Learn Beautiful Soup(2)——BeautifulSoup的对象
BeautifulSoup有下列3个对象
- BeautifulSoup
- Tag
- NavigableString
BeautifulSoup对象的创建
创建一个BeautifulSoup对象是任何Beatutiful Soup工程的第一步。
BeatutifulSoup对象的创建可以通过一个字符串或一个类文件对象(可以是一个储存在本地的文件句柄或一个web网页句柄)
用字符串创建BeautifulSoup对象
向构造器中传递一个字符串创建对象,如:helloworld = "<p>Hello World</p>" soup_string = BeautifulSoup(helloworld)
上述创建对象被当做HTML文档处理,可以使用print(soup_string)打印,输出为:
<p>hello world</p> (PS:输出结果与系统有关,有可能为<html><body><p>Helloworld</p></body></html>)
在创建对象过程中,输入被所支持的语法解析器转换为一个树结构体。所以,输入会被当做不同的BeautifulSoup对象(如BeautifulSoup,Tag,NavigableString).
用类文件对象创建BeautifulSoup对象
类文件对象在解析在线网页时非常有用,是BeautifulSoup中最常见的对象。
比如我们要得到一个图书销售网站所有图书列表,此网页为http://www.packtpub.com/books。为了减少过于的访问比如使用字符串来获得网页内容,我们可以使用关于URL的类文件对象来创建BeautifulSoup对象。如:
import urllib2 from bs4 import BeautifulSoup url = "http://www.packtpub.com/books" page = urllib2.urlopen(url) soup_packtpage = BeautifulSoup(page)
urllib2.urlopen()方法由输入的URL返回一个类文件对象,然后以此创建BeautifulSoup对象。
相似的,我们可以为本地文件创建一个文件对象用于构造BeautifulSoup。比如在本地文件Soup中有个foo.html文件,创建BeautifulSoup对象方式如下:
with open("foo.html","r") as foo_file:
soup_foo = BeautifulSoup(foo_file)
BeautifulSoup会有警告如果我们创建对象时传递的是文件名而不是文件对象时,比如:
soup_foo = BeautifulSoup("foo.html")
警告如下:
UserWarning: "foo.html" looks like a filename, not markup. You
should probably open this file and pass the filehandle into
Beautiful Soup.
但是Beautiful仍然会将"foo.html"当做字符串处理。
同样的如果我们传递一个URL代替URL文件对象的话,也会被当做字符串处理。
用XML解析器创建BeautifulSoup对象
当创建一个BeautifulSoup对象时,TreeBuliders类被用于创建HTML/XML树,默认的是使用HTML TreeBuliders对象,使用HTML解析器。如果我们想把输入当做XML做解析,我们必须明确的使用features参数在BeatufulSoup对象构造器中进行说明。指定features参数,我们能够选择最合适的TreeBuliders来满足我们的需求。理解features参数
被不同的TreeBuliders使用的解析器有以下三种:- lxml
- html5lib
- html.parser
features参数可以是字符串列表或者一个字符串。目前每个TreeBuliders和潜在的解析器支持的特性描述如下:
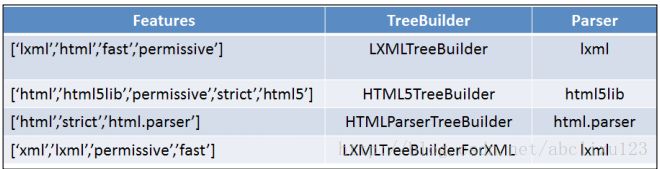
在HTML文档中TreeBuliders的选择是基于解释器创建的优先级。首先是lxml,然后是html5lib,最后是html.parser。比如我们提供html当做features参数。BeautifulSoup会选择LXMLTreeBuilder,如果lxml解析器有效。如果lxml解析器无效,则选择HTML5TreeBulider基于html5lib对象,依次类推。
比如我们可以指定features参数把输入当做XML进行处理:
soup_xml = BeautifulSoup(helloworld,features= "xml")
也可以这样写:
soup_xml = BeautifulSoup(helloworld,"xml")
PS:如果本地没有XML解析器,则会报错。我的电脑就报错了。
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
soup_xml = BeautifulSoup(helloworld, "xml")
File "C:\Python33\lib\site-packages\bs4\__init__.py", line 152, in __init__
% ",".join(features))
bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: xml. Do you need to install a parser library?
建议创建BeautifulSoup对象的时候就指定解析器。因为不同的解析器解析的内容不同。在我们给出一个无效的HTML文档内容时更是如此。
当创建BeautifulSoup对象时,其它对象也会跟着被创建,包括:
- Tag
- NavigableString
Tag
Tag对象代表了HTML和XML文档中不同的标签。当解析这些文档时Tag对象被创建。此对象拥有HTML/XML文档标签的属性和内容,此对象可以用户搜索和定位HTML/XML文档内容。
从Beautifulsoup中获得Tag对象
我们可以与任何标签打交道。比如我们获得一下例子中的第一个<a>标签通过简单的调用标签<a>。
html_atag = """<html><body><p>Test html a tag example</p> <a href="http://www.packtpub.com'>Home</a> <a href="http;//www.packtpub.com/books'>Books</a> </body> </html>""" soup = BeautifulSoup(html_atag,'lxml') atag = soup.a print(atag)
Tag对象可以让我们获得HTML标签相关的名字和属性。
Tag对象的名字
Tag对象的名字通过.name访问
tagname = atag.name print tagname
也可以通过.name更改标签名
atag.name = 'p' print(soup) #output <html><body><p>Test html a tag example</p> <p href="http://www.packtpub.com'>Home</p> <a href="http://www.packtpub.com/books'>Books</a> </body></html>
可以看见<a>变成了<p>
Tag对象的属性
属性给予标签意义和内容。比如标签有类别,ID号和风格。tag的属性可以把Tag对象当作字典来获取。
atag = soup_atag.a print (atag['href'] ) #output http://www.packtpub.com
标签的不同属性都可以通过.attrs来访问。
print(atag.attrs) 将会得到 {'href':' http://www.packtpub.com'}
NavigableString对象
NavigableString对象包含HTML或XML标签中的文字内容。这是一个Python Unicode字符串,用来寻找或导航定位。有时我们会基于当前文本内容定位其他标签或其他文本内容。
获得一个标签储存的文本内容可以通过使用.string访问
first_a_string = soup_atag.string
上诉就创建了一个NavigableString对象,里面是第一个<a>标签中的字符串u'Home'。