Sizzle引擎--原理与实践(二)
主要流程与正则
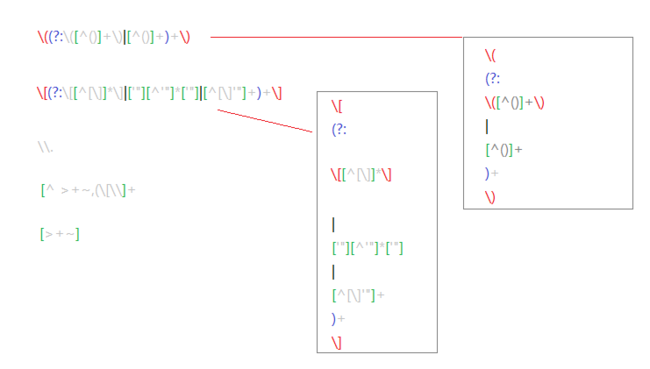
表达式分块
var chunker = /((?:\((?:\([^()]+\)|[^()]+)+\)|\[(?:\[[^[\]]*\]|['"][^'"]*['"]|[^[\]'"]+)+\]|\\.|[^ >+~,(\[\\]+)+|[>+~])(\s*,\s*)?((?:.|\r|\n)*)/g;
这个正则比较长,主要是用来分块和一步预处理。
1、

2、

3、

4、
'div#test + p > a.tab' --> ['div#test','+','p','>','a.tab']
从表达式提取出相应的类型:
这个需要对应jQuery的选择器来看,共7种
ID选择器,CLASS选择器,TAG选择器,ATTR属性选择器,CHILD子元素选择器,PSEUDO伪类选择器,POS位置选择器
判断的方法还是正则,具体正则如下:
ID : /#((?:[\w\u00c0-\uFFFF\-]|\\.)+)/,
CLASS : /\.((?:[\w\u00c0-\uFFFF\-]|\\.)+)/,
NAME : /\[name=['"]*((?:[\w\u00c0-\uFFFF\-]|\\.)+)['"]*\]/,
ATTR : /\[\s*((?:[\w\u00c0-\uFFFF\-]|\\.)+)\s*(?:(\S?=)\s*(?:(['"])(.*?)\3|(#?(?:[\w\u00c0-\uFFFF\-]|\\.)*)|)|)\s*\]/,
TAG : /^((?:[\w\u00c0-\uFFFF\*\-]|\\.)+)/,
CHILD : /:(only|nth|last|first)-child(?:\(\s*(even|odd|(?:[+\-]?\d+|(?:[+\-]?\d*)?n\s*(?:[+\-]\s*\d+)?))\s*\))?/,
POS : /:(nth|eq|gt|lt|first|last|even|odd)(?:\((\d*)\))?(?=[^\-]|$)/,
PSEUDO: /:((?:[\w\u00c0-\uFFFF\-]|\\.)+)(?:\((['"]?)((?:\([^\)]+\)|[^\(\)]*)+)\2\))?/
ID:

CLASS:

NAME:

TAG:

ATTR:

POS:

PSEUDO:
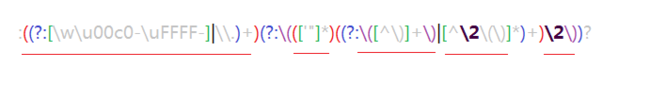
正则小提示:
?非贪婪量词
\3匹配分
?=正向预查
这些正则可能一开始不好看,但是对应到具体的jQuery选择器就比较好理解了:
POS —— :first :nth() :last :gt :lt :even :odd 这些是Sizzle新加的,跟CSS无关
其他的倒是跟CSS基本无异,需要注意的是,由于PSEUDO的存在,同一个表达式可能同时匹配多个类型,这个后面的filter部分会提到。
上面的正则字符串保存在Expr的match属性中,
Expr = {
match:{
//ID:....
}
}
这部分正则并没有直接使用,进行了进一步的处理
第一、每个字符串后面都增加了一个判断,用来确保匹配结果,末尾不包含)或者}
/#((?:[\w\u00c0-\uFFFF\-]|\\.)+))/变成/#((?:[\w\u00c0-\uFFFF\-]|\\.)+)(?![^\[]*\])(?![^\(]*\)/
第二、同时Sizzle会检测转义字符,因此各部分头部都增加了一个捕获组用来保存目标字符串前面的部分,
在这一步的时候,由于在头部增加了一分组,因此原正则字符串中的\3等符号必须顺次后移。
/#((?:[\w\u00c0-\uFFFF\-]|\\.)+)(?![^\[]*\])(?![^\(]*\)/变成
/(^(?:.|\r|\n)*?)#((?:[\w\u00c0-\uFFFF\-]|\\.)+)(?![^\[]*\])(?![^\(]*\)/
/:((?:[\w\u00c0-\uFFFF\-]|\\.)+)(?:\((['"]?)((?:\([^\)]+\)|[^\(\)]*)+)\2\))?/变成
/(^(?:.|\r|\n)*?):((?:[\w\u00c0-\uFFFF\-]|\\.)+)(?:\((['"]?)((?:\([^\)]+\)|[^\(\)]*)+)\3\))?(?![^\[]*\])(?![^\(]*\)/
对应到源码中就是:
var fescape = function(all, num){
return "\\" + (num - 0 + 1);
};
for ( var type in Expr.match ) {
Expr.match[ type ] = new RegExp( Expr.match[ type ].source + (/(?![^\[]*\])(?![^\(]*\))/.source) );
Expr.leftMatch[ type ] = new RegExp( /(^(?:.|\r|\n)*?)/.source + Expr.match[ type ].source.replace(/\\(\d+)/g, fescape) );
}
Expr.leftMatch 中保存的是处理过后的正则部分,这么做的另一个好处就是避免每次匹配都去创建一个新的RegExp对象
回到主流程
函数介绍:
var Sizzle = function( selector, context, results, seed ){}
Sizzle有四个参数:
selector :选择表达式
context :上下文
results :结果集
seed :候选集
实例说明:
Sizzle('div',#test,[#a,#b],[#c,#d,#e])就是在集合[#c,#d,#e]中查找满足条件(在#test范围中并标签名为div)的元素,然后将满足条件的结果存入[#a,#b]中,假设满足条件的有#d,#e,最后获得就是[#a,#b,#d,#e]。
代码示例:
var Sizzle = function( selector, context, results, seed ){
var soFar = selector,
extra ,//extra用来保存并联选择的其他部分,一次只处理一个表达式
parts = [],
m;
do {
chunker.exec( "" ); //这一步主要是将chunker的lastIndex重置,当然直接设置chunker.lastIndex效果也一样
m = chunker.exec( soFar );
if ( m ) {
soFar = m[3];
parts.push( m[1] );
if ( m[2] ) { //如果存在并联选择器,就中断,保存其他的选择器部分。
extra = m[3];
break;
}
}
} while ( m );
}
对于'div#test + p > a.tab'
parts结果就是['div#test','+','p','>','a.tab']
分块之后,下一步就是决定的选择器的顺序,可以对照(一)的说明,构建两个分支:
if ( parts.length > 1 && origPOS.exec( selector ) ) {
//自左向右,判断标准就是存在关系选择符同时有位置选择符,因为如果只是类似div#test的选择表达式,就不存在顺序的问题。
}else{
//其他,自右向左
}
【说明:origPOS保存的是Expr.match.POS,源码901行】
先看普通的(自右向左)情况
然后就是ID的问题,第一个选择表达式含有id就重设context,
当存在context的时候【没有的话就不用找了,因为肯定没结果】,
在重设了contexr之后,既然是自右向左,第一步就是获取等待过滤的集合,
ret = seed ?{ expr: parts.pop(), set: makeArray(seed) } :Sizzle.find( parts.pop(), context);//Sizzle.find负责查找
set = ret.expr ? Sizzle.filter( ret.expr, ret.set ) : ret.set;//Sizzle.filter负责过滤
有候选集seed的时候直接获得候选集,没有的时候获取最右边一个选择符的结果集。
后面的过程就是依次取出parts中的选择符,在set中查找,过滤,直到全部查完
while ( parts.length ) {
Expr.relative[ cur ]( checkSet, context, contextXML );//context代表上下文,并非源码中的参数
}
实例说明:
['div#test','+','p','>','a.tab']处理流程
第一步、没有候选集seed,第一项'div#test'中含有id信息,最后一项'a.tab'中不含有id信息,因此重设content=Sizzle.find('div#test',document)
第二步、剩余部分为['+','p','>','a.tab'],没有候选集seed,先获取等待过滤[标签名为a]的集合A,在集合A中过滤类名为tab的集合B
第三步、剩余部分为['+','p','>'],进行基于关系的过滤,这是一个逆向过程,假设第二步中的B=[#a,#b,#c,#d],先在查找直接父节点是p的元素,获得集合
C = [#a,#b,false,false],然后获取紧挨第一步中content的元素,获得集合D = [#a,false,false,false]
第四步、取得D中不为false的部分,获得此次选择的集合E=[#a];并入结果集result中。
第五步、按照上面的规则,处理并联选择表达式的第二部分。
讨论
关于context的选择
在没有候选集,需要重设ID情况有那些呢?
1、div#id_1 a#id_2
2、div#id_1 a
3、div a#id_2
Sizzle中,只有情况(2)下才去设置context
第二步中、关系选择符“+”和“~”表示的是同层级的关系,因此,context【查找范围】会被设置成context.parentNode
实例说明:
<body>
<div id="test_a">
<p class="tab" id="a1">a1</p>
<p class="tab" id="a1">a2</p>
<p class="tab" id="a1">a3</p>
</div>
<div id="test_b">
<p class="tab" id="b1">b1</p>
<p class="tab" id="b1">b2</p>
<p class="tab" id="b1">b3</p>
</div>
</body>
选择表达式'div#test_a ~ div'
第一步重设context为div#test_a
第二步中如果直接执行(div#test_a).getElemnetsByTagName('div')显然是没有结果的,此时操作根本就是错误的。
因此,应该执行的是(div#test_a).parentNode.getElemnetsByTagName('div').然后再进行第三步。
接下来是Sizzle.find流程分析:《Sizzle引擎--原理与实践(三)》
转载请注明来自小西山子【http://www.cnblogs.com/xesam/】
本文地址:http://www.cnblogs.com/xesam/archive/2012/02/15/2352471.html