Hashtable与ConcurrentHashMap区别
ConcurrentHashMap融合了hashtable和hashmap二者的优势。
hashtable是做了同步的,hashmap未考虑同步。所以hashmap在单线程情况下效率较高。hashtable在的多线程情况下,同步操作能保证程序执行的正确性。
但是hashtable每次同步执行的时候都要锁住整个结构。看下图:
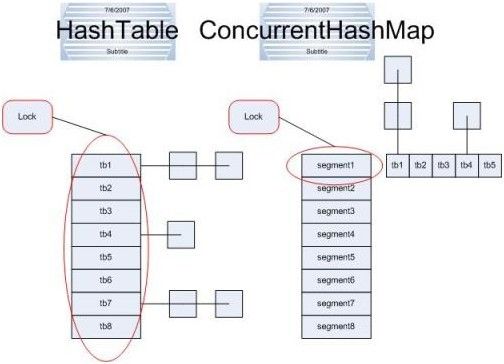
图左侧清晰的标注出来,lock每次都要锁住整个结构。
ConcurrentHashMap正是为了解决这个问题而诞生的。
ConcurrentHashMap锁的方式是稍微细粒度的。 ConcurrentHashMap将hash表分为16个桶(默认值),诸如get,put,remove等常用操作只锁当前需要用到的桶。
试想,原来 只能一个线程进入,现在却能同时16个写线程进入(写线程才需要锁定,而读线程几乎不受限制,之后会提到),并发性的提升是显而易见的。
更令人惊讶的是ConcurrentHashMap的读取并发,因为在读取的大多数时候都没有用到锁定,所以读取操作几乎是完全的并发操作,而写操作锁定的粒度又非常细,比起之前又更加快速(这一点在桶更多时表现得更明显些)。只有在求size等操作时才需要锁定整个表。
而在迭代时,ConcurrentHashMap使用了不同于传统集合的快速失败迭代器的另一种迭代方式,我们称为弱一致迭代器。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出 ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数 据,iterator完成后再将头指针替换为新的数据,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变,更重要的,这保证了多个线程并发执行的连续性和扩展性,是性能提升的关键。
下面分析ConcurrentHashMap的源码。主要是分析其中的Segment。因为操作基本上都是在Segment上的。先看Segment内部数据的定义。
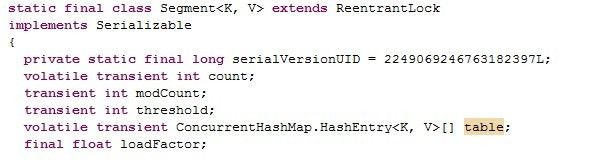
从上图可以看出,很重要的一个是table变量。是一个HashEntry的数组。Segment就是把数据存放在这个数组中的。除了这个量,还有诸如loadfactor、modcount等变量。
看segment的get 函数的实现:

加上hashentry的代码:
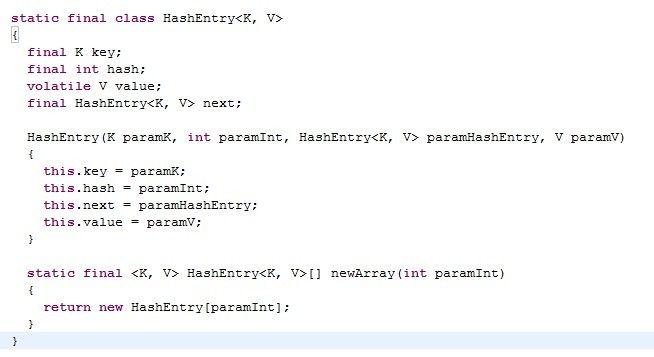
可以看出,hashentry是一个链表型的数据结构。
在segment的get函数中,通过getFirst函数得到第一个值,然后就是通过这个值的next,一路找到想要的那个对象。如果不空,则返回。如果为空,则可能是其他线程正在修改节点。比如上面说的弱一致迭代器在将指针更改为新值的过程。而之前的 get操作都未进行锁定,根据bernstein条件,读后写或写后读都会引起数据的不一致,所以这里要对这个e重新上锁再读一遍,以保证得到的是正确值。readValueUnderLock中就是用了lock()进行加锁。
put操作已开始就锁住了整个segment。这是因为修改操作时不能并发的。
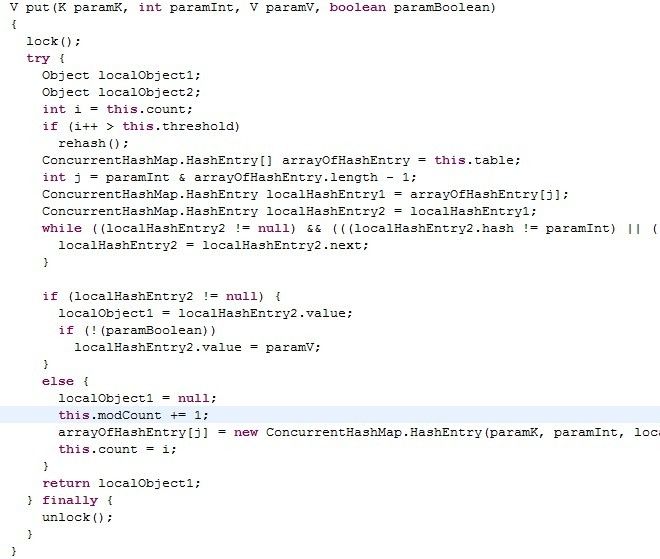
同样,remove操作也是如此(类似put,一开始就锁住真个segment)。
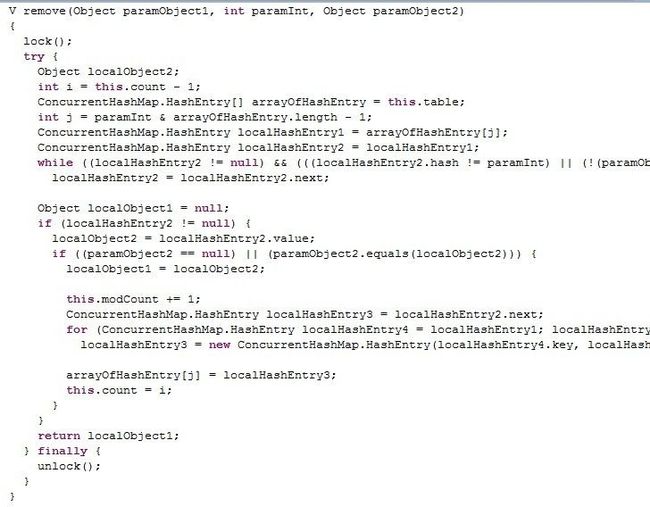
但要注意一点区别,中间那个for循环是做什么用的呢?(截图未完全,可以自己找找代码查看一下)。从代码来看,就是将定位之后的所有entry克隆并拼回前面去,但有必要吗?每次删除一个元素就要将那之前的元素克隆一遍?这点其实是由entry的不变性来决定的,仔细观察entry定义,发现除了value,其他 所有属性都是用final来修饰的,这意味着在第一次设置了next域之后便不能再改变它,取而代之的是将它之前的节点全都克隆一次。至于entry为什么要设置为不变性,这跟不变性的访问不需要同步从而节省时间有关。
文章2:http://www.importnew.com/7010.html
HashMap和Hashtable的区别
HashMap和Hashtable的比较是Java面试中的常见问题,用来考验程序员是否能够正确使用集合类以及是否可以随机应变使用多种思路解决问题。HashMap的工作原理、ArrayList与Vector的比较以及这个问题是有关Java 集合框架的最经典的问题。Hashtable是个过时的集合类,存在于Java API中很久了。在Java 4中被重写了,实现了Map接口,所以自此以后也成了Java集合框架中的一部分。Hashtable和HashMap在Java面试中相当容易被问到,甚至成为了集合框架面试题中最常被考的问题,所以在参加任何Java面试之前,都不要忘了准备这一题。
这篇文章中,我们不仅将会看到HashMap和Hashtable的区别,还将看到它们之间的相似之处。
HashMap和Hashtable的区别
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
要注意的一些重要术语:
1) sychronized意味着在一次仅有一个线程能够更改Hashtable。就是说任何线程要更新Hashtable时要首先获得同步锁,其它线程要等到同步锁被释放之后才能再次获得同步锁更新Hashtable。
2) Fail-safe和iterator迭代器相关。如果某个集合对象创建了Iterator或者ListIterator,然后其它的线程试图“结构上”更改集合对象,将会抛出ConcurrentModificationException异常。但其它线程可以通过set()方法更改集合对象是允许的,因为这并没有从“结构上”更改集合。但是假如已经从结构上进行了更改,再调用set()方法,将会抛出IllegalArgumentException异常。
3) 结构上的更改指的是删除或者插入一个元素,这样会影响到map的结构。
我们能否让HashMap同步?
HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
结论
Hashtable和HashMap有几个主要的不同:线程安全以及速度。仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java 5或以上的话,请使用ConcurrentHashMap吧。