Kafka【系统结构- 要点】- 1 : kafka的分布式 Design Parttern
1:阅读背景:
对于kafka有着基本的了解
2:阅读要点:kafka系统有哪一些的概念?
深刻的理解 topic,partition,broker,consuler,clientid,Consumer Group的关系。
3: 概念说明 :如果你来写一个kafka的日志消息队列?该怎么设计?
3.1 : 最原始:消费者,生产者,消息队列 都只有一个。
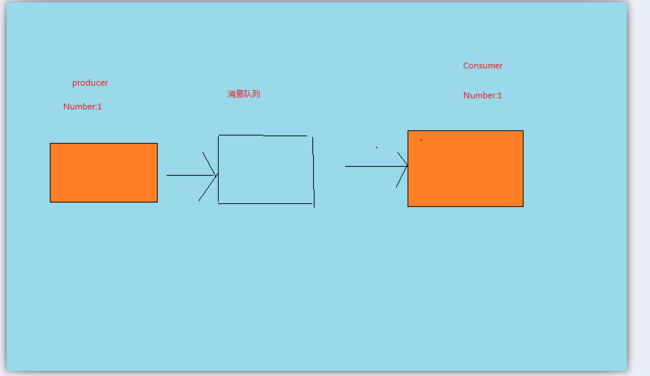
在最初的模型之中,我们只需要一个生产者,一个消费者,消息队列的本质特征只有一个那就是:
容器:
做为容器的队列满足了一下最主要的需求:
3.1:【速度的解耦】: 简单点来说,就是赚钱赚的太多,看客你根本消费不玩,那就先存到Bank里面,这里的银行就是一个容器,对于数据而言,这里就有了三个基本的概念。
3.1.1 : 消费者:producer
3.1.2:生产者:consumer
3.1.3:中间容器:消息队列。
3.2:有时候你传给我的数据,中间经常丢了,那我消费的时候就有了一个新的需求:
HI~ 请给我再传一份数据,可是更多的时候,传给你数据的人根本就不管这些事~,自己传了数据也就不管了。那你没办法,只好 建一个容器来保存这些数据,这个时候,消息队列就有了另外的一个功能需求点【数据持久化】 ,同样我们也有了一个新的概念:
3.1.4:【数据持久化】:只要你传输的数据,我都有这个需求需要保存下来,即便我这边没收到,下次也可以在你那边重新的都到。
3.1.5:最后,你俩建立了这个容器以后,突然发现,这消息队列的这些问题, 都是由于咱们两个没有协商好造成的呀,这个时候,你两就开始整出了另外的一些东西来保证【你发射的数据】和【我接收到的数据】 2者要一样。于是乎,就引入了另外的一些不定义为消息队列,但是能够代替消息队列完成同样功能的组件:比如【Storm】,但是为了解决根本性的矛盾,也就需要另外的一些概念:
1: 滑动窗口的机制
2:数据一致性的保证
什么是滑动窗口?这个不多做解释,简单的来说,就是这样一个组件:他协调了2个人的发射时间,发射的人说,嘿,哥们,我五分钟发射一次,一次发射N*N。 接受的人听到了以后就知道了,你这个哥们在一个时间周期之内能发射多少给我,我看看自己能力,能处理就处理,不能处理咋们再协商,下次你少发一点。 -- 如此 发射处理的两者【速度被解耦了】
什么是一致性? 简单点来说,一致性就是,哥们你给我的数据,发射到我的的集群之中的时候是一致的,类比来说:你给我打的钱在通过银行给我的时候,本来是美元,你不能咿呀给我整个人民币了,并且你给了我100万,我收到的也要是100万。也就是【性质】,【数量】都不能改变。这也就是Storm【Ack回复机制的本源】
一个简单的模型,就是如此了。世界很美好。如果您对于如何写一个 1:1:1的消息队列,请参考本ID的另外一篇博文:
kafka【自己模拟消息队列】-1:简要的模拟
3.2 : ~戮力社会~:消费者,生产者,都有多个,消息队列,都只有一个:
看图说话:
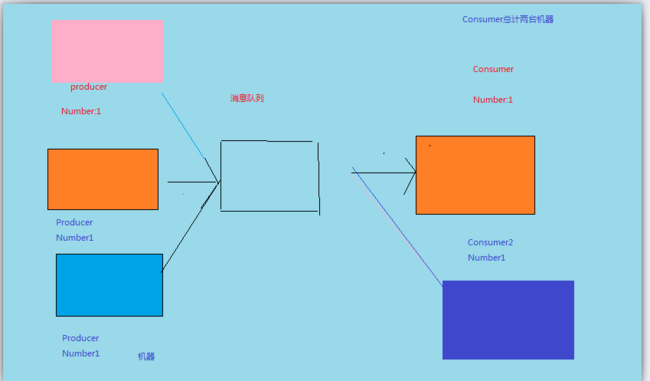
由于第一种方式成功的解决了速度耦合性的问题,也保证了一致性,那自然会吸引更多的人来使用,类比银行而言,
第一个人使用了,就能推广到其他的人,这个时候有了更强的需求点:
1: 容器需要被多个人使用。
2:同样的数据需要被多个人消费。
2.1: 同一份数据被几个人 都拿到
2.2: 同一份的数据被设计用来 几个人共同的来取,在取数据的时候,你们都只取这份数据的一部分。
前者,我们称之为;
【订阅模式】
后者,我们称之为:
【队列模式】
这个时候,业务纷杂以后,生产者就说,既然消费者这么多了,需求有这么复杂,那我们不如这样:咋给你们来分一分组:
【Group】 的概念产生了
消费者被分为了好几组,也就有了Group名称,每一个消费者都被分为了某一个特定的组,分组其实就是分类,分类是人类社会之中最常见的一个现象,这就好比银行之中,你至少属于一个分组:要么你是 VIP,或者 非VIP。有了分组的概念还不行啊。
你还必须要规定分组有什么用啊?每一组有什么功能?既然分组了,那组和组之间有什么区别?组内成员之间有什么区别?
一个电信的类比就是:你银行的VIP 和非VIP有什么区别了? VIP内部成员都去排队又有什么区别了?
Kafka本身也是一个消息队列,在Kafka之中,就有了如下的分组概念:
1: 每一个消费者都属于一个分组,【每一个Consumer都属于一个Group】,也就是【组:消费者】是一个【1:n】的关系,这里N可以为1。
【前提2】 2:发射过来的一条数据【一份】,可以被多个组消费,但是只能够被 每一个组【Group】的一个Consumer消费。
这样的限制带来了如下的分拆:
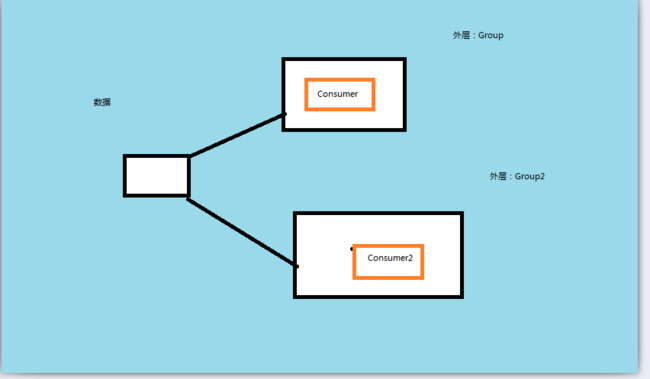
1: 订阅模式:每一个Group都只有一个消费者。由于【前提2】的限制,每一条数据只能被Group的一个Consumer消费。那么N个消费者Group就有了N个消费者,每一个消费者都可以读这份数据。如图所示:
2:队列模式,所有的Consumer拥有同样的一个Group
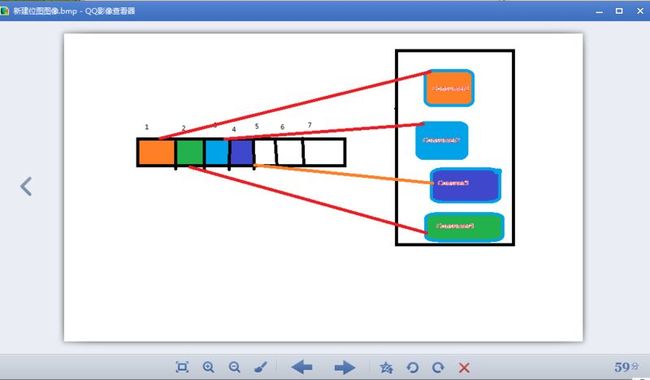
消息 1,2,3,4,这4条日志,在Consumer1,Conusmer2,Consumer3,Consumer4之间负载均衡了,他们都有同样的一个组名:Group1.
到目前为止,基本的矛盾,被我们这个系统的设计解决了,我们能够让多个 Producer不停的生产数据,并且让不同的消费者依据所在的Consumer Group来消费了。
3.3: ~资本社会~:消费者,生产者,都有多个,消息队列,都只有一个,但是消息队列本身进化了。
2014-10-17,10:32:地点:公司
让我们接着做天的博文继续:看图说话:
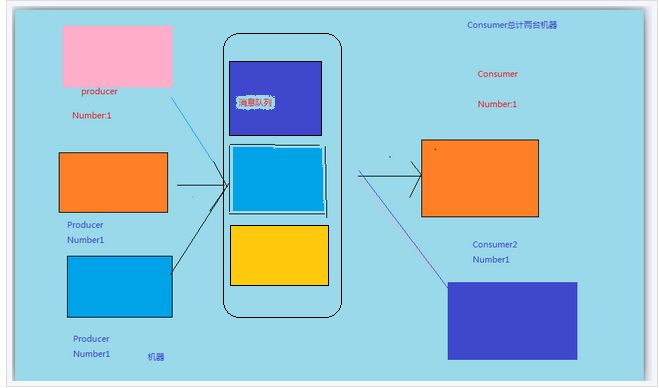
f 到目前为止,我们的真个体系之中,消费者已经是多个了,生产者也是多个了,这个时候,出现了一个新的问题,
这个系统只有一个节点,类比现实世界,这个就好比我们的银行只有一个营业点,一个点关门了,咋们就收不到美金。
计算机世界这样的问题太多了,由此引入了另外一个概念:
”单点“ : 概念和简单,男女老少都能理解的东西,就是只有一个点嘛。 单点的问题,出现了,引入了新的问题,
那与之相对应的就有问题的解决办法。这个时候“集群”的概念就慢慢出现了,由此生长出来了2个最基本的要求:
其一: 为了维持"稳定性", 必须保证整个 消息系统不会因为一个节点 Down掉以后,就停止。
其二: 如果其中一台机器Down掉了,那么我们还可能从其他的机器读取到文件,由此我们的世界引入了另外的一个 概念 "副本",副本的名称代称有很多,有的成为:复制集,有的直接叫Replication。
其三: 在引入了副本之后,由于“副本”这个前提的存在,也就引入了另外的一个问题,在一台机器Down掉以后,我们有能力去其他的机器上去,取得到副本的数据,那么最关键的问题在于,当前我拿到的这台机器上的“副本数据” ,和
已经Down掉的机器上的数据是否一致 --------------> ? ---------- > 这个时候就出现了另外的一个概念,"副本一致性" ,
在Hbase, 在Cassandra等Nosql之中,如何去处理副本的一致性就尤为重要? 在设计整个分布式系统的过程之中,如何去
权衡好【一致性】的问题,都会造成组件在性能,功能之上都会造成较大的分化,在更新一条数据的时候,是否保证其
他的节点能够获得最新的数据?亦或是在接受到数据之后即刻物化到一台节点就算成功?有关[一致性] 问题的讨论,如果您有
兴趣,请移步,并参看本ID的其他博文:《大数据体系【概念认知】系列-1:一致性》的博文。那里将会有一个比较详细的描述。
针对 kafka日志消息队列的设计而言。它做了如下的设计:
其一: kafka 建设了副本的概念,自然而然,也就有了 副本因子的概念。
其二: 副本只是为了满足分布式存储容错的需求,kafka在副本的基础之上提出了【Partition】的概念,也就是【分区】
为什么要有分区?
1 :首先要明白kafka 是如何定义 【partition的】, 每一个分区(Partition) 是一个有序的,不可变的消息队列,这个消息队列可以被连续的追加,在每一个分区的每条消息都一个序列号:这个就是kafka引入的另外一个概念【offset】:也就是我们所说的偏移量。
2 : kafka的分区分布在集群之上的多台机器之上,每一个服务器都会保存这该【分区】,以及消费分区的【记录偏移】
3 :每一个【分区】,都在集群之上拥有多个【副本】。副本的数量是可以配置的。
4 : 副本是为了容错存在的,那么接下来的问题也就出现了。分区有了副本,那么我们对于分区是怎样读取的 ?
每个分区分有一个“leader”的服务器【也就是我们的分区副本所在服务器】,剩下的都是“follower”。leader处理对这个分区的所有读写请求,与此同时,follower会被动地去复制leader上的数据。如果leader发生故障,其中一个follower会自动成为新的leader。每台服务器可以作为一些分区的leader,同时也作为其他一些分区的follower。这样就是一个比较好的负载均衡。
说完了分区的副本,我们再回过头来仔细说说 Partition 内部的构造如何,如下所示:
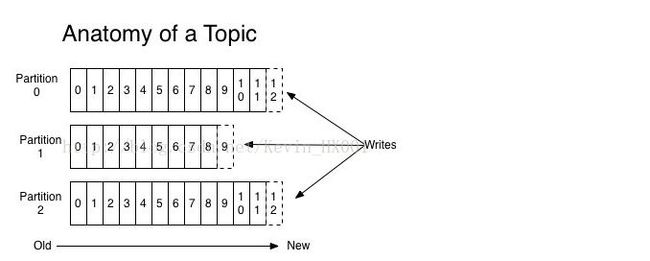
在整个kafka体系下分区的地位如下: 句是这里的Segment:
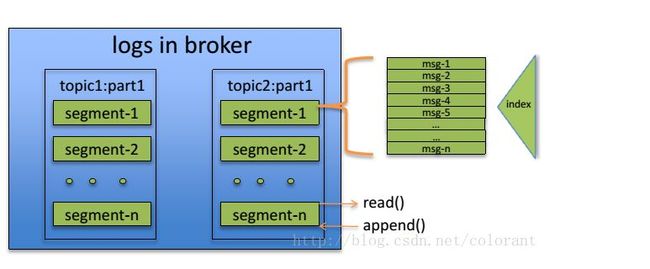
这里我们强点一下kafka分区的属性:
1: segment 内部的构建是一个有序的队列。
2: 每一个独立的Segnment不能够被一个Consumer Group 中超过一个Thread/Process 来处理
3: 不同的Segnment能够被同一个Cousumer所消费
4: 分区的数量在一定程度之上限制了最大的 消费并发数。
到此,kafka是如何设计的主要脉络就已经非常清晰了。
如果您还需要了解更多的细节特性,请参考本ID的另外一篇博文:
Kafka【系统结构- 要点】- 2 : kafka系统设计的细节之道
如果您对kafka 本身有诸多的疑问,还请参考本ID的另外一篇博文
Kafka【系统结构- 要点】- 3: FAQ
--------------------------------------------------- END ---------------------------------------------------