表一个盘块,而子树指针就是存放另外一个盘块的地址。
下面,咱们来模拟下查找文件29的过程:
-
根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作 1次】
-
此时内存中有两个文件名17、35和三个存储其他磁盘页面地址的数据。根据算法我们发现:17<29<35,因此我们找到指针p2。
-
根据p2指针,我们定位到磁盘块3,并将其中的信息导入内存。【磁盘IO操作 2次】
-
此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现:26<29<30,因此我们找到指针p2。
-
根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作 3次】
-
此时内存中有两个文件名28,29。根据算法我们查找到文件名29,并定位了该文件内存的磁盘地址。
分析上面的过程,发现需要3次磁盘IO操作和3次内存查找操作。关于内存中的文件名查找,由于是一个有序表结构,可以利用折半查找提高效率。至于IO操作是影响整个B树查找效率的决定因素。
B树的高度:
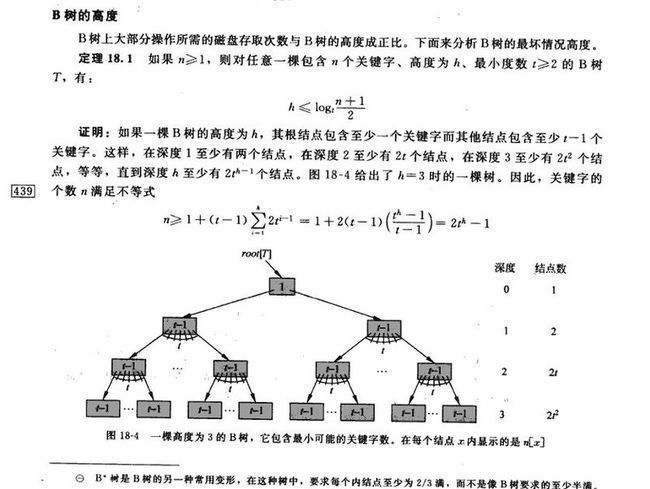
注意:这里计算高度是从0,开始的,实际上它是一颗高度为4的B树
百度百科上对B树的性能分析:
设B-树包含N个关键字,因此有N+1个叶子结点,叶子都在第I层。因为根至少有两个孩子,因此第二层至少有两个结点。除根和叶子外,其它结点至少有┌m/2┐个孩子,因此在第三层至少有2*┌m/2┐个结点,在第四层至少有2*(┌m/2┐^2)个结点,...,在第I层至少有2*(┌m/2┐^(l-2) )个结点,于是有:
N+1 ≥ 2*┌m/2┐I-2
考虑第L层的结点个数为N+1,那么2*(┌m/2┐^(l-2))≤N+1,也就是L层的最少结点数刚好达到N+1个
即: I≤ log┌m/2┐((N+1)/2 )+2
所以,当B-树包含N个关键关键字时,B-树的最大高度为l-1(因为计算B-树高度时,叶结点所在层不计算在内)
即:log┌m/2┐((N+1)/2 )+1
这个公式保证了B-树的查找效率是相当高的
B+-tree:是应文件系统所需而产生的一种B-tree的变形树。
一棵m阶的B+树和m阶的B树的异同点在于:
1. 一个有n-1个关键字的节点有n颗子树
2. 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息)
3. 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)
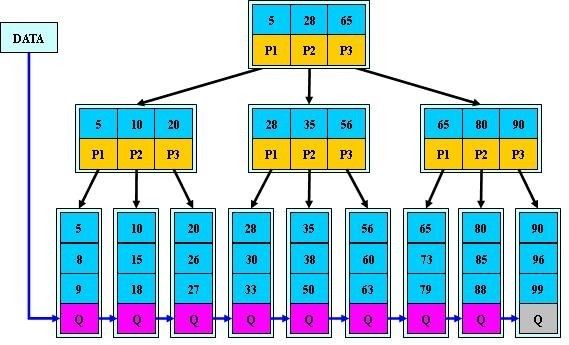
a) 为什么说B+-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
1. B+-tree的磁盘读写代价更低
B+-tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
2. B+-tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
数据库索引采用B+树的主要原因是 B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
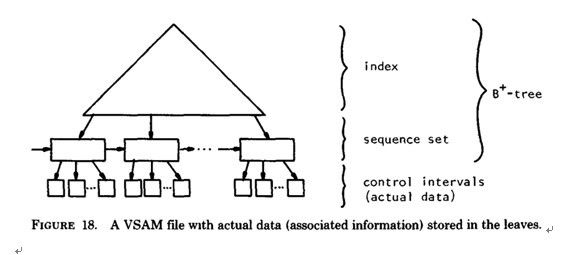
b) B+-tree的应用: VSAM(虚拟存储存取法)文件
B*-tree
B*-tree是B+-tree的变体,在B+树的基础上(所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针),B*树中非根和非叶子结点再增加指向兄弟的指针;B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2)。给出了一个简单实例,如下图所示:
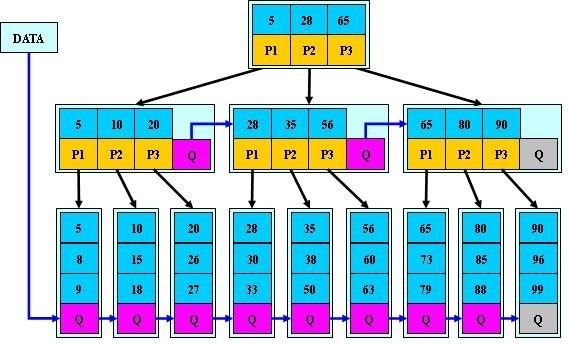
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针。
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;