由于前面已经把 hadoop 安装并成功配置应用,下面继续对sqoop 安装与配置。
Sqoop是一款开源的工具,主要用于在HADOOP(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
- 安装&配置
下载地址: http://www.us.apache.org/dist/sqoop/1.99.3/
下载 sqoop-1.99.3-bin-hadoop200.tar.gz
解压:tar -zxvf sqoop-1.99.3-bin-hadoop200.tar.gz
配置sqoop环境变量
vi /etc/profile
export SQOOP_HOME=/opt/sqoop-1.99.3-bin-hadoop200
export CATALINA_BASE=$SQOOP_HOME/server
export LOGDIR=$SQOOP_HOME/logs/
export PATH=$SQOOP_HOME/bin:$PATH
修改sqoop关于hadoop共享jar的引用
vi server/conf/catalina.properties
找到common.loader行,把/usr/lib/hadoop/lib/*.jar改成你的hadoop jar 包目录
/opt/soft-228238/hadoop-2.5.2/share/hadoop/yarn/*.jar,
/opt/soft-228238/hadoop-2.5.2/share/hadoop/yarn/lib/*.jar,
/opt/soft-228238/hadoop-2.5.2/share/hadoop/hdfs/*.jar,
/opt/soft-228238/hadoop-2.5.2/share/hadoop/hdfs/lib/*.jar,
/opt/soft-228238/hadoop-2.5.2/share/hadoop/mapreduce/*.jar,
/opt/soft-228238/hadoop-2.5.2/share/hadoop/mapreduce/lib/*.jar,
/opt/soft-228238/hadoop-2.5.2/share/hadoop/common/*.jar,
/opt/soft-228238/hadoop-2.5.2/share/hadoop/common/lib/*.jar,
/opt/soft-228238/hadoop-2.5.2/share/hadoop/httpfs/tomcat/lib/*.jar,
/opt/soft-228238/hadoop-2.5.2/share/hadoop/kms/tomcat/lib/*.jar,
/opt/soft-228238/hadoop-2.5.2/share/hadoop/tools/lib/*.jar
注:/opt/soft-228238/hadoop-2.5.2 安装hadoop 路径;对于和Hive 集成 修改 /usr/lib/hive/lib/*.jar 改为对应到hive 安装路径的 jar
vi server/conf/sqoop.properties
找到:org.apache.sqoop.submission.engine.mapreduce.configuration.directory行,修改值为你的hadoop配置文件目录
如: org.apache.sqoop.submission.engine.mapreduce.configuration.directory=/opt/soft-228238/hadoop-2.5.2/etc/hadoop
进入安装目录:/opt/sqoop-1.99.3-bin-hadoop200
新建文件夹 lib: mkdir lib
将数据库驱动包(oracle-jdbc-10.1.0.2.0.jar)放入到 lib 中,
启动 sqoop:
cd /opt/sqoop-1.99.3-bin-hadoop200/bin
执行 ./sqoop.sh server start
执行结果如下:

停止 sqooq : ./ sqoop.sh server stop
使用sqoop客户端:
./sqoop.sh client

输入help可以查询具体使用方法 如下:
设置服务: set server --host supervisor-84 --port 12000 --webapp sqoop
查看错误信息:set option --name verbose --value true
![]()
查看 sqoop 版本信息:show version –a
创建数据库连接:根据提示依次数据库连接驱动以及用户名密码,然后点击 enter 键,输入连接数 提示 successfully
创建导入 job:
create job --xid 1 --type import
输入 Schema name, Table name 然后 enter(点回撤键) 红框为要输入的信息

执行 start job –jid 6
注: 6 为创建job 的id ,可以通过 show job 命了进行查看 job信息。

成功:

可以在 eclipse hadoop 插件中浏览到结果:
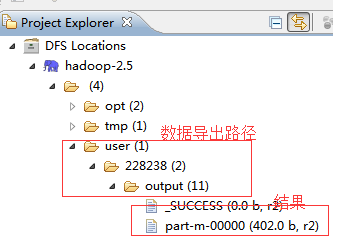
- 遇到问题解决方案:
- 查看 job 运行状态失败:
