Hadoop排序
数据排序是许多实际任务在执行时要完成的第一项工作,比如学生成绩评比、数据建立索引等。
本次实例和数据去重类似,都是先对原始数据进行初步处理,为进一步的数据操作打好基础。
实例描述:
对输入文件中的数据进行排序。输入文件中的每行内容均为一个数字,即一个数据。要求在输出中每行有两个间隔的数字,其中,第二个数字代表原始数据,第一个数字代表这个原始数据在原始数据集中的位次。
样例输入:
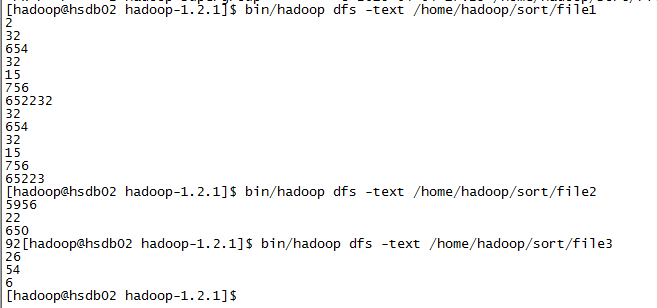
样例输出:
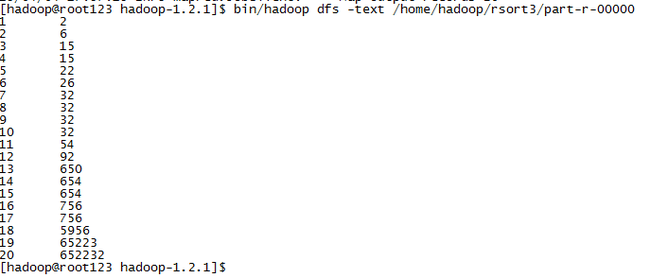
程序代码
以上引自书籍《Hadoop实战》第2版的第五章,不过我去掉了自定义Partition部分代码,从结果来看,输出结果仍是正确(参看上面已有截图),是否仍需要自定义Partition的必要,望大牛们指点!
Partition部分代码
下面的错误信息是因为 partition是从0开始的,默认的返回应该给个0
15/04/06 15:32:40 INFO mapred.JobClient: map 0% reduce 0%
15/04/06 15:36:54 INFO mapred.JobClient: Task Id : attempt_201503291109_0008_m_000002_0, Status : FAILED
java.io.IOException: Illegal partition for 26 (-1)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.collect(MapTask.java:1078)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.write(MapTask.java:690)
at org.apache.hadoop.mapreduce.TaskInputOutputContext.write(TaskInputOutputContext.java:80)
at com.songjy.hadoop.demo.Sort$MyMapper.map(Sort.java:29)
at com.songjy.hadoop.demo.Sort$MyMapper.map(Sort.java:1)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:764)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:364)
at org.apache.hadoop.mapred.Child$4.run(Child.java:255)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190)
at org.apache.hadoop.mapred.Child.main(Child.java:249)
attempt_201503291109_0008_m_000002_0: numPartitions=1
attempt_201503291109_0008_m_000002_0: bound=652233
15/04/06 15:38:11 INFO mapred.JobClient: Task Id : attempt_201503291109_0008_m_000001_0, Status : FAILED
attempt_201503291109_0008_m_000001_0: numPartitions=1
attempt_201503291109_0008_m_000001_0: bound=652233
15/04/06 15:38:24 INFO mapred.JobClient: Task Id : attempt_201503291109_0008_m_000000_0, Status : FAILED
java.io.IOException: Illegal partition for 2 (-1)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.collect(MapTask.java:1078)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.write(MapTask.java:690)
at org.apache.hadoop.mapreduce.TaskInputOutputContext.write(TaskInputOutputContext.java:80)
at com.songjy.hadoop.demo.Sort$MyMapper.map(Sort.java:29)
at com.songjy.hadoop.demo.Sort$MyMapper.map(Sort.java:1)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:764)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:364)
at org.apache.hadoop.mapred.Child$4.run(Child.java:255)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190)
at org.apache.hadoop.mapred.Child.main(Child.java:249)
attempt_201503291109_0008_m_000000_0: numPartitions=1
attempt_201503291109_0008_m_000000_0: bound=652233
15/04/06 15:38:24 INFO mapred.JobClient: Task Id : attempt_201503291109_0008_m_000001_1, Status : FAILED
java.io.IOException: Illegal partition for 5956 (-1)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.collect(MapTask.java:1078)
本次实例和数据去重类似,都是先对原始数据进行初步处理,为进一步的数据操作打好基础。
实例描述:
对输入文件中的数据进行排序。输入文件中的每行内容均为一个数字,即一个数据。要求在输出中每行有两个间隔的数字,其中,第二个数字代表原始数据,第一个数字代表这个原始数据在原始数据集中的位次。
样例输入:
样例输出:
程序代码
package com.songjy.hadoop.demo;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Sort {
public static class MyMapper extends
Mapper<Object, Text, IntWritable, IntWritable> {
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
IntWritable data = new IntWritable(Integer.parseInt(line));
context.write(data, new IntWritable(1));
}
}
public static class MyReducer extends
Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
private static IntWritable linenum = new IntWritable(1);
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
for (IntWritable v : values) {
context.write(linenum, key);
linenum = new IntWritable(linenum.get() + 1);
}
// linenum = new IntWritable(linenum.get() + 1);//代码放在这输出结果是啥样呢?o(∩_∩)o 哈哈
}
}
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.out.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, Sort.class.getName());
job.setJarByClass(Sort.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
//job.setPartitionerClass(MyPartitioner.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
以上引自书籍《Hadoop实战》第2版的第五章,不过我去掉了自定义Partition部分代码,从结果来看,输出结果仍是正确(参看上面已有截图),是否仍需要自定义Partition的必要,望大牛们指点!
Partition部分代码
/**
* 自定义Partitioner函数,此函数根据输入数据的最大值和MapReduce框架中
* Partitioner的数量获取将输入数据按照大小分块的边界,然后根据输入数值和
* 边界的关系返回对应的Partitioner ID
*/
public static class MyPartitioner extends
Partitioner<IntWritable, IntWritable> {
@Override
public int getPartition(IntWritable key, IntWritable value,
int numPartitions) {
System.out.println("numPartitions=" + numPartitions);
int maxnum = 652232;
int bound = maxnum / numPartitions + 1;
System.out.println("bound=" + bound);
int keynum = key.get();
for (int i = 0; i < numPartitions; i++) {
if ((keynum < (bound * i)) && (keynum >= (bound * (i - 1))))
//return i - 1;
return (i - 1) >= 0 ? (i - 1) : 0;//partition是从0开始的,默认的返回应该给个0
}
//return -1;
return 0;//partition是从0开始的,默认的返回应该给个0
}
}
下面的错误信息是因为 partition是从0开始的,默认的返回应该给个0
15/04/06 15:32:40 INFO mapred.JobClient: map 0% reduce 0%
15/04/06 15:36:54 INFO mapred.JobClient: Task Id : attempt_201503291109_0008_m_000002_0, Status : FAILED
java.io.IOException: Illegal partition for 26 (-1)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.collect(MapTask.java:1078)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.write(MapTask.java:690)
at org.apache.hadoop.mapreduce.TaskInputOutputContext.write(TaskInputOutputContext.java:80)
at com.songjy.hadoop.demo.Sort$MyMapper.map(Sort.java:29)
at com.songjy.hadoop.demo.Sort$MyMapper.map(Sort.java:1)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:764)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:364)
at org.apache.hadoop.mapred.Child$4.run(Child.java:255)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190)
at org.apache.hadoop.mapred.Child.main(Child.java:249)
attempt_201503291109_0008_m_000002_0: numPartitions=1
attempt_201503291109_0008_m_000002_0: bound=652233
15/04/06 15:38:11 INFO mapred.JobClient: Task Id : attempt_201503291109_0008_m_000001_0, Status : FAILED
attempt_201503291109_0008_m_000001_0: numPartitions=1
attempt_201503291109_0008_m_000001_0: bound=652233
15/04/06 15:38:24 INFO mapred.JobClient: Task Id : attempt_201503291109_0008_m_000000_0, Status : FAILED
java.io.IOException: Illegal partition for 2 (-1)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.collect(MapTask.java:1078)
at org.apache.hadoop.mapred.MapTask$NewOutputCollector.write(MapTask.java:690)
at org.apache.hadoop.mapreduce.TaskInputOutputContext.write(TaskInputOutputContext.java:80)
at com.songjy.hadoop.demo.Sort$MyMapper.map(Sort.java:29)
at com.songjy.hadoop.demo.Sort$MyMapper.map(Sort.java:1)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:764)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:364)
at org.apache.hadoop.mapred.Child$4.run(Child.java:255)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190)
at org.apache.hadoop.mapred.Child.main(Child.java:249)
attempt_201503291109_0008_m_000000_0: numPartitions=1
attempt_201503291109_0008_m_000000_0: bound=652233
15/04/06 15:38:24 INFO mapred.JobClient: Task Id : attempt_201503291109_0008_m_000001_1, Status : FAILED
java.io.IOException: Illegal partition for 5956 (-1)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.collect(MapTask.java:1078)